values-in-the-wild
收藏Hugging Face2025-04-21 更新2025-04-22 收录
下载链接:
https://huggingface.co/datasets/Anthropic/values-in-the-wild
下载链接
链接失效反馈官方服务:
资源简介:
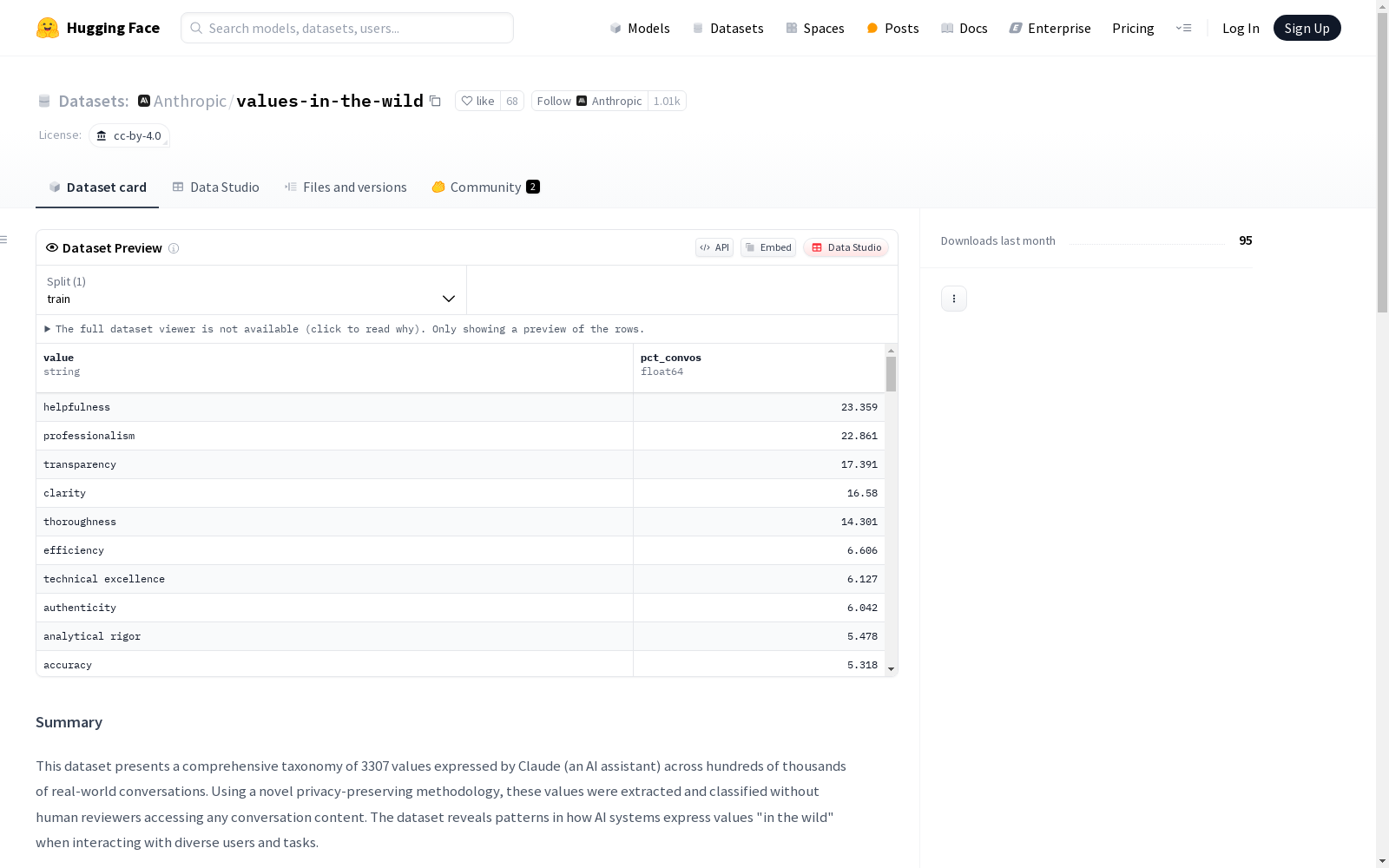
该数据集展示了AI助手Claude在数十万真实世界对话中表达的3307种价值观的全面分类。通过一种新颖的隐私保护方法,这些价值观被提取和分类,而无需人工审查员访问任何对话内容。数据集揭示了AI系统在野外与不同用户和任务交互时表达价值观的模式。
This dataset presents a comprehensive taxonomy of 3,307 values expressed by the AI assistant Claude across hundreds of thousands of real-world conversations. These values are extracted and categorized through a novel privacy-preserving method, without requiring human reviewers to access any conversation content. The dataset reveals patterns of value expression exhibited by AI systems when interacting with diverse users and tasks in the wild.
