ImageNet
收藏Papers with Code2024-05-15 收录
下载链接:
https://paperswithcode.com/dataset/imagenet
下载链接
链接失效反馈资源简介:
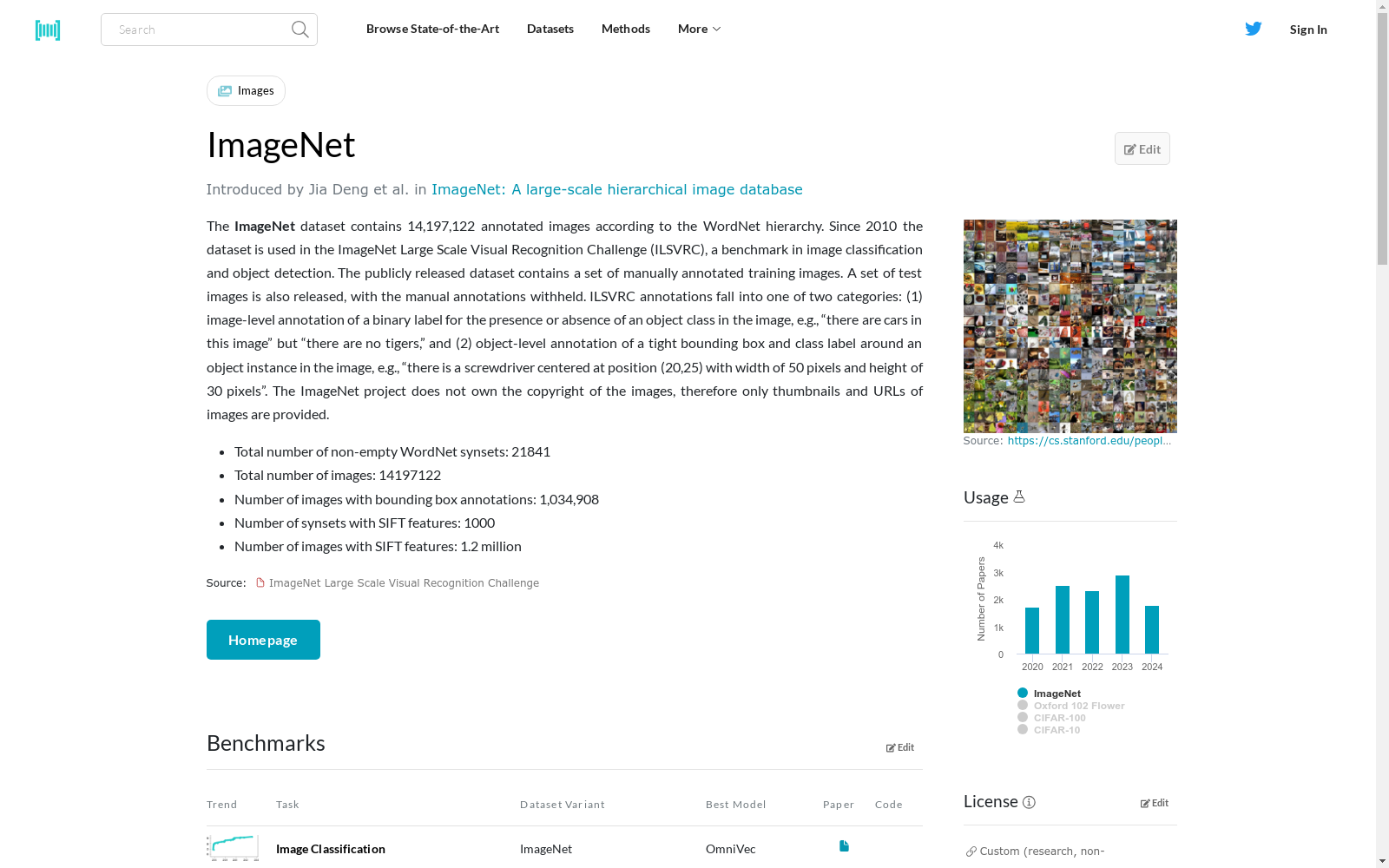
The ImageNet dataset contains 14,197,122 annotated images according to the WordNet hierarchy. Since 2010 the dataset is used in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), a benchmark in image classification and object detection. The publicly released dataset contains a set of manually annotated training images. A set of test images is also released, with the manual annotations withheld. ILSVRC annotations fall into one of two categories: (1) image-level annotation of a binary label for the presence or absence of an object class in the image, e.g., “there are cars in this image” but “there are no tigers,” and (2) object-level annotation of a tight bounding box and class label around an object instance in the image, e.g., “there is a screwdriver centered at position (20,25) with width of 50 pixels and height of 30 pixels”. The ImageNet project does not own the copyright of the images, therefore only thumbnails and URLs of images are provided.
