FFE-Bench
收藏Hugging Face2026-03-26 更新2026-03-27 收录
下载链接:
https://huggingface.co/datasets/PixelSmile/FFE-Bench
下载链接
链接失效反馈官方服务:
资源简介:
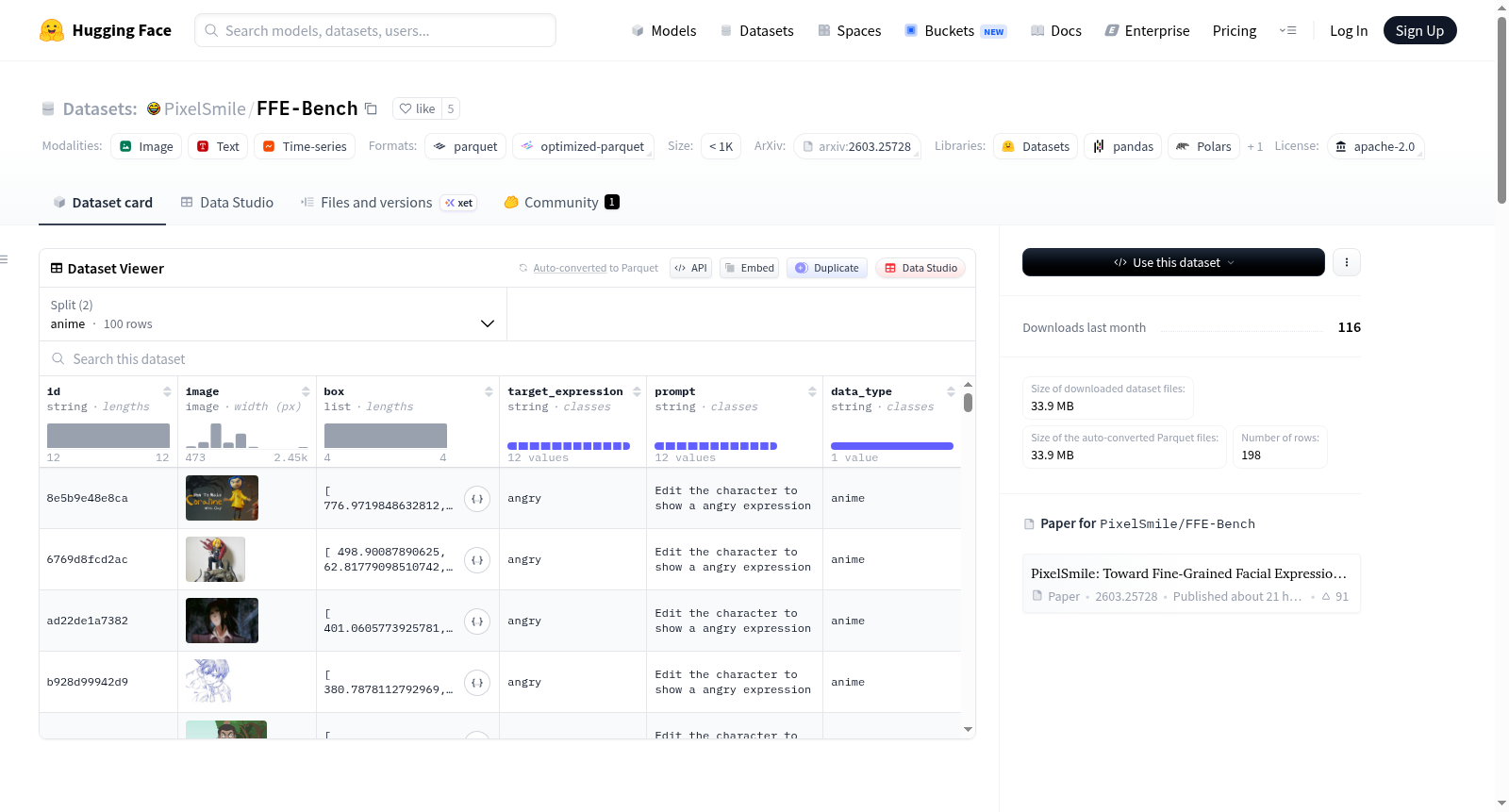
FFE-Bench是一个用于细粒度面部表情编辑的基准数据集,涵盖人类和动漫肖像,旨在评估现实场景中的可控面部编辑。当前版本包含198个编辑任务,其中98个为人类样本,100个为动漫样本。每个样本由输入图像、面部边界框、目标表情类别和无强度修饰符的文本提示定义。数据集设计用于评估多种指标,包括结构混淆率(mSCR)、编辑准确率(Acc)、控制线性评分(CLS)、和谐编辑评分(HES)和身份相似度(ID Sim)。FFE-Bench支持两种基准设置:通用编辑和线性控制,适用于比较不同面部编辑模型在结构混淆、编辑准确性和身份一致性等方面的性能。
创建时间:
2026-03-25
原始信息汇总
FFE-Bench 数据集概述
数据集简介
FFE-Bench 是一个用于人类和动漫肖像的细粒度面部表情编辑的基准数据集。该数据集设计了更丰富、更多样的表情类别,旨在评估真实场景下的可控面部编辑。
数据集内容
- 总编辑任务数:198个。
- 人类样本数:98个。
- 动漫样本数:100个。
- 每个样本定义:包含输入图像、人脸边界框、目标表情类别以及不含强度修饰符的文本提示。
评估指标
- 平均结构混淆率 (mSCR):评估语义重叠表情之间的结构混淆。
- 准确率 (Acc):评估表情编辑的准确性。
- 控制线性分数 (CLS):评估线性可控性。
- 调和编辑分数 (HES):评估表情编辑质量和身份保持之间的整体平衡。
- 身份相似度 (ID Sim):评估源人脸与编辑后人脸之间的身份一致性。
基准测试结果
报告了两种互补的基准测试设置:
- 通用编辑:在结构混淆、编辑准确性和身份一致性方面,比较通用编辑模型和面部编辑模型。
- 线性控制:在控制线性、编辑质量和身份保持方面,比较为可控表情操作设计的方法。
当前基准测试包含的模型:
- 通用编辑模型:Seedream-4.5, Nano Banana Pro, GPT-Image-1.5, FLUX.2 Klein, LongCat-Image-Edit, Qwen-Image-Edit-2511, PixelSmile。
