GoodBaiBai88/M3D-RefSeg
收藏Hugging Face2024-04-25 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/GoodBaiBai88/M3D-RefSeg
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
tags:
- 3D medical
- referring expression segmentation
size_categories:
- n<1K
---
## Dataset Description
3D Medical Image Referring Segmentation Dataset (M3D-RefSeg),
consisting of 210 3D images, 2,778 masks, and text annotations.
### Dataset Introduction
3D medical segmentation is one of the main challenges in medical image analysis. In practical applications,
a more meaningful task is referring segmentation,
where the model can segment the corresponding region based on given text descriptions.
However, referring segmentation requires image-mask-text triplets, and the annotation cost is extremely high,
limiting the development of referring segmentation tasks in 3D medical scenarios.
To address this issue, we selected 210 images as a subset from the existing TotalSegmentator segmentation dataset
and re-annotated the text and corresponding regions.
Each image corresponds to multiple text descriptions of disease abnormalities and region annotations.
Experienced doctors conducted annotations,
with the original text in Chinese stored in the text_zh.txt file.
We used the Qwen 72B large language model for automatic translation,
saving the translated and organized English annotations to text.json.
Furthermore, we used a large language model to convert region description text into question-answer pairs,
saved in CSV files.
For referring expression segmentation code, please refer to [M3D](https://github.com/BAAI-DCAI/M3D).
### Supported Tasks
The data in this dataset can be represented in the form of image-mask-text,
where masks can be converted into box coordinates through bounding boxes.
Supported tasks include:
- **3D Segmentation**: Text-guided segmentation, referring segmentation, inference segmentation, etc.
- **3D Positioning** Visual grounding/referring expression comprehension, referring expression generation.
## Dataset Format and Structure
### Data Format
<pre>
M3D_RefSeg/
s0000/
ct.nii.gz
mask.nii.gz
text.json
text_zh.txt
s0000/
......
</pre>
### Dataset Download
#### Clone with HTTP
```bash
git clone https://huggingface.co/datasets/GoodBaiBai88/M3D-RefSeg
```
#### SDK Download
```bash
from datasets import load_dataset
dataset = load_dataset("GoodBaiBai88/M3D-RefSeg")
```
#### Manual Download
Download the files directly from the dataset repository.
### Dataset Loading Method
#### 1. Preprocessing
After downloading the dataset, it needs to be processed using m3d_refseg_data_prepare.py,
including converting to a unified `npy` format, normalization, cropping, etc.
#### 2. Build Dataset
We provide an example code for constructing the Dataset.
```python
class RefSegDataset(Dataset):
def __init__(self, args, tokenizer, mode="train"):
self.args = args
self.tokenizer = tokenizer
self.mode = mode
self.image_tokens = "<im_patch>" * args.proj_out_num
train_transform = mtf.Compose(
[
mtf.RandRotate90d(keys=["image", "seg"], prob=0.5, spatial_axes=(1, 2)),
mtf.RandFlipd(keys=["image", "seg"], prob=0.10, spatial_axis=0),
mtf.RandFlipd(keys=["image", "seg"], prob=0.10, spatial_axis=1),
mtf.RandFlipd(keys=["image", "seg"], prob=0.10, spatial_axis=2),
mtf.RandScaleIntensityd(keys="image", factors=0.1, prob=0.5),
mtf.RandShiftIntensityd(keys="image", offsets=0.1, prob=0.5),
mtf.ToTensord(keys=["image"], dtype=torch.float),
mtf.ToTensord(keys=["seg"], dtype=torch.int),
]
)
val_transform = mtf.Compose(
[
mtf.ToTensord(keys=["image"], dtype=torch.float),
mtf.ToTensord(keys=["seg"], dtype=torch.int),
]
)
set_track_meta(False)
if mode == 'train':
self.data_list = pd.read_csv(args.refseg_data_train_path, engine='python')
