metavi/video-understanding-distillation-sample
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/metavi/video-understanding-distillation-sample
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
pretty_name: Video Understanding Distillation Sample
language:
- en
task_categories:
- text-generation
- image-text-to-text
tags:
- video-understanding
- multimodal
- distillation
- dataset
size_categories:
- n<1K
---
# Video Understanding Distillation Sample
This public sample demonstrates what a training-ready video understanding / multimodal distillation dataset can look like.
## Intended purpose
This dataset is not a production corpus. It is a schema demonstration for potential partners evaluating SuperviseLab's delivery approach.
## What it shows
- clip-level metadata
- short and long captions
- OCR text
- transcript
- speaker attribution
- structured JSON targets
- distillation-ready supervision format
## Website
https://superviselab.com/?utm_source=huggingface&utm_medium=dataset&utm_campaign=hf_sample
提供机构:
metavi
搜集汇总
数据集介绍
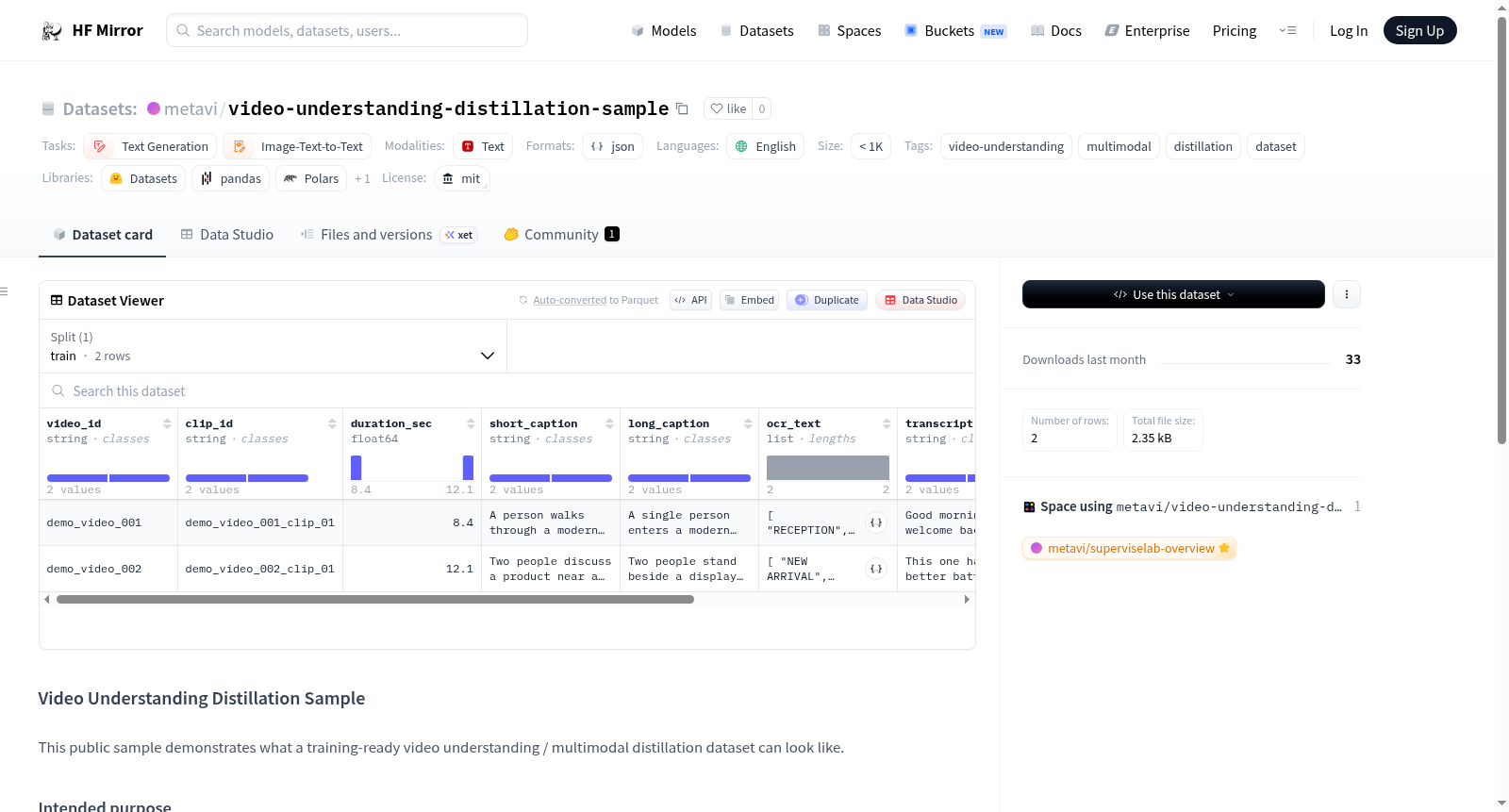
构建方式
该数据集作为视频理解与多模态蒸馏任务的示范性样本,由SuperviseLab精心构建,旨在展示其成熟的交付范式与数据架构。构建过程中,数据集聚焦于片段级元数据的精细标注,为每段视频片段赋予短标题与长描述双重层级的语义化标注。与此同时,数据集集成了OCR文本提取、语音转录文本以及说话人归属信息,这些多源异构数据以结构化的JSON格式组织,形成了契合蒸馏场景所需的监督信号格式,确保数据能够直接服务于训练流程。
特点
该数据集虽为小规模样本,却集中体现了高信息密度的设计理念,涵盖从视觉到语言的多模态理解维度。其核心特色在于多粒度的标注体系:短标题提供快速梗概,长描述覆盖深度语义,OCR与转录文本则捕捉画面与声音中的显式信息。说话人归属的引入为对话场景的动态分析提供了可能。结构化JSON目标的设计使其与蒸馏流水线无缝对接,展示了在训练就绪状态下的数据编排方式。
