OCID-VLG
收藏github2023-11-09 更新2025-02-19 收录
下载链接:
https://github.com/gtziafas/OCID-VLG
下载链接
链接失效反馈官方服务:
资源简介:
OCID-VLG是由格罗宁根大学、爱丁堡大学和伦敦大学学院联合创建的视觉语言抓取数据集,旨在为复杂场景下的语言引导机器人抓取任务提供基准。该数据集包含1763个高杂乱度的室内桌面RGB-D场景,涵盖31个类别、58个独特实例,提供2D分割掩码、边界框以及4自由度抓取标注。通过对OCID-Grasp数据集的场景图进行解析,生成89,639个独特的语言-掩码-抓取标注元组,支持视觉定位与抓取合成的端到端学习。OCID-VLG的创建过程结合了自动表达式生成技术,确保标注的多样性和准确性。其主要应用于机器人抓取任务,特别是在自然语言指令引导下的复杂室内场景抓取。数据集的发布为机器人视觉语言交互领域提供了宝贵的资源,推动了相关技术的发展。
OCID-VLG is a vision-language grasping dataset jointly developed by the University of Groningen, the University of Edinburgh, and University College London, designed to provide a benchmark for language-guided robotic grasping tasks in complex scenes. This dataset includes 1,763 highly cluttered indoor desktop RGB-D scenes, spanning 31 categories and 58 unique instances, and provides 2D segmentation masks, bounding boxes, and 4-degree-of-freedom grasping annotations. By parsing the scene graphs of the OCID-Grasp dataset, 89,639 distinct language-mask-grasping annotation tuples are generated, enabling end-to-end learning for visual grounding and grasping synthesis. The construction of OCID-VLG integrates automatic expression generation techniques to guarantee the diversity and accuracy of annotations. It is primarily utilized for robotic grasping tasks, especially complex indoor scene grasping guided by natural language instructions. The release of this dataset serves as a valuable resource for the field of robotic vision-language interaction, promoting the advancement of related technologies.