self.transform = train_transform
elif mode == 'validation':
self.data_list = pd.read_csv(args.refseg_data_test_path, engine='python')
self.transform = val_transform
elif mode == 'test':
self.data_list = pd.read_csv(args.refseg_data_test_path, engine='python')
self.transform = val_transform
def __len__(self):
return len(self.data_list)
def __getitem__(self, idx):
max_attempts = 100
for _ in range(max_attempts):
try:
data = self.data_list.iloc[idx]
image_path = os.path.join(self.args.data_root, data["Image"])
image_array = np.load(image_path) # 1*32*256*256, normalized
seg_path = os.path.join(self.args.data_root, data["Mask"])
seg_array = np.load(seg_path)
seg_array = (seg_array == data["Mask_ID"]).astype(np.int8)
item = {
"image": image_array,
"seg": seg_array,
}
it = self.transform(item)
image = it['image']
seg = it['seg'] # C*D*H*W
question = data["Question"]
question = self.image_tokens + ' ' + question
answer = data["Answer"]
self.tokenizer.padding_side = "right"
text_tensor = self.tokenizer(
question + ' ' + answer, max_length=self.args.max_length, truncation=True, padding="max_length", return_tensors="pt"
)
input_id = text_tensor["input_ids"][0]
attention_mask = text_tensor["attention_mask"][0]
valid_len = torch.sum(attention_mask)
if valid_len < len(input_id):
input_id[valid_len] = self.tokenizer.eos_token_id
question_tensor = self.tokenizer(
question, max_length=self.args.max_length, truncation=True, padding="max_length", return_tensors="pt"
)
question_len = torch.sum(question_tensor["attention_mask"][0])
label = input_id.clone()
label[label == self.tokenizer.pad_token_id] = -100
label[:question_len] = -100
ret = {
'image': image,
'input_id': input_id,
'label': label,
'seg': seg,
'attention_mask': attention_mask,
'question': question,
'answer': answer,
'question_type': "refseg",
}
return ret
except Exception as e:
print(f"Error in __getitem__ at index {idx}: {e}")
idx = random.randint(0, len(self.data_list) - 1)
```
### Data Splitting
The dataset is divided by CSV files into:
- Training set: M3D_RefSeg_train.csv
- Test set: M3D_RefSeg_test.csv
### Dataset Sources
This dataset is created from the open-source [TotalSegmentator](https://github.com/wasserth/TotalSegmentator).
For detailed information, please refer to TotalSegmentator.
## Dataset Copyright Information
All data involved in this dataset are publicly available.
## Citation
If our dataset and project are helpful to you, please cite the following work:
```BibTeX
@misc{bai2024m3d,
title={M3D: Advancing 3D Medical Image Analysis with Multi-Modal Large Language Models},
author={Fan Bai and Yuxin Du and Tiejun Huang and Max Q. -H. Meng and Bo Zhao},
year={2024},
eprint={2404.00578},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{du2024segvol,
title={SegVol: Universal and Interactive Volumetric Medical Image Segmentation},
author={Yuxin Du and Fan Bai and Tiejun Huang and Bo Zhao},
year={2024},
eprint={2311.13385},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
许可证:Apache-2.0
标签:
- 3D医学
- 指代表分割(referring expression segmentation)
样本规模类别:
- n<1K
---
## 数据集描述
3D医学图像指代表分割数据集(M3D-RefSeg),包含210张3D图像、2778个掩码以及文本标注。
### 数据集简介
3D医学分割是医学图像分析领域的核心挑战之一。在实际应用场景中,更具实用价值的任务为指代表分割——即模型可根据给定的文本描述分割出对应区域。然而,指代表分割任务依赖图像-掩码-文本三元组数据,标注成本极其高昂,这限制了3D医学场景下指代表分割任务的发展。为解决该问题,我们从现有TotalSegmentator分割数据集中选取210张图像作为子集,并重新标注文本与对应区域。每张图像对应多条病变异常的文本描述与区域标注。标注工作由资深医师完成,原始中文文本存储于text_zh.txt文件中。我们使用通义千问72B大语言模型(Qwen 72B LLM)进行自动翻译,将整理后的英文标注保存至text.json文件。此外,我们还借助大语言模型将区域描述文本转换为问答对,存储于CSV文件中。关于指代表分割的代码实现,请参考[M3D](https://github.com/BAAI-DCAI/M3D)。
### 支持任务
本数据集的数据可表示为图像-掩码-文本的三元组形式,掩码可通过边界框转换为边界框坐标。支持的任务包括:
- **3D分割**:文本引导分割、指代表分割、推理式分割等
- **3D定位**:视觉接地/指代表理解、指代表生成。
## 数据集格式与结构
### 数据格式
<pre>
M3D_RefSeg/
s0000/
ct.nii.gz
mask.nii.gz
text.json
text_zh.txt
s0000/
......