提供机构:
Anthropic
创建时间:
2025-04-10
搜集汇总
数据集介绍
构建方式
在人工智能伦理研究领域,理解语言模型在真实对话中体现的价值取向具有重要意义。该数据集采用创新的隐私保护方法,通过自动化技术从数十万条真实对话中提取并分类了3307种由Claude人工智能助手表达的价值观念,全程无需人工审阅对话内容。研究人员开发了专门的算法模型,首先识别对话中潜在的价值表达,随后通过层次聚类方法构建了四级分类体系,最终形成包含个体价值及其聚合类别的完整分类学框架。
特点
该数据集展现了人工智能价值表达的实证研究特征,包含两个相互补充的数据文件:values_frequencies.csv精确记录了每个价值在对话样本中的出现频率,精确到小数点后三位;values_tree.csv则通过四级层次结构呈现价值的分类学关系,包含聚类描述、父类关联等元数据。独特的隐私保护设计使得研究大规模真实对话中的价值表达成为可能,同时严格避免了原始对话内容的泄露风险。数据集中价值表达频率的量化方式具有创新性,反映的是AI响应中体现特定价值倾向的概率而非事实准确性。
使用方法
该数据集为跨学科价值研究提供了标准化分析工具。通过HuggingFace数据集库可直接加载数据,Python环境下使用load_dataset方法即可获取结构化数据。values_frequencies文件适用于价值分布频率分析,而values_tree文件支持层次聚类研究。研究人员可结合原始论文中描述的方法论,分析不同层级价值类别的表达模式,或探索特定价值在人类-AI交互中的显现规律。使用时应充分注意数据标注的主观性特征,所有价值标签均由语言模型生成并经过有限的人工验证。
背景与挑战
背景概述
在人工智能与人类交互日益频繁的背景下,理解AI系统在真实对话中表达的价值观念成为人机交互领域的重要研究课题。2023年,Anthropic研究团队推出了values-in-the-wild数据集,通过创新的隐私保护方法,从数十万条真实对话中提取并分类了Claude AI助手表达的3307种价值观念。该数据集采用层次化分类体系,揭示了AI系统在与多样化用户交互过程中价值表达的潜在模式,为人机价值观对齐、AI伦理等跨学科研究提供了实证基础。其创新性的无人工干预数据采集方法,为后续AI价值观研究树立了新的技术标杆。
当前挑战
该数据集面临的核心挑战体现在两个维度:在领域问题层面,AI价值观识别本身具有高度主观性,现有方法难以准确区分价值表达的表层特征与深层语义;同时,跨文化语境下的价值观念多样性给分类体系的普适性带来挑战。在构建过程层面,隐私保护要求导致数据预处理复杂度显著增加,模型生成的价值标签需要严格的质量控制;此外,层次化分类体系的构建依赖语言模型的聚类能力,其解释性与人工评估结果之间存在潜在偏差。这些挑战使得AI价值观的量化研究仍存在方法论上的局限性。
常用场景
经典使用场景
在人工智能伦理与价值对齐研究领域,values-in-the-wild数据集为分析语言模型在真实对话中展现的价值取向提供了实证基础。研究者通过该数据集可系统考察Claude助手在数百万次交互中体现的3307种价值偏好,例如准确性(5.3%出现频率)与助人性等指标的分布规律。这种基于隐私保护方法的价值提取范式,特别适用于研究AI系统在开放域对话场景中无意识流露的价值倾向。
衍生相关工作
基于该数据集衍生的经典研究包括《语言模型价值表达的跨文化分析》等系列论文,它们拓展了原始层次化分类法的应用维度。部分学者将价值聚类结果与道德基础理论相结合,开发出新型价值观评估指标;另有研究通过时序分析追踪模型迭代过程中的价值漂移现象,推动了动态对齐方法的发展。
数据集最近研究
最新研究方向
随着人工智能伦理研究的深入,values-in-the-wild数据集为探索语言模型在真实交互场景中的价值表达机制提供了重要实证基础。当前研究聚焦于三个维度:基于层次聚类的价值表达模式分析揭示了语言模型在认知、伦理和社会层面呈现的潜在偏好分布;结合隐私保护技术的价值提取方法学为敏感数据处理设立了新范式;跨学科价值研究框架的构建则推动了人机交互、心理学与社会学的交叉创新。该数据集发布后迅速成为AI对齐领域的热点工具,特别是在Anthropic发布的Claude系列模型安全评估中发挥了关键作用。2023年多篇顶会论文引用该数据集探讨了生成式AI的价值一致性难题,标志着从理论伦理向可量化评估的重要转向。
以上内容由遇见数据集搜集并总结生成