提供机构:
格罗宁根大学、爱丁堡大学和伦敦大学学院
创建时间:
2023-11-09
原始信息汇总
OCID-VLG 数据集概述
数据集简介
OCID-VLG 是一个针对杂乱室内场景的语言引导抓取任务的数据集。该数据集基于 OCID-Grasp,为每个场景提供了一个自然语言表达的参照表达式来唯一描述目标对象,以及对应的抓取矩形框的地面真实值。
数据集构成
- 图像-文本-掩膜-抓取元组:包含 89,639 个图像-文本-掩膜-抓取元组,来自 1763 个独特的 OCID 场景。
- 场景类型:包含多种场景,每个场景包含一个或多个参照表达式和对应的目标对象。
数据集版本
- multiple:随机训练-验证-测试分割(70%-10%-20%),每个分割包含来自 OCID 数据集的独特场景,每个场景有多个针对同一目标对象的参照表达式。
- unique:随机训练-验证-测试分割(70%-10%-20%),每个分割包含来自 OCID 数据集的独特场景,每个场景对每个目标对象只有一个参照表达式。
- novel-instances:测试分割包含针对训练-验证分割中不存在的对象实例的参照表达式。
- novel-classes:测试分割包含针对训练-验证分割中不存在的对象类的参照表达式。
数据加载
使用 OCIDVLGDataset 类从 torch.utils.data.Dataset 加载数据集,支持图像预处理。
数据样本结构
img:场景图像(480, 640, 3)depth:场景深度图像(480, 640)sentence:目标对象的参照表达式target:目标对象标签target_idx:目标对象标签的唯一索引bbox:目标对象的边界框坐标mask:目标对象的像素级分割掩膜grasps:目标对象的抓取矩形框grasp_masks:抓取掩膜,包括位置、质量、角度和宽度
参考文献
@inproceedings{tziafas2023language, title={Language-guided Robot Grasping: CLIP-based Referring Grasp Synthesis in Clutter}, author={Tziafas, Georgios and Yucheng, XU and Goel, Arushi and Kasaei, Mohammadreza and Li, Zhibin and Kasaei, Hamidreza}, booktitle={7th Annual Conference on Robot Learning}, year={2023} }
搜集汇总
数据集介绍
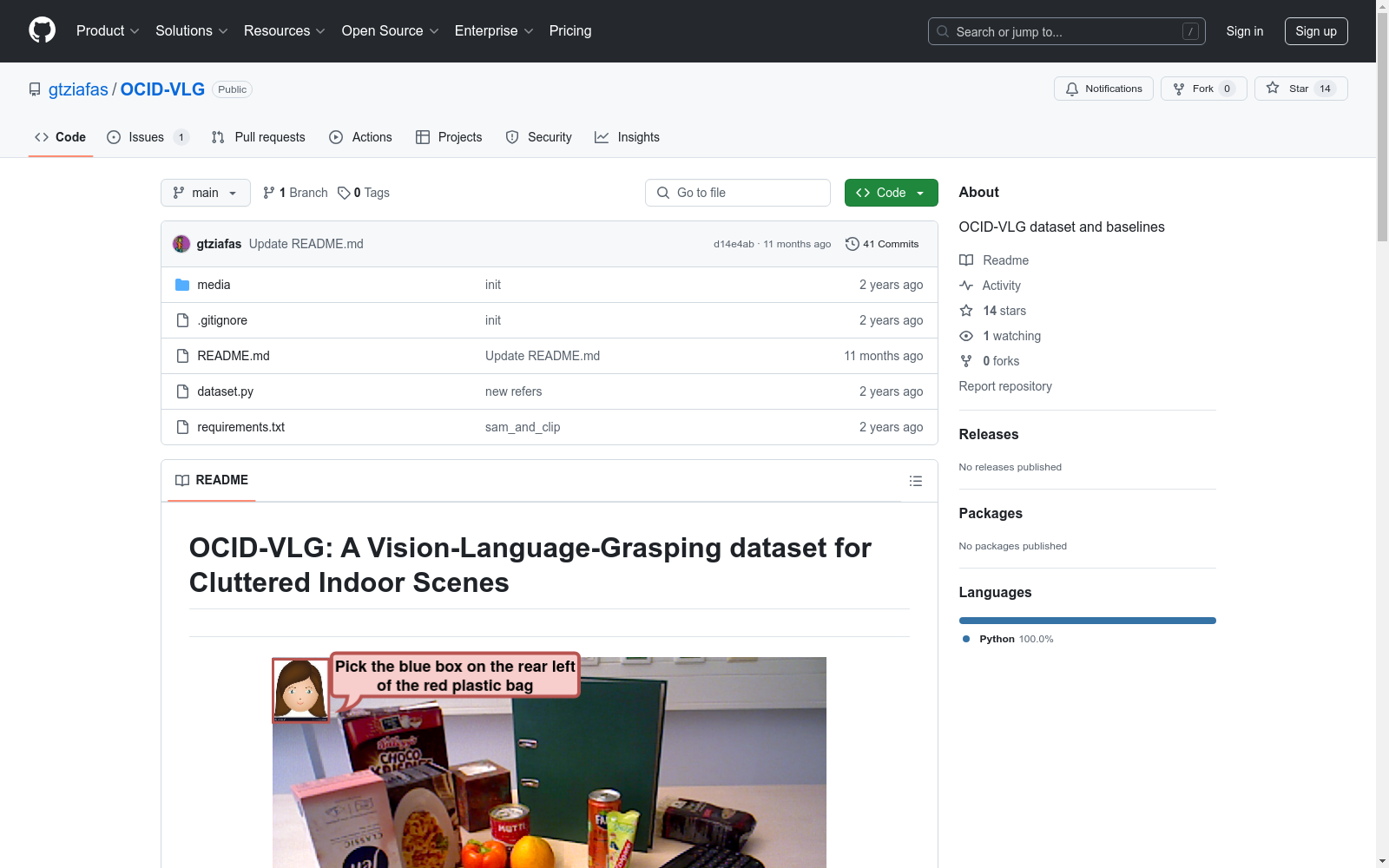
构建方式