</pre>
### 数据集下载
#### HTTP克隆
bash
git clone https://huggingface.co/datasets/GoodBaiBai88/M3D-RefSeg
#### SDK下载
bash
from datasets import load_dataset
dataset = load_dataset("GoodBaiBai88/M3D-RefSeg")
#### 手动下载
直接从数据集仓库下载文件。
### 数据集加载方法
#### 1. 预处理
下载完成数据集后,需使用m3d_refseg_data_prepare.py进行预处理,包括转换为统一的`.npy`格式、归一化、裁剪等操作。
#### 2. 构建数据集
我们提供了构建数据集的示例代码。
python
class RefSegDataset(Dataset):
def __init__(self, args, tokenizer, mode="train"):
self.args = args
self.tokenizer = tokenizer
self.mode = mode
self.image_tokens = "<im_patch>" * args.proj_out_num
train_transform = mtf.Compose(
[
mtf.RandRotate90d(keys=["image", "seg"], prob=0.5, spatial_axes=(1, 2)),
mtf.RandFlipd(keys=["image", "seg"], prob=0.10, spatial_axis=0),
mtf.RandFlipd(keys=["image", "seg"], prob=0.10, spatial_axis=1),
mtf.RandFlipd(keys=["image", "seg"], prob=0.10, spatial_axis=2),
mtf.RandScaleIntensityd(keys="image", factors=0.1, prob=0.5),
mtf.RandShiftIntensityd(keys="image", offsets=0.1, prob=0.5),
mtf.ToTensord(keys=["image"], dtype=torch.float),
mtf.ToTensord(keys=["seg"], dtype=torch.int),
]
)
val_transform = mtf.Compose(
[
mtf.ToTensord(keys=["image"], dtype=torch.float),
mtf.ToTensord(keys=["seg"], dtype=torch.int),
]
)
set_track_meta(False)
if mode == 'train':
self.data_list = pd.read_csv(args.refseg_data_train_path, engine='python')
self.transform = train_transform
elif mode == 'validation':
self.data_list = pd.read_csv(args.refseg_data_test_path, engine='python')
self.transform = val_transform
elif mode == 'test':
self.data_list = pd.read_csv(args.refseg_data_test_path, engine='python')
self.transform = val_transform
def __len__(self):
return len(self.data_list)
def __getitem__(self, idx):
max_attempts = 100
for _ in range(max_attempts):
try:
data = self.data_list.iloc[idx]
image_path = os.path.join(self.args.data_root, data["Image"])
image_array = np.load(image_path) # 形状为1×32×256×256,已完成归一化
seg_path = os.path.join(self.args.data_root, data["Mask"])
seg_array = np.load(seg_path)
seg_array = (seg_array == data["Mask_ID"]).astype(np.int8)
item = {
"image": image_array,
"seg": seg_array,
}
it = self.transform(item)
image = it['image']
seg = it['seg'] # 通道数×深度×高度×宽度
question = data["Question"]
question = self.image_tokens + ' ' + question
answer = data["Answer"]
self.tokenizer.padding_side = "right"
text_tensor = self.tokenizer(
question + ' ' + answer, max_length=self.args.max_length, truncation=True, padding="max_length", return_tensors="pt"
)
input_id = text_tensor["input_ids"][0]
attention_mask = text_tensor["attention_mask"][0]
valid_len = torch.sum(attention_mask)
if valid_len < len(input_id):
input_id[valid_len] = self.tokenizer.eos_token_id
question_tensor = self.tokenizer(
question, max_length=self.args.max_length, truncation=True, padding="max_length", return_tensors="pt"
)
question_len = torch.sum(question_tensor["attention_mask"][0])
label = input_id.clone()
label[label == self.tokenizer.pad_token_id] = -100
label[:question_len] = -100
ret = {
'image': image,
'input_id': input_id,
'label': label,
'seg': seg,
'attention_mask': attention_mask,
'question': question,
'answer': answer,
'question_type': "refseg",
}
return ret
except Exception as e:
print(f"Error in __getitem__ at index {idx}: {e}")
idx = random.randint(0, len(self.data_list) - 1)
### 数据划分
本数据集通过CSV文件划分为:
- 训练集:M3D_RefSeg_train.csv
- 测试集:M3D_RefSeg_test.csv
### 数据集来源
本数据集基于开源项目[TotalSegmentator](https://github.com/wasserth/TotalSegmentator)构建,详细信息请参考TotalSegmentator项目。
## 数据集版权声明
本数据集涉及的所有数据均为公开可用数据。
## 引用声明
若本数据集与项目对您的工作有所帮助,请引用以下文献:
BibTeX
@misc{bai2024m3d,
title={M3D: Advancing 3D Medical Image Analysis with Multi-Modal Large Language Models},
author={Fan Bai and Yuxin Du and Tiejun Huang and Max Q. -H. Meng and Bo Zhao},
year={2024},
eprint={2404.00578},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{du2024segvol,
title={SegVol: Universal and Interactive Volumetric Medical Image Segmentation},
author={Yuxin Du and Fan Bai and Tiejun Huang and Bo Zhao},
year={2024},
eprint={2311.13385},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
提供机构:
GoodBaiBai88
原始信息汇总
数据集概述
数据集名称
3D Medical Image Referring Segmentation Dataset (M3D-RefSeg)
数据集内容
- 图像数量: 210 3D图像
- 掩码数量: 2,778 掩码
- 文本注释: 包含疾病异常和区域注释的文本描述,原始中文文本存储于
text_zh.txt,英文注释存储于text.json。
数据集特点
- 任务类型: 支持3D分割和3D定位任务,包括文本引导分割、推理分割、视觉定位等。
- 数据格式: 数据集以
nii.gz格式存储图像和掩码,文本注释以JSON和TXT格式存储。
数据集结构
M3D_RefSeg/ s0000/ ct.nii.gz mask.nii.gz text.json text_zh.txt ...
