MMIU-Benchmark
收藏数据集卡片 for MMIU
简介
MMIU 包含 7 种类型的多图像关系、52 个任务、77K 张图像和 11K 精心策划的多项选择题,是同类中最广泛的基准。我们对 24 个流行的多模态语言模型(包括开源和专有模型)进行了评估,发现多图像理解存在重大挑战,特别是在涉及空间理解的任务中。即使是如 GPT-4o 这样的最先进模型,在 MMIU 上的准确率也仅为 55.7%。通过多方面的分析实验,我们确定了关键的性能差距和局限性,为未来的模型和数据改进提供了宝贵的见解。我们旨在通过 MMIU 推进 LVLM 研究和开发的边界,使我们更接近实现复杂的多模态多图像用户交互。
数据结构
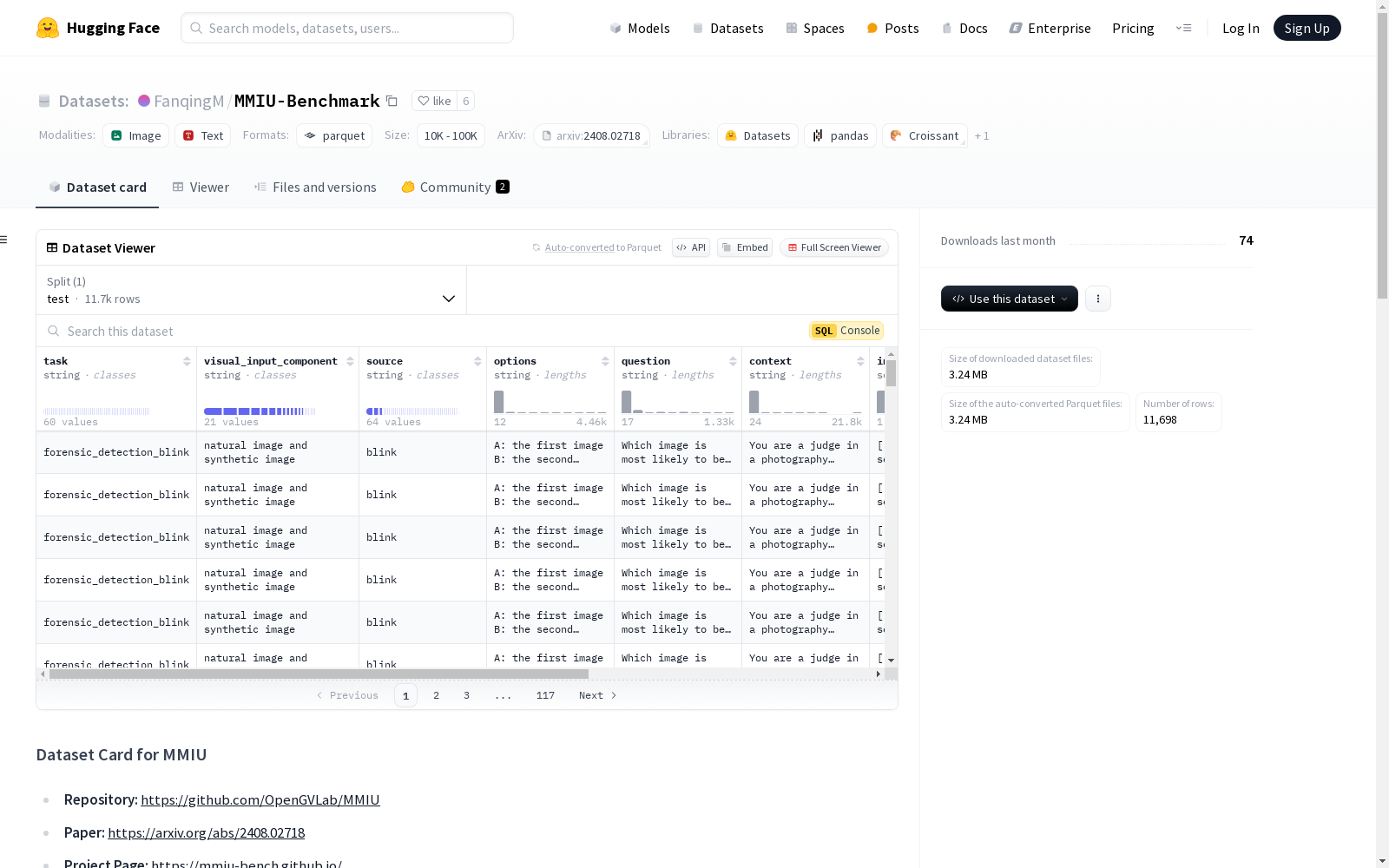
数据字段
每个字段的注释如下:
task: 任务名称visual_input_component: 输入图像的类型(例如,点云、自然图像等)source: 样本的来源数据集options: 问题的选项question: 问题context: 问题的上下文(例如,任务描述等)input_image_path: 输入图像列表(包括问题图像和选项图像)output: 问题的正确选项
示例
json { "task": "forensic_detection_blink", "visual_input_component": "natural image and synthetic image", "source": "blink", "options": "A: the first image B: the second image C: the third image D: the fourth image", "question": "Which image is most likely to be a real photograph?", "context": "You are a judge in a photography competition, and now you are given the four images. Please examine the details and tell which one of them is most likely to be a real photograph. Select from the following choices. A: the first image B: the second image C: the third image D: the fourth image ", "input_image_path": [ "./Low-level-semantic/forensic_detection_blink/forensic_detection_blink_0_0.jpg", "./Low-level-semantic/forensic_detection_blink/forensic_detection_blink_0_1.jpg", "./Low-level-semantic/forensic_detection_blink/forensic_detection_blink_0_2.jpg", "./Low-level-semantic/forensic_detection_blink/forensic_detection_blink_0_3.jpg" ], "output": "D" }
图像关系
我们包括七种类型的图像关系。有关详细信息,请参阅论文:https://arxiv.org/abs/2408.02718
许可信息
本作品采用 <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Creative Commons Attribution 4.0 International License</a> 许可。
免责声明
此数据集主要用于研究目的。我们强烈反对任何有害使用数据或技术的行为。