ASL Citizen
收藏arXiv2023-06-20 更新2024-06-21 收录
下载链接:
https://www.microsoft.com/en-us/research/project/asl-citizen/
下载链接
链接失效反馈官方服务:
资源简介:
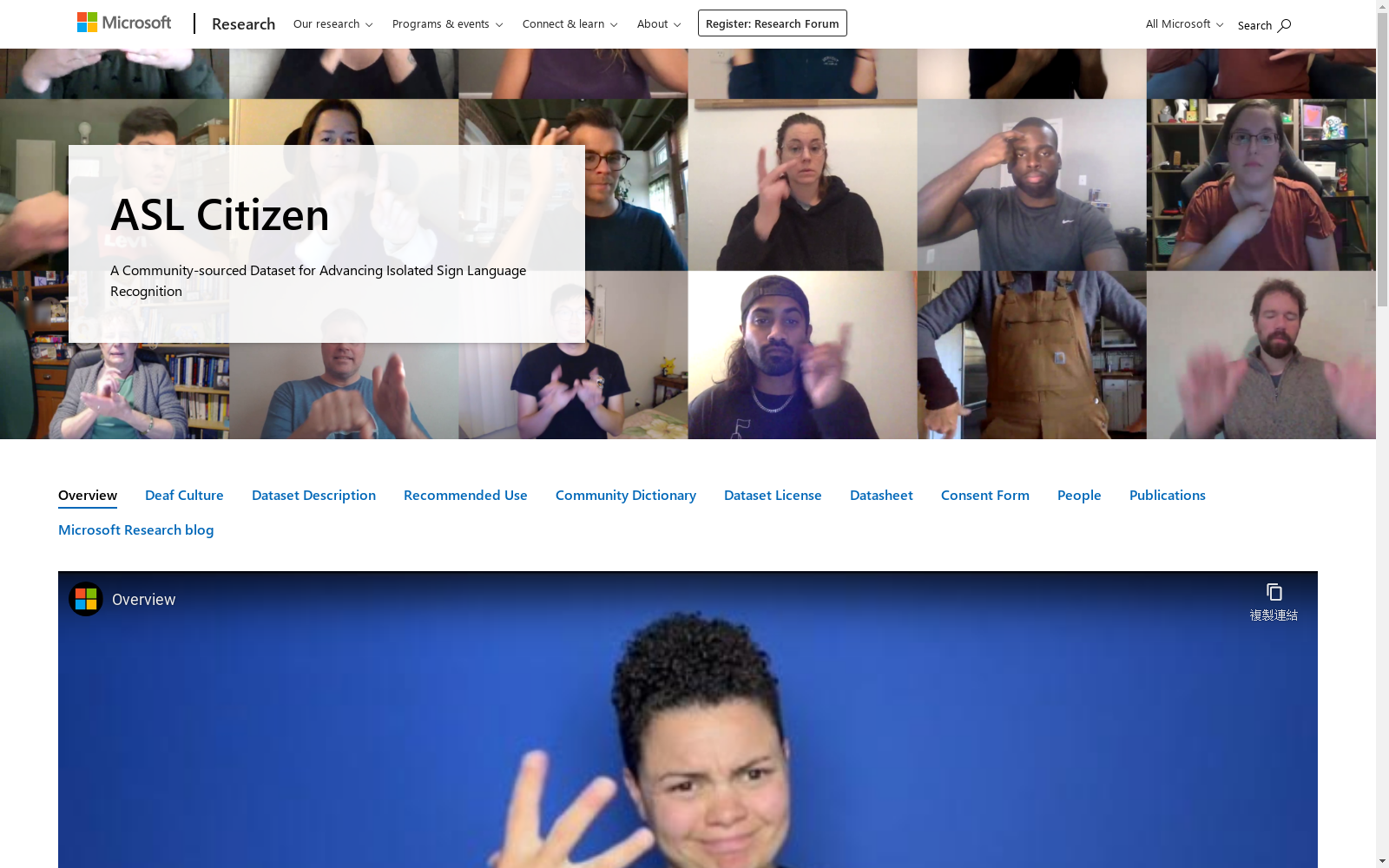
ASL Citizen是由微软研究院与多所大学合作创建的,旨在推进美国手语(ASL)的孤立手势识别研究。该数据集包含83,399个视频,涵盖2,731个不同的手势,由52名手语使用者在多种环境中录制。数据集的创建过程注重参与者的多样性和数据的代表性,确保了高质量和真实性。ASL Citizen主要用于支持ASL字典检索,帮助用户通过视频演示手势来检索字典中的匹配项,从而促进ASL的学习和使用。
ASL Citizen was created by Microsoft Research in collaboration with multiple universities, aiming to advance research on isolated American Sign Language (ASL) gesture recognition. This dataset contains 83,399 videos covering 2,731 distinct gestures, recorded from 52 sign language users across diverse environments. The dataset development prioritizes participant diversity and data representativeness, ensuring high quality and authenticity. Primarily designed to support ASL dictionary retrieval, it helps users retrieve matching dictionary entries via gesture demonstrations in videos, thereby facilitating the learning and practical application of American Sign Language.