数据集下载与加载
- 下载方式: 支持通过Git克隆、SDK加载或手动下载。
- 加载方法: 需使用
m3d_refseg_data_prepare.py进行预处理,包括格式转换、归一化、裁剪等。
数据集分割
- 训练集: M3D_RefSeg_train.csv
- 测试集: M3D_RefSeg_test.csv
数据集来源
基于开源项目TotalSegmentator创建。
许可证
Apache-2.0
搜集汇总
数据集介绍
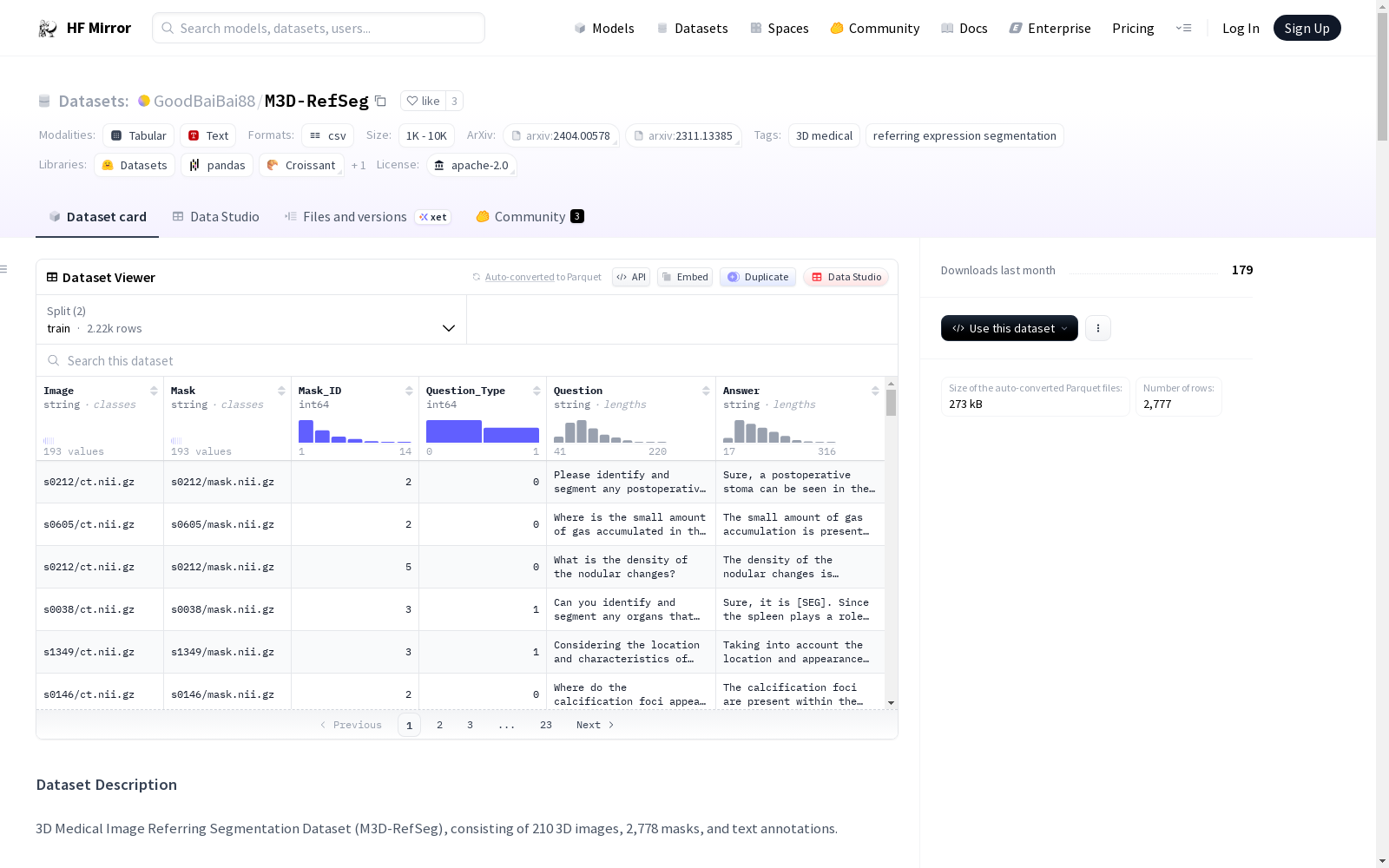
构建方式
M3D-RefSeg数据集的构建,是以TotalSegmentator分割数据集为蓝本,精选出210幅3D医学影像,并针对每幅影像进行了文本及相应区域的重新注释。注释工作由经验丰富的医生完成,原始中文文本注释存储于text_zh.txt文件中,同时采用Qwen 72B大型语言模型进行自动翻译,并将翻译后的英文注释组织存储于text.json文件中。此外,利用大型语言模型将区域描述文本转换为问答对,并以CSV文件形式保存。
特点
该数据集的特点在于,其专注于3D医学影像的指代分割任务,包含图像-掩膜-文本三元组,为文本引导的分割、指代分割、推理分割等任务提供了丰富的数据资源。数据集遵循Apache-2.0协议开源,且所有数据均为公开可用,便于研究者和开发者使用。此外,数据集中的注释质量高,由专业医生完成,保证了数据的准确性和可靠性。
使用方法
使用M3D-RefSeg数据集时,首先需要通过提供的脚本进行数据预处理,包括格式转换、归一化、裁剪等。之后,可以构建数据集,通过提供的示例代码,对数据集进行训练、验证和测试。数据集提供了HTTP克隆、SDK下载和手动下载等多种获取方式,用户可根据需要选择合适的方法进行数据集的加载和使用。
背景与挑战
背景概述
