ccmusic-database/instrument_timbre
收藏Hugging Face2025-02-17 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ccmusic-database/instrument_timbre
下载链接
链接失效反馈资源简介:
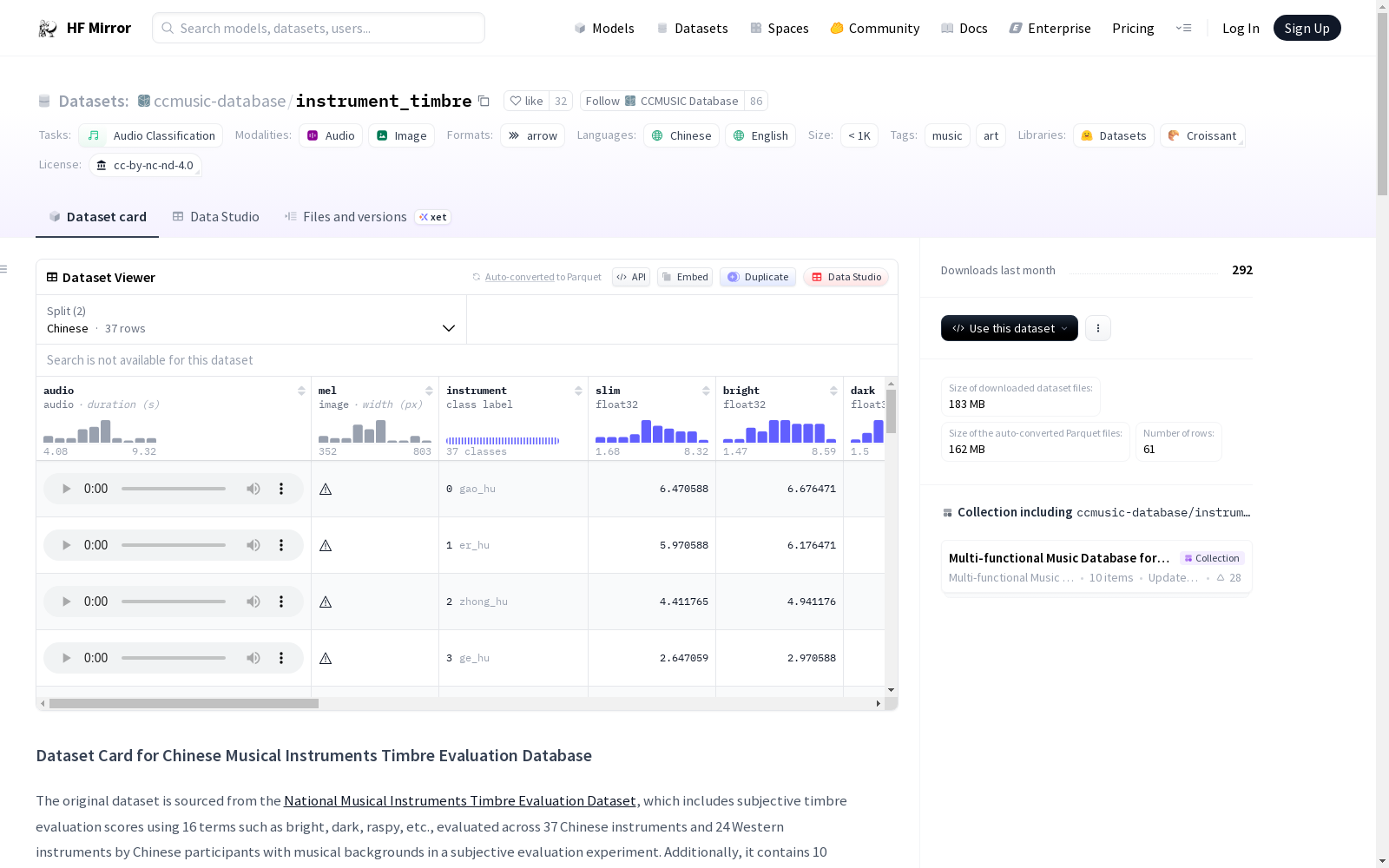
该数据集包含了对37种中国乐器和24种西方乐器的主观音色评估分数,评估由14位具有音乐背景的参与者完成。数据集还包括10种乐器的频谱图分析报告。数据集结构包括音频文件、频谱图、乐器名称和16个音色评估项的分数。数据集适用于进行乐器音色分析以及相关的回归任务。
The raw dataset encompasses subjective timbre evaluation scores comprising 16 terms, such as bright, dark, raspy, etc, evaluated across 37 Chinese instruments and 24 Western instruments by 14 participants with musical backgrounds in a subjective evaluation experiment. Additionally, it includes 10 reports on spectrogram analysis of 10 instruments. The dataset is structured with audio files, spectrograms, instrument names, and scores for 16 timbre evaluation terms. It is suitable for conducting timber analysis of musical instruments and can also be utilized for various single or multiple regression tasks related to term scoring.