提供机构:
微软研究院
创建时间:
2023-04-12
搜集汇总
数据集介绍
构建方式
ASL Citizen数据集通过众包方式构建,旨在解决孤立手语识别(ISLR)问题。该数据集包含83,399个视频,涵盖2,731个不同的手语,由52名手语者在一个多样化的环境中录制。数据集的构建过程中,研究人员与聋人社区紧密合作,确保数据收集的透明性和参与者的知情同意。通过优化众包任务设计,提高了录制效率和数据质量,同时确保了数据的文化敏感性和代表性。
特点
ASL Citizen数据集的主要特点在于其大规模、多样性和高质量。它是首个通过众包方式收集的大规模孤立手语识别数据集,涵盖了广泛的手语词汇和多样化的手语者群体。数据集的录制环境多样,反映了真实世界的使用场景,且所有视频均经过严格的质量控制和隐私保护措施。此外,数据集的构建过程中充分考虑了聋人社区的文化和需求,确保了数据的社会责任性和伦理合规性。
使用方法
ASL Citizen数据集主要用于手语词典检索任务,用户可以通过演示手语视频来检索匹配的手语词条。研究人员可以使用该数据集训练监督学习模型,以提高手语识别的准确性和召回率。数据集提供了标准化的训练、验证和测试集划分,确保模型在未见过的用户上进行评估。此外,数据集还提供了丰富的元数据和标注信息,便于研究人员进行深入分析和模型优化。
背景与挑战
背景概述
ASL Citizen数据集由Aashaka Desai、Lauren Berger、Fyodor O. Minakov等研究人员于2023年创建,旨在推动孤立手语识别(ISLR)技术的发展。该数据集包含了83,399个视频,涵盖2,731种不同的手语,由52名手语使用者在多种环境中录制。ASL Citizen的推出填补了手语识别领域的一个重要空白,特别是为美国手语(ASL)的词典检索提供了丰富的资源。通过社区众包的方式,该数据集不仅规模庞大,而且具有高度的多样性和代表性,为手语识别技术的研究提供了坚实的基础。
当前挑战
ASL Citizen数据集在构建过程中面临了多重挑战。首先,手语识别领域的技术难题在于手语的视觉复杂性和语言多样性,这要求数据集必须具备高度的多样性和代表性。其次,数据集的构建需要确保参与者的隐私和数据质量,这涉及到复杂的伦理和法律问题。此外,手语识别技术的实际应用,如词典检索,需要模型能够在未见过的用户和环境中表现出色,这对模型的泛化能力提出了高要求。最后,手语识别技术的进步还需要克服数据集规模和质量之间的平衡问题,以确保训练出的模型既准确又具有广泛的适用性。
常用场景
经典使用场景
ASL Citizen数据集的经典使用场景主要集中在美式手语(ASL)的词典检索任务中。用户通过摄像头演示一个手势,系统返回与之匹配的手势列表。这一应用场景不仅为手语学习者提供了便捷的查询工具,还为手语词典的构建和维护提供了数据支持。
解决学术问题
ASL Citizen数据集解决了手语识别领域中数据稀缺和多样性不足的问题。通过众包方式收集的大规模、高质量的手语视频数据,显著提升了手语识别模型的性能,特别是在词典检索任务中,实现了63%的准确率和91%的召回率。这为手语识别技术的研究提供了坚实的基础,推动了该领域的发展。
衍生相关工作
ASL Citizen数据集的发布催生了一系列相关研究工作,特别是在手语识别和词典检索领域。研究人员基于该数据集开发了多种深度学习模型,如I3D和ST-GCN,显著提升了手语识别的准确率。此外,该数据集还激发了对众包数据收集方法的研究,探讨如何在保证数据质量和多样性的同时,确保参与者的隐私和权益。
以上内容由遇见数据集搜集并总结生成


