SRFUND
收藏arXiv2024-06-13 更新2024-06-21 收录
下载链接:
https://sprateam-ustc.github.io/SRFUND
下载链接
链接失效反馈官方服务:
资源简介:
SRFUND是由中国科学技术大学和科大讯飞联合创建的多语言层次结构重建基准数据集,旨在推进表单理解任务的发展。该数据集包含1592张表单图像,涵盖八种语言,每种语言199张图像。数据集详细标注了每个图像中的单词、文本行和实体的位置及内容,并特别关注了表单中常见的多项目表格区域的位置和结构。SRFUND不仅支持实体分类和关系预测等任务,还引入了全局层次结构依赖,超越了传统的局部关键值关联,为处理多样布局和全局层次结构的表单提供了新的挑战和机遇。
SRFUND is a multilingual hierarchical structure reconstruction benchmark dataset jointly created by the University of Science and Technology of China and iFLYTEK, aiming to advance the development of form understanding tasks. This dataset contains 1592 form images covering eight languages, with 199 images per language. It meticulously annotates the positions and contents of words, text lines and entities in each image, with particular focus on the positions and structures of multi-item table regions common in forms. SRFUND not only supports tasks such as entity classification and relation prediction, but also introduces global hierarchical structural dependencies that transcend traditional local key-value associations, providing new challenges and opportunities for processing forms with diverse layouts and global hierarchical structures.
提供机构:
中国科学技术大学,合肥,中国 2科大讯飞,合肥,中国
创建时间:
2024-06-13
搜集汇总
数据集介绍
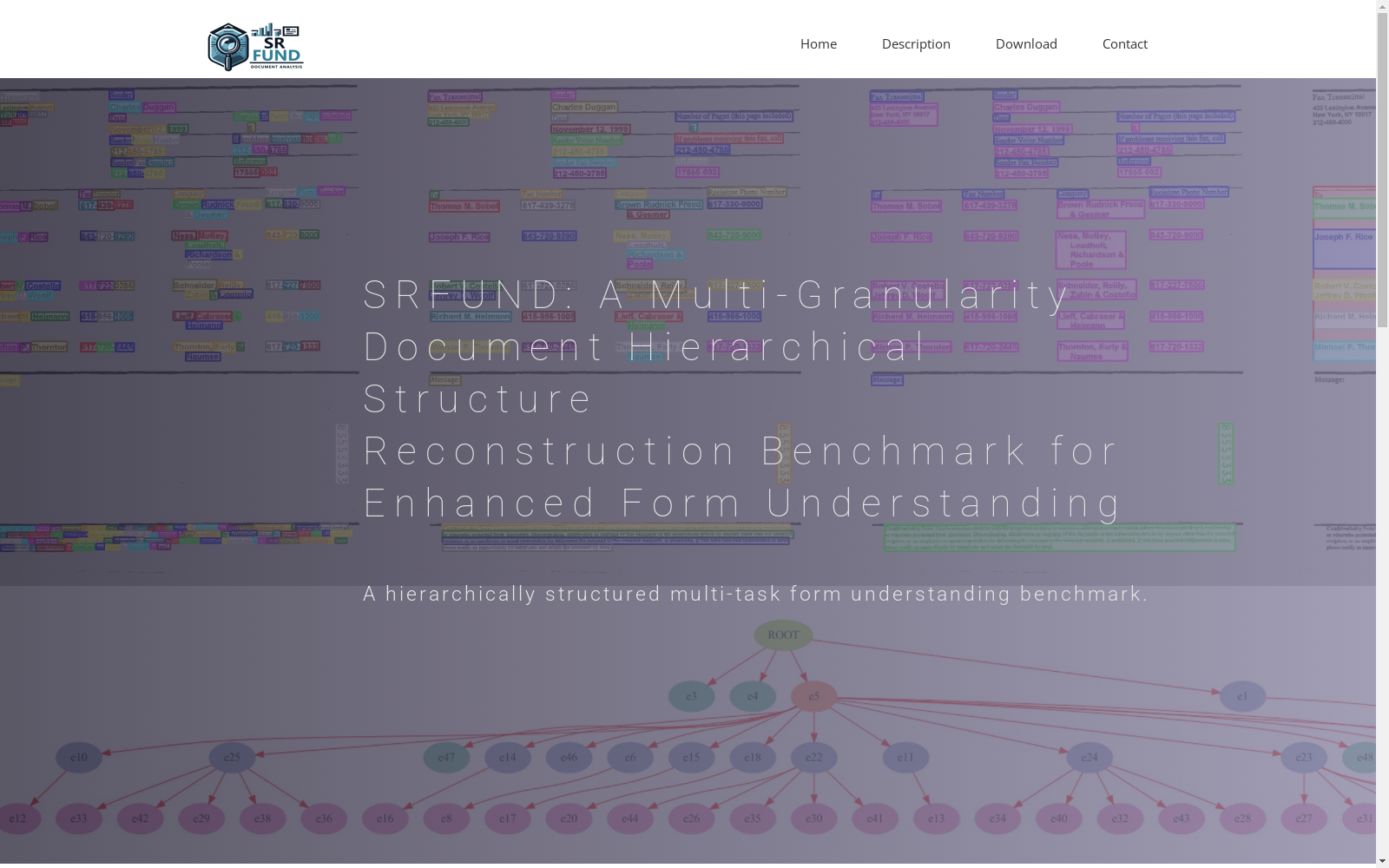
构建方式
SRFUND数据集的构建基于FUNSD和XFUND数据集,涵盖了这两个数据集中的所有文档图像。为了确保数据集的严谨性,我们对原始数据集中的单词级标注信息进行了精细处理,包括调整不准确的单词级边界框、补充缺失的文本信息、将连续的单词合并成文本行并进行标注、为实体标注多边形边界框、确定实体的类别、标注项目表的位置及其表头和每行项目的内容,以及标注具有链接关系的实体之间的关系。为了保证标注的准确性,所有标注结果都经过了至少三轮的交叉检查,并由文档处理领域的专家解决了任何有争议的标注。