在医学影像分析领域,三维医学图像分割一直是一项重要挑战。随着指向性分割(referring segmentation)任务的兴起,即在给定文本描述的基础上对图像中的相应区域进行分割,该领域的研究逐渐深入。M3D-RefSeg数据集应运而生,旨在推进三维医学图像的指向性分割研究。该数据集由北京航空航天大学计算机学院和百度共同构建,包含210个三维图像、2778个掩膜以及对应的文本注释。数据集的构建过程邀请经验丰富的医生参与注释,并利用大型语言模型进行文本的自动翻译和问题-答案对的转换,从而为指向性分割任务提供了高质量的数据基础。M3D-RefSeg数据集的发布,对促进三维医学图像分析领域的发展具有重要意义,为相关研究提供了宝贵的资源。
当前挑战
M3D-RefSeg数据集在构建过程中面临的主要挑战包括:1)高质量的注释成本高昂,特别是对于指向性分割任务所需的三元组(图像-掩膜-文本)的构建;2)数据集的多样性和覆盖范围需要广泛,以确保模型能在不同的医学场景下具有良好的泛化能力。此外,数据集在解决领域问题方面也面临挑战,例如如何通过文本描述有效地引导模型进行精确的分割,以及如何在保持数据集质量的同时,实现数据集的扩展和更新。这些挑战均需要在未来的研究中逐一克服,以推动指向性分割任务的进一步发展。
常用场景
经典使用场景
在医学图像分析领域,3D医疗图像的精准分割一直是研究的焦点。M3D-RefSeg数据集为此提供了文本引导的分割训练资源,其经典使用场景在于,通过结合图像、掩膜和文本描述,实现对指定病变区域的精确分割,为后续诊断和治疗提供了可靠的数据支持。
实际应用
在实际应用中,M3D-RefSeg数据集可以被用于开发辅助诊断系统,帮助医生更准确地定位病变区域,提高诊断的效率和准确性。此外,它还可以用于医学图像的分析与理解,为患者提供个性化的治疗方案。
衍生相关工作
基于M3D-RefSeg数据集,研究者们已经开展了一系列相关工作,如M3D模型和SegVol系统,这些工作不仅提升了3D医疗图像分割的性能,还推动了多模态大语言模型在医学图像分析中的应用,为医疗信息化和智能化贡献了新的研究成果。
以上内容由遇见数据集搜集并总结生成


