ImageInWords
收藏github2024-05-31 收录
下载链接:
https://github.com/google/imageinwords
下载链接
链接失效反馈官方服务:
资源简介:
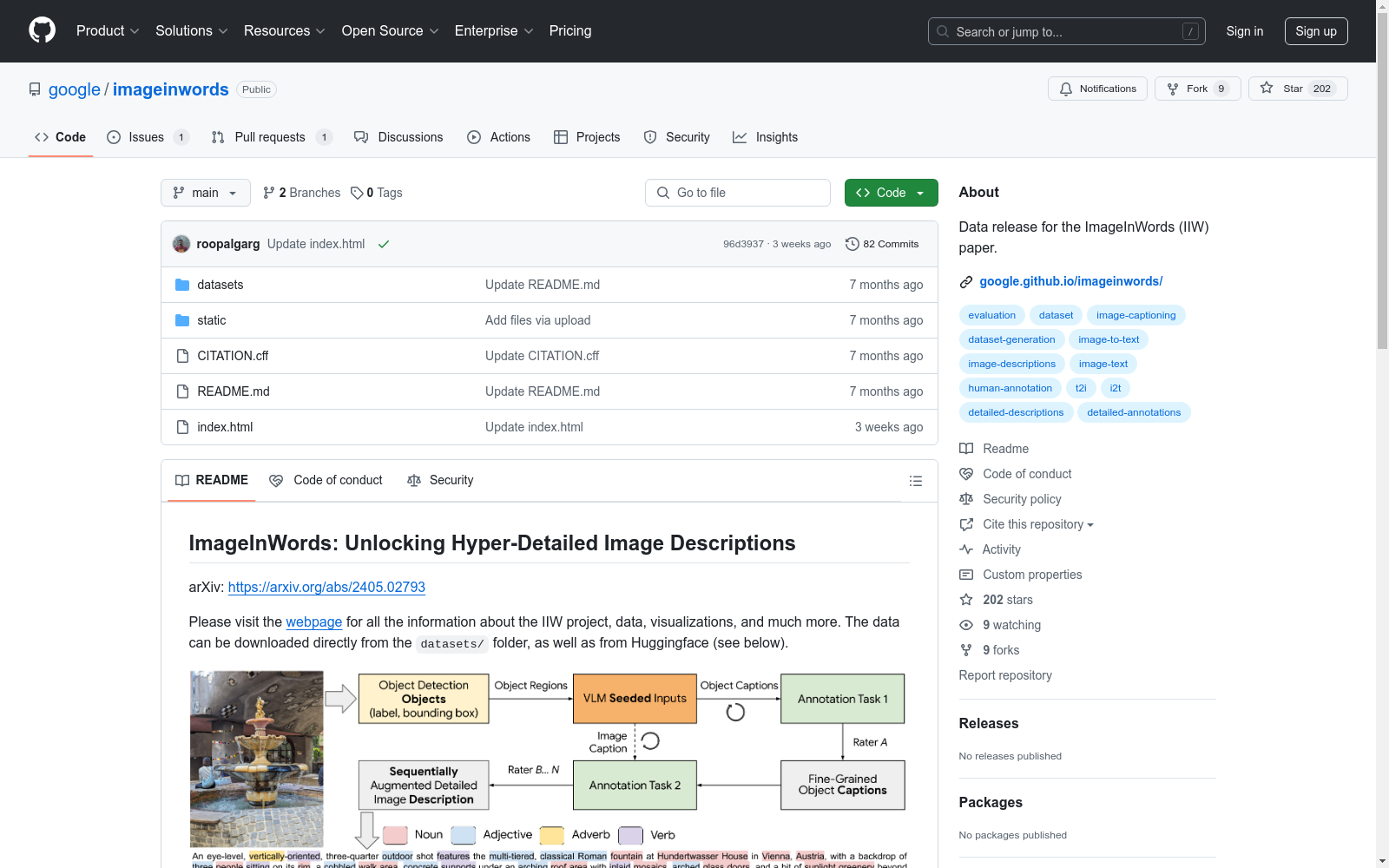
ImageInWords(IIW)数据集,由Google Research与Google DeepMind联合构建,旨在为视觉语言模型的训练提供超详细且无幻觉的图像描述。该数据集包含9018张图片,每张图片均配有详尽的描述,平均每个描述包含9.8个句子、52.5个名词、28个形容词、5个副词和19.1个动词。在创建过程中,IIW采用了迭代式的标注方法,首先通过对象检测器识别图像中的个体对象实例,然后由视觉语言模型生成每个检测到的对象的细粒度标题,作为人工注解过程的起点。随后,通过多轮人工注解和模型微调,逐步丰富和完善描述内容,直至形成一个高质量的数据集。IIW数据集有助于提高文本到图像生成任务的性能,并在视觉-语言组合推理任务中展现了更高的准确性。
The ImageInWords (IIW) dataset, jointly constructed by Google Research and Google DeepMind, aims to provide highly detailed and hallucination-free image descriptions for the training of visual language models. This dataset comprises 9,018 images, each accompanied by an exhaustive description, averaging 9.8 sentences, 52.5 nouns, 28 adjectives, 5 adverbs, and 19.1 verbs per description. During its creation, IIW employed an iterative annotation process, initially using an object detector to identify individual object instances within images, followed by the generation of fine-grained captions for each detected object by a visual language model, serving as the starting point for the manual annotation process. Subsequently, through multiple rounds of manual annotation and model fine-tuning, the descriptions were progressively enriched and refined, culminating in a high-quality dataset. The IIW dataset contributes to enhancing the performance of text-to-image generation tasks and demonstrates higher accuracy in visual-language compositional reasoning tasks.