特点
SRFUND数据集具有以下特点:1) 支持多任务,包括单词到文本行合并、文本行到实体合并、实体类别分类、项目表定位和基于实体的全文档层次结构恢复;2) 支持多语言,包括英语、中文、日语、德语、法语、西班牙语、意大利语和葡萄牙语,使其成为跨语言表单理解的强大工具;3) 包含全球层次结构依赖关系,超越了传统的局部键值关联,使模型能够更好地理解文档的复杂结构。
使用方法
SRFUND数据集可用于评估和训练表单理解任务的各种模型,包括基于纯文本输入的语言模型、基于纯视觉输入的检测模型以及利用多模态输入的文档预训练语言模型。用户可以根据自己的需求和任务选择合适的模型进行训练和评估。此外,SRFUND数据集还提供了详细的标注信息,可以帮助用户更好地理解表单的层次结构和逻辑关系。
背景与挑战
背景概述
文档理解领域,特别是表格理解,对自动化文档处理至关重要。准确识别和组织文本内容对于自动化文档处理至关重要。现有的数据集,如FUNSD和XFUND,支持实体分类和关系预测任务,但通常仅限于本地和实体级注释。这种限制忽略了文档的层次结构表示,限制了复杂表格的全面理解。为了解决这个问题,我们提出了SRFUND,这是一个层次结构的文档理解多任务基准。SRFUND在原始FUNSD和XFUND数据集的基础上提供了精细的注释,包括五个任务:(1)单词到文本行的合并,(2)文本行到实体的合并,(3)实体类别分类,(4)项目表定位,以及(5)基于实体的完整文档层次结构恢复。我们仔细地补充了原始数据集中各个粒度级别的缺失注释,并添加了表格中多项目表区域的详细注释。此外,我们引入了实体关系预测任务的全局层次结构依赖性,超越了传统的本地键值关联。SRFUND数据集包括英语、中文、日语、德语、法语、西班牙语、意大利语和葡萄牙语在内的八种语言,使其成为跨语言表格理解的有力工具。广泛的实验结果表明,SRFUND数据集在处理表格的多样布局和全局层次结构方面提出了新的挑战和重大机遇,从而为表格理解领域提供了深刻的见解。
当前挑战
SRFUND数据集在表格理解领域提出了新的挑战,包括:(1)构建全局层次结构依赖性,以便更全面地理解复杂表格;(2)对项目表区域进行定位,以便更准确地提取表格中的信息;(3)在多语言环境中进行表格理解,以便更广泛地应用表格理解技术。
常用场景
经典使用场景
SRFUND数据集广泛应用于表单理解领域,其经典使用场景包括:1. 文字到文本行的合并;2. 文本行到实体的合并;3. 实体类别分类;4. 项目表格定位;5. 基于实体的全文档层次结构恢复。这些任务涵盖了表单理解的各个方面,使得SRFUND成为表单理解研究的宝贵资源。
解决学术问题
SRFUND数据集解决了现有表单理解数据集在层次结构和全局结构依赖方面的不足。它提供了更精细的标注,包括单词、文本行、实体和项目表格等多个粒度,并引入了全局层次结构依赖关系,超越了传统的局部键值关联。这使得SRFUND能够支持更全面的表单理解任务,并为表单理解领域带来了新的挑战和机遇。
衍生相关工作
SRFUND数据集衍生了许多相关的研究工作,例如:1. 基于SRFUND数据集的多任务表单理解模型;2. 基于SRFUND数据集的多语言表单理解模型;3. 基于SRFUND数据集的表单结构恢复算法。这些研究工作进一步推动了表单理解技术的发展,并为表单理解领域的未来研究提供了新的方向。
以上内容由遇见数据集搜集并总结生成