使用方法
数据集的便捷之处在于其即开即用的特性,适合用于多模态蒸馏任务的基准测试或流程验证。使用者可直接加载JSON目标字段作为训练标签,将OCR与转录文本视为辅助监督信号。短标题与长描述可用于双层次对比学习或生成型任务的损失计算。鉴于其示范性质,推荐先解析元数据架构,再根据蒸馏框架的输入接口进行字段映射,从而快速搭建视频理解模型的训练流水线。
背景与挑战
背景概述
该数据集由SuperviseLab机构创建,发布于HuggingFace平台,旨在为视频理解与多模态蒸馏任务提供一种示范性数据格式。其核心研究问题在于如何构建一个训练就绪的高质量数据集,以支持从视频中提取多层级语义信息,包括短描述、长描述、OCR文本、转录文本、说话人归属及结构化JSON目标。通过公开样本,研究团队希望推动视频多模态蒸馏领域的数据标准化,提升下游任务的效果与可复现性。尽管数据集规模极小(少于1000个样本),但其设计理念为后续大规模数据集的开发提供了重要参考,对视频理解、多模态学习及知识蒸馏等相关研究方向具有启示意义。
当前挑战
视频理解领域面临的核心挑战在于多模态信息的有效融合与蒸馏。如何从海量视频中同步提取视觉、文本、音频等多维度特征,并保持语义一致性,是当前技术瓶颈。本数据集在构建过程中需解决样本标注的精细度问题,例如对片段级元数据与长短描述进行对齐,同时确保OCR文本、转录文本与说话人归属的准确性。此外,由于视频数据天然具备时序特性,如何设计结构化JSON目标以支持高效的蒸馏训练是一大难点。微小的数据集规模(不足千条样本)也限制了统计显著性,使得方案验证面临过拟合风险,需依赖后续大规模扩展来验证其通用性与鲁棒性。
常用场景
经典使用场景
video-understanding-distillation-sample数据集作为多模态视频理解与知识蒸馏领域的示范性样本,其核心价值在于为研究者提供一种标准化的、可直接用于训练的视频理解数据范式。该数据集融合了剪辑级元数据、长短文本描述、光学字符识别文本、转录文本、说话人归属以及结构化JSON目标,完美适配从原始视频到结构化监督信号的蒸馏流程,常见于视频内容理解、多模态对齐、视听语义融合以及大规模视频数据蒸馏训练等研究场景。
衍生相关工作
围绕该数据集所勾勒的数据架构,衍生了一系列经典工作,包括但不限于基于大规模视频文本对的跨模态预训练模型(如VideoCLIP、InternVideo)、多层级视频描述生成方法(VideoChat等),以及面向视频理解的知识蒸馏框架(Distill-Video、VideoKD)。这些工作利用类似的元数据层级与结构化监督信号,推动了视频表征学习、零样本视频检索以及多模态推理等方向的技术迭代与评测基准建立。
数据集最近研究
最新研究方向
该样本数据集展示了视频理解与多模态知识蒸馏领域的前沿数据构建范式。当前研究热点聚焦于如何通过结构化元数据(包括片段级描述、长短字幕、OCR文本、语音转录及说话人归因)为视觉语言模型提供高质量的监督信号。该样本所体现的蒸馏就绪格式,正契合了业界对高效多模态对齐技术的迫切需求——在视频基础模型训练中,通过精细化标注实现从大模型到轻量模型的知识迁移,已成为降低计算成本、加速推理效率的关键路径。这类数据架构的标准化探索,将推动视频理解任务从简单识别向复杂情景推理演进,为自动驾驶、智能监控等实时应用场景奠定数据基础。
以上内容由遇见数据集搜集并总结生成


