classification-ie-optimization
收藏Hugging Face2025-01-30 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/derek-thomas/classification-ie-optimization
下载链接
链接失效反馈官方服务:
资源简介:
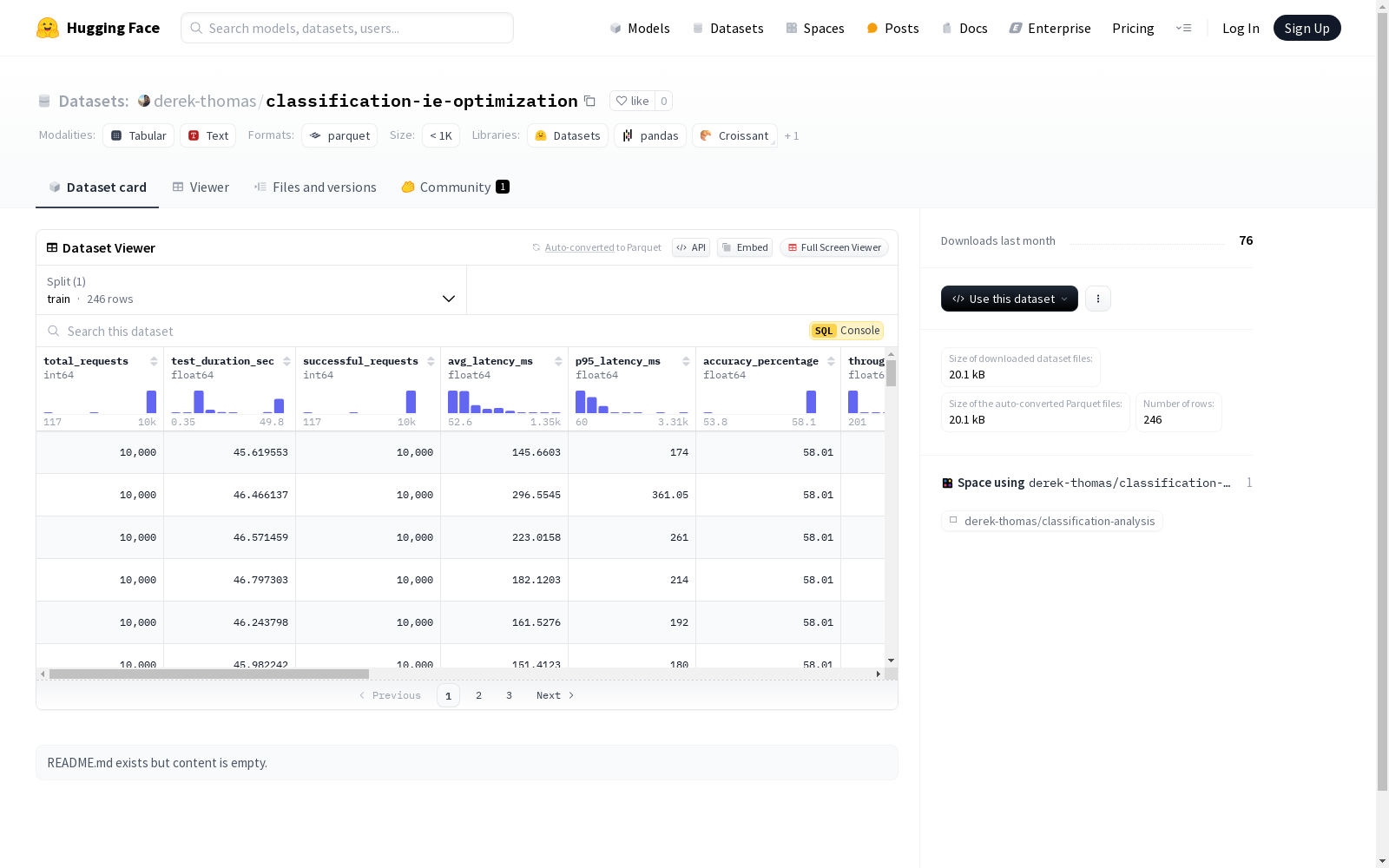
该数据集包含多个与性能测试相关的特征,如请求总数、测试持续时间、成功请求数、平均延迟、95%延迟、准确率、吞吐量等。此外,还包括硬件类型、批量大小、图像、引擎、供应商、虚拟用户数、每十亿秒数、每秒成本和每十亿成本等信息。数据集分为训练集,包含246个样本,总大小为39228字节。
创建时间:
2025-01-25
搜集汇总
数据集介绍
构建方式
该数据集名为classification-ie-optimization,其构建方式是通过采集与硬件性能评估相关的各项指标,包括请求总数、测试持续时间、成功请求数、平均延迟、95%延迟、准确率百分比、吞吐量等,并整合了硬件类型、批量大小、图像类型、引擎类型、供应商信息、虚拟用户数等维度信息,以此形成了一个全面评估硬件性能的复杂数据集。数据集通过训练集(train)的形式组织,其中包含了246个示例,数据量为39228字节。
特点
此数据集的特点在于它汇聚了硬件性能评估的多维度指标,不仅包含了基本的请求处理能力指标,还涵盖了成本效益分析的数据,如每秒成本、十亿成本等。这种多维度的数据结构为研究者在进行硬件性能优化、成本效益分析以及系统负载能力评估等方面提供了丰富的信息资源。此外,数据集的构建遵循了严谨的数据收集和处理流程,确保了数据的质量和可用性。
使用方法
用户在使用该数据集时,首先需要下载包含训练集的数据文件,总下载大小为20133字节。数据集采用JSON格式存储,用户可以通过解析JSON文件来访问数据。每个数据点都包含了一系列性能指标和硬件相关信息,便于用户进行数据分析和模型训练。同时,数据集提供的默认配置文件可以帮助用户快速上手,按照既定的数据路径进行加载和处理。
背景与挑战
背景概述
classification-ie-optimization数据集,诞生于深度学习在图像识别领域得到广泛应用的背景下,由专注于计算机视觉与机器学习领域的研究人员或机构开发。该数据集旨在针对图像分类任务中的性能优化进行研究,涉及硬件性能、模型效率等多个维度的评估。自创建以来,该数据集以其全面的数据特性和针对性,对图像分类领域的算法优化与性能评估产生了显著影响。
当前挑战
该数据集在研究领域面临的挑战主要包括:如何在保持高准确率的同时,提升模型的吞吐量和降低延迟,以及如何在不同的硬件和引擎平台上实现最优的资源配置与调度。构建过程中,数据集的创建者亦遭遇了如何平衡数据量与质量、确保测试覆盖面的广泛性与代表性的挑战。
常用场景
经典使用场景
在深度学习模型评估与优化领域,classification-ie-optimization数据集被广泛用于模拟不同的硬件和工作负载条件下的模型性能。该数据集提供了包括请求次数、测试时长、成功率、平均延迟、吞吐量等关键指标,使得研究者能够综合评估模型的运行效率。
解决学术问题
该数据集有效解决了硬件性能评估中的不确定性和不一致性问题,为学术研究提供了标准化的数据支持。通过分析数据集中不同配置下的模型表现,研究者能够识别影响模型性能的关键因素,为算法改进和硬件选择提供依据。
衍生相关工作
基于该数据集,学术界和产业界衍生出了一系列优化算法和性能评估框架。这些工作不仅提升了深度学习模型在特定硬件上的执行效率,也推动了相关领域的研究进展,如自动机器学习、模型压缩等。
以上内容由遇见数据集搜集并总结生成