提供机构:
ccmusic-database
原始信息汇总
数据集概述
- 名称: Musical Instruments Timbre Evaluation Database
- 别名: Chinese Musical Instruments Timbre Evaluation Database
- 许可证: MIT
- 任务类别: 音频分类
- 语言: 中文, 英文
- 标签: 音乐, 艺术
- 大小类别: 小于1K
数据集描述
- 内容: 包含37种中国乐器和24种西方乐器的音色主观评价得分,以及10份乐器频谱图分析报告。
- 结构: 每个数据条目包含18列,包括乐器录音(.wav格式,采样率22,050 Hz)、乐器名称(中文拼音或英文)和16个评价项的10分制得分。
数据集结构
- 数据实例: .zip(.wav), .csv
- 数据字段: 传统乐器
- 数据分割: 中文, 非中文
数据集创建
- 采集与标准化: Zhaorui Liu, Monan Zhou
- 源语言生产者: CCMUSIC的学生
- 注释过程: 由14名具有音乐背景的参与者对37种中国民族乐器和24种非中国乐器进行的主观音色评价。
- 注释者: CCMUSIC的学生
使用考虑
- 社会影响: 促进音乐产业中AI的发展
- 偏见讨论: 仅限于传统乐器
- 其他已知限制: 数据量有限
附加信息
- 数据集管理员: Zijin Li
- 评估:
- 中文乐器: Yiliang, J. et al. (2020) ‘Analysis of Chinese Musical Instrument Timbre Based on Objective Features’, Journal of Fudan University(Natural Science), pp. 346-353+359. doi:10.15943/j.cnki.fdxb-jns.2020.03.014.
- 非中文乐器: Jiang, Wei et al. “Analysis and Modeling of Timbre Perception Features of Chinese Musical Instruments.” 2019 IEEE/ACIS 18th International Conference on Computer and Information Science (ICIS) (2019): 191-195.