ImageNet数据集(ImageNet)包含14,197,122张按照词网(WordNet)层级结构标注的图像。自2010年起,该数据集被用于图像分类与目标检测领域的基准测试——ImageNet大规模视觉识别挑战赛(ILSVRC)。公开发布的数据集包含一批经人工标注的训练图像,同时也发布了一批测试图像,但未公开其人工标注信息。ILSVRC的标注分为两类:(1) 图像级二元标注,用于判断图像中是否存在某一目标类别,例如"本图像中包含汽车,但未包含老虎";(2) 目标级标注,对图像中的目标实例标注精准包围框与类别标签,例如"存在一把螺丝刀,其中心位于坐标(20,25),宽度为50像素,高度为30像素"。ImageNet项目不拥有这些图像的版权,因此仅提供图像的缩略图与URL链接。
AI搜集汇总
数据集介绍
构建方式
ImageNet数据集的构建基于大规模图像标注任务,通过众包平台招募志愿者对图像进行分类和标注。该数据集涵盖了超过1400万张图像,分布在2万多个类别中。构建过程中,采用了层次化的分类结构,确保每个类别下的图像具有较高的相似性,从而提高了数据集的分类准确性。此外,数据集的构建还考虑了图像的多样性和代表性,以确保其在计算机视觉研究中的广泛适用性。
特点
ImageNet数据集以其庞大的规模和丰富的类别多样性著称,为深度学习模型提供了丰富的训练数据。其层次化的分类结构不仅有助于模型的泛化能力,还为研究者提供了多层次的分类挑战。此外,数据集的高质量标注和广泛的应用领域,使其成为计算机视觉领域的重要基准数据集。
使用方法
ImageNet数据集主要用于训练和评估计算机视觉模型,特别是卷积神经网络(CNN)。研究者可以通过下载数据集并使用标准的图像处理工具进行预处理,然后利用深度学习框架如TensorFlow或PyTorch进行模型训练。数据集的评估通常通过计算分类准确率、召回率等指标来进行,以验证模型的性能。此外,ImageNet还定期举办挑战赛,鼓励研究者提交最新的模型和算法,推动计算机视觉技术的发展。
背景与挑战
背景概述
ImageNet数据集由斯坦福大学的李飞飞教授及其团队于2009年创建,旨在解决大规模图像分类问题。该数据集包含了超过1400万张标注图像,涵盖了2万多个类别,极大地推动了计算机视觉领域的发展。ImageNet的构建不仅为深度学习算法提供了丰富的训练数据,还通过年度ImageNet大规模视觉识别挑战赛(ILSVRC)促进了算法性能的快速提升,成为图像识别领域的重要基准。
当前挑战
ImageNet数据集在构建过程中面临了多重挑战。首先,图像的标注工作需要大量的人力资源和时间,确保标签的准确性和一致性。其次,数据集的规模庞大,如何高效地存储、管理和处理这些数据成为技术难题。此外,不同类别之间的图像差异巨大,如何设计有效的分类算法以应对这些多样性也是一大挑战。最后,随着技术的进步,数据集的更新和维护也需要持续投入,以保持其前沿性和实用性。
发展历史
创建时间与更新
ImageNet数据集由斯坦福大学教授李飞飞团队于2009年创建,旨在推动计算机视觉领域的发展。该数据集自创建以来,经历了多次重大更新,最近一次主要更新是在2014年,进一步丰富了图像类别和数量,以适应不断发展的深度学习技术需求。
重要里程碑
ImageNet的创建标志着大规模图像数据集时代的到来,极大地推动了计算机视觉研究的进展。2010年,ImageNet大规模视觉识别挑战赛(ILSVRC)的设立,成为该数据集发展的重要里程碑,吸引了全球研究者的广泛参与。2012年,AlexNet在ILSVRC中取得突破性成绩,开启了深度学习在图像识别领域的革命,进一步巩固了ImageNet在学术界和工业界的地位。
当前发展情况
当前,ImageNet已成为计算机视觉领域的基础数据集之一,广泛应用于图像分类、目标检测和语义分割等任务的训练和评估。其丰富的图像数据和多样的类别标签,为深度学习模型的训练提供了宝贵的资源。随着技术的进步,ImageNet不断扩展和优化,以适应更高精度和更复杂任务的需求,持续推动着计算机视觉技术的创新与发展。
发展历程
- ImageNet项目正式启动,旨在创建一个大规模的图像数据库,以支持计算机视觉研究。
- ImageNet大规模视觉识别挑战赛(ILSVRC)首次举办,成为计算机视觉领域的重要竞赛。
- AlexNet在ILSVRC 2012中取得突破性成绩,标志着深度学习在图像识别领域的崛起。
- GoogleNet和VGGNet在ILSVRC 2014中表现出色,进一步推动了深度学习模型的发展。
- ResNet在ILSVRC 2015中获得冠军,其深度残差网络结构成为图像识别领域的重要里程碑。
- ILSVRC 2017宣布结束,标志着ImageNet挑战赛的历史使命完成,但其对计算机视觉领域的深远影响仍在持续。
常用场景
经典使用场景
在计算机视觉领域,ImageNet数据集以其庞大的规模和丰富的类别著称,成为深度学习模型训练的经典资源。研究者们利用ImageNet进行图像分类、目标检测和语义分割等任务,通过大规模数据集的训练,显著提升了模型的泛化能力和识别精度。
解决学术问题
ImageNet数据集解决了计算机视觉领域中数据稀缺和类别不平衡的问题,为研究者提供了丰富的图像资源,推动了深度学习技术的发展。其广泛应用于学术研究中,促进了图像识别、目标检测和语义分割等方向的突破,对提升模型性能和推动技术进步具有重要意义。
衍生相关工作
基于ImageNet数据集,研究者们开发了多种经典的深度学习模型,如AlexNet、VGG、ResNet等,这些模型在图像识别领域取得了显著成果。此外,ImageNet还催生了诸如COCO、Places等其他大规模图像数据集,进一步推动了计算机视觉领域的研究和发展。
以上内容由AI搜集并总结生成