OCID-VLG数据集是在OCID-Grasp数据集的基础上构建的,旨在通过自然语言指导下的抓取任务,实现端到端的训练。该数据集在每个场景中提供了一个指向目标对象的自然语言表达式,以及对应的抓取矩形框的地面真实值。数据集的构建融合了图像、文本、掩模和抓取信息,形成了89,639个图像-文本-掩模-抓取元组,源自OCID数据集中的1,763个独特场景。
使用方法
使用OCID-VLG数据集时,用户需首先创建一个Python3虚拟环境并安装必要的依赖。数据集可通过提供的OCIDVLGDataset类加载,该类继承自torch.utils.data.Dataset。用户可以定义图像的预处理转换,并根据需要选择是否包含像素级掩模。数据集API支持通过版本键初始化时选择不同的数据集版本,以适应不同的实验设置。
背景与挑战
背景概述
OCID-VLG数据集,致力于研究自然语言引导下的抓取任务。该数据集的构建基于OCID-Grasp,旨在缩小合成实验室环境与自然家庭场景之间的分布差距,后者通常包含杂乱物品。OCID-VLG数据集的创建,提供了89,639个图像-文本-掩膜-抓取元组,涵盖1763个独特的OCID场景。该数据集的问世,得益于多个研究机构和学者的共同努力,包括OCID、OCID-Grasp和OCID-Ref等前期工作的基础上,为机器人抓取和视觉语言领域的研究提供了新的资源,对相关领域产生了显著影响。
当前挑战
该数据集在解决自然场景下语言引导抓取任务的同时,面临以下挑战:1)如何准确地进行指代图像分割,以识别出自然语言描述的目标对象;2)如何合成精确的抓取矩形框,以实现对目标对象的有效抓取。此外,在构建过程中,数据集需要克服的挑战包括如何处理自然场景的杂乱性,以及如何确保不同场景中目标对象的唯一性描述。在数据集划分上,还需处理新实例和新类别的引入,以评估模型对于未见数据的泛化能力。
常用场景
经典使用场景
在视觉与语言结合的领域,OCID-VLG数据集提供了一个端到端的语言引导抓取任务的研究平台。该数据集通过在自然室内场景中包含的杂乱环境中,提供自然语言描述的目标对象以及相应的抓取矩形框,使得研究者能够在接近现实世界的环境下,进行语言引导的抓取策略学习。
解决学术问题
OCID-VLG数据集解决了传统在合成实验室环境中研究语言引导抓取任务所带来的分布差距问题。通过提供包含真实室内场景的图像、文本、掩膜和抓取信息,该数据集有助于提升模型在自然场景下的泛化能力和鲁棒性,为学术研究提供了新的视角和挑战。
实际应用
实际应用中,OCID-VLG数据集可用于开发智能机器人系统,使机器人在理解自然语言指令后能够准确执行抓取任务,特别是在家居自动化、服务机器人以及工业自动化等领域具有广泛的应用前景。
数据集最近研究
最新研究方向
OCID-VLG数据集致力于研究自然语言引导下的抓取任务,在端到端的模式下进行。该数据集的构建弥补了先前研究多在合成实验室环境中进行,与自然家庭场景存在较大分布差距的不足。OCID-VLG基于OCID-Grasp数据集,为每个场景提供了一种自然语言的参考表达,用以唯一描述目标对象,并伴随真实抓取矩形框。该数据集在引用图像分割和引用抓取合成两个任务上进行了基准测试,为机器人在杂乱室内场景中的抓取任务提供了新的研究方向,对于推动机器人视觉与自然语言处理领域的发展具有重要意义。
以上内容由遇见数据集搜集并总结生成