提供机构:
谷歌
创建时间:
2024-05-05
原始信息汇总
数据集概述
数据集名称
- ImageInWords
数据集描述
- ImageInWords 旨在提供超详细的图像描述。
数据集下载
- 数据可直接从
datasets/文件夹或通过 Hugging Face 下载。
数据集子集
- IIW-400
- DCI_Test
- DOCCI_Test
- CM_3600
- LocNar_Eval
数据集使用
- 使用
datasets库加载数据集,示例代码如下: python from datasets import load_dataset dataset = load_dataset(google/imageinwords, token=None, name="IIW-400", trust_remote_code=True)
数据集许可证
- CC-BY-4.0
数据集引用
-
若使用或引用此数据集,请使用以下引用信息:
@misc{garg2024imageinwords, title={ImageInWords: Unlocking Hyper-Detailed Image Descriptions}, author={Roopal Garg and Andrea Burns and Burcu Karagol Ayan and Yonatan Bitton and Ceslee Montgomery and Yasumasa Onoe and Andrew Bunner and Ranjay Krishna and Jason Baldridge and Radu Soricut}, year={2024}, eprint={2405.02793}, archivePrefix={arXiv}, primaryClass={cs.CV} }
搜集汇总
数据集介绍
构建方式
ImageInWords数据集通过精心设计的流程,结合先进的图像处理技术和自然语言生成模型,构建了高度详细的图像描述。该数据集的构建过程中,首先对大量图像进行深度分析,提取关键视觉特征,随后利用多模态模型将这些特征转化为自然语言描述。通过这种方式,数据集不仅涵盖了图像的基本信息,还提供了丰富的上下文细节,使得每幅图像的描述都极为详尽。
特点
ImageInWords数据集的显著特点在于其描述的细致程度和多模态信息的融合。每条描述不仅包含图像的基本视觉信息,如颜色、形状和物体识别,还深入到场景的情感、氛围和故事背景。此外,数据集的多样性体现在其涵盖了多种场景和主题,从日常生活到专业领域,确保了广泛的应用潜力。
使用方法
使用ImageInWords数据集时,用户可以通过Hugging Face平台直接加载数据,选择不同的子集如IIW-400、DCI_Test等,以满足特定的研究或应用需求。数据集的加载过程简单高效,支持Python编程环境,用户可以轻松集成到现有的机器学习和深度学习项目中。此外,数据集还提供了在线的Dataset-Explorer工具,便于用户进行数据的可视化和初步分析。
背景与挑战
背景概述
ImageInWords数据集由Google团队于2024年推出,旨在通过提供超详细的图像描述来推动计算机视觉与自然语言处理领域的交叉研究。该数据集的核心研究问题是如何生成和理解高度细致的图像描述,这对于提升图像理解算法的精确度和应用范围具有重要意义。主要研究人员包括Roopal Garg、Andrea Burns等,他们通过结合先进的图像处理技术和自然语言生成模型,成功构建了这一数据集。ImageInWords的发布不仅为图像描述生成领域提供了新的基准,还为相关研究提供了丰富的资源和工具,如Hugging Face上的数据集探索器和评估工具。
当前挑战
ImageInWords数据集在构建过程中面临多项挑战。首先,生成超详细的图像描述需要处理大量的图像细节和复杂的语义信息,这对算法的设计和计算资源提出了高要求。其次,确保描述的准确性和多样性是另一大挑战,因为这直接影响到数据集在实际应用中的效用。此外,数据集的构建还需解决图像与文本之间的对齐问题,确保每一条描述都能准确反映图像内容。这些挑战不仅推动了技术的发展,也为未来的研究提供了新的方向和思路。
常用场景
经典使用场景
在计算机视觉领域,ImageInWords数据集以其超详细的图像描述能力而著称,为图像理解与描述任务提供了丰富的资源。该数据集特别适用于图像描述生成、视觉问答(VQA)以及图像与文本的跨模态对齐研究。通过提供高度详细的图像描述,研究者能够训练和评估模型在复杂场景中的表现,从而推动图像理解技术的边界。
实际应用
在实际应用中,ImageInWords数据集被广泛应用于增强现实(AR)、自动驾驶、智能监控等领域。例如,在自动驾驶系统中,该数据集可以帮助车辆更准确地理解周围环境,从而做出更安全的驾驶决策。此外,在智能监控系统中,超详细的图像描述能够帮助识别和分类复杂的场景,提高监控的效率和准确性。
衍生相关工作
基于ImageInWords数据集,研究者们开发了多种先进的图像描述生成模型和跨模态对齐算法。例如,有研究利用该数据集训练了能够生成超详细描述的深度学习模型,显著提升了图像描述的准确性和丰富度。此外,该数据集还激发了关于视觉与语言结合的新研究方向,如多模态学习、图像与文本的联合表示学习等,进一步推动了计算机视觉与自然语言处理领域的交叉研究。
以上内容由遇见数据集搜集并总结生成