许可证信息
- 类型: MIT License
- 版权所有者: CCMUSIC
引用信息
bibtex @dataset{zhaorui_liu_2021_5676893, author = {Monan Zhou, Shenyang Xu, Zhaorui Liu, Zhaowen Wang, Feng Yu, Wei Li and Baoqiang Han}, title = {CCMusic: an Open and Diverse Database for Chinese and General Music Information Retrieval Research}, month = {mar}, year = {2024}, publisher = {HuggingFace}, version = {1.2}, url = {https://huggingface.co/ccmusic-database} }
AI搜集汇总
数据集介绍
构建方式
在音乐声学领域,乐器音色评价数据库的构建依赖于严谨的主观感知实验。本数据集源自国家乐器音色评价数据库,通过邀请具备音乐背景的中国参与者,对37种中国乐器和24种西方乐器的录音进行系统评估。评估过程采用16个音色感知术语,如明亮、暗淡、粗糙等,每个术语均以九点量表进行评分,确保了数据的科学性与一致性。数据经过处理后,整合为包含音频、梅尔频谱及评分字段的结构化格式,形成了当前数据集的两个独立子集:中国乐器部分与西方乐器部分。
使用方法
使用该数据集时,研究者可通过Hugging Face的datasets库直接加载,数据集默认划分为“Chinese”和“Western”两个子集。每个子集包含音频、乐器名称及16个音色评分字段,支持迭代访问与批量处理。音频采样率为44100赫兹,可直接用于声学特征提取或听觉感知实验。数据集的标准化格式便于集成至深度学习框架,适用于音色分类、感知属性预测或跨乐器音色分析等研究场景。此外,数据集提供了镜像链接,确保在不同平台间的可访问性与稳定性。
背景与挑战
背景概述
乐器音色评价数据库的构建源于音乐信息检索领域对音色感知量化研究的迫切需求。该数据集由ccmusic-database团队于近年创建,核心研究人员包括Zhaorui Liu、Monan Zhou及Zijin Li等,其研究焦点在于通过主观评价实验,系统性地采集中国与西方乐器的音色感知特征数据。数据集涵盖了37种中国民族乐器与24种西方乐器,并基于16个音色描述词进行九点量表评分,为音色感知建模、乐器分类及跨文化音乐分析提供了珍贵的实证基础,显著推动了计算音乐学与音乐人工智能的发展。
当前挑战
在音色感知研究领域,乐器音色的主观性与多维性构成了核心挑战,如何准确量化并建模人类对音色特征的复杂感知仍是未解难题。数据构建过程中,面临多重困难:一是音色评价高度依赖听者的音乐背景与文化语境,需确保标注者均为中国音乐专业人士以维持评价一致性;二是数据规模有限,仅包含61种乐器的样本,可能影响模型的泛化能力;三是音色描述词的选择与评分标准化需平衡主观感知与客观声学特征,这对数据集的科学性与实用性提出了较高要求。
常用场景
经典使用场景
在音乐声学与计算音乐学领域,乐器音色评估数据库为研究者提供了宝贵的实证资源。该数据集通过整合37种中国民族乐器与24种西方乐器的音频样本,并辅以16项主观音色感知维度的九点评分,成为音色特征分析与建模的经典工具。研究者可基于此开展乐器音色感知的量化研究,探索不同乐器在明亮、浑厚、尖锐等感知维度上的分布规律,为音色认知理论提供数据支撑。
解决学术问题
该数据集有效应对了音乐信息检索中音色特征建模的挑战,解决了传统方法依赖物理声学特征而忽视主观感知的局限。通过提供大规模、跨文化乐器的标准化感知评分,它支持音色感知与声学参数之间的关联性研究,促进了计算模型对人类音色感知机制的模拟。其意义在于构建了连接客观声学信号与主观听觉体验的桥梁,推动了音乐心理学与信号处理领域的交叉融合。
实际应用
在现实应用中,该数据集为智能音乐生成、乐器音色合成及音乐推荐系统提供了关键的训练与评估基准。音频工程师可借助其感知评分优化虚拟乐器的音色设计,使其更贴近真实乐器的听觉特质。音乐教育领域则能利用该数据开发音色感知训练工具,辅助学习者辨别不同乐器的音色差异。此外,文化遗产保护中,该数据集为民族乐器音色的数字化存档与复原提供了科学依据。
数据集最近研究
最新研究方向
在音乐信息检索领域,乐器音色评估数据库正成为研究焦点。该数据集融合了中西方乐器的音色主观评价数据,为音色感知建模提供了宝贵资源。前沿研究聚焦于利用深度学习技术,结合音频信号与多维音色描述符,探索跨文化音色感知的共性与差异。相关热点事件包括人工智能在音乐创作与修复中的应用,推动了音色建模的精细化发展。该数据集的意义在于促进了计算音乐学与认知科学的交叉,为智能音乐系统的音色合成与识别奠定了数据基础,助力音乐文化遗产的数字化保存与创新。
以上内容由AI搜集并总结生成