- 线性控制模型:SAEdit, ConceptSlider, AttributeControl, Kontinuous-Kontext, SliderEdit, PixelSmile。
结果可视化:
- 通用编辑结果图:https://huggingface.co/datasets/PixelSmile/FFE-Bench/raw/main/assets/ffe-bench-general.png
- 线性控制结果图:https://huggingface.co/datasets/PixelSmile/FFE-Bench/raw/main/assets/ffe-bench-linear.png
评估代码
评估代码即将发布。
引用信息
如果 FFE-Bench 对您的研究或应用有帮助,请考虑引用我们的工作。 bibtex @article{hua2026pixelsmile, title={PixelSmile: Toward Fine-Grained Facial Expression Editing}, author={Jiabin Hua and Hengyuan Xu and Aojie Li and Wei Cheng and Gang Yu and Xingjun Ma and Yu-Gang Jiang}, journal={arXiv preprint arXiv:2603.25728}, year={2026} }
许可信息
本数据集采用 Apache License 2.0 许可。
搜集汇总
数据集介绍
构建方式
在面部表情编辑领域,FFE-Bench的构建遵循了系统化与精细化的原则。该基准数据集共包含198项编辑任务,涵盖98个人类肖像样本与100个动漫肖像样本。每个样本均以输入图像为基础,辅以面部边界框坐标、目标表情类别以及不含强度修饰符的文本提示,从而构建出结构清晰、定义明确的任务单元。这种设计旨在模拟真实场景下的可控面部编辑需求,为评估模型在细粒度表情操控上的性能提供了标准化的测试环境。
特点
FFE-Bench的核心特征在于其面向细粒度面部表情编辑的评估广度与深度。数据集不仅同时涵盖人类与动漫两类肖像,还设计了更为丰富多样的表情类别,突破了传统基准在表达多样性上的局限。其评估体系尤为全面,引入了结构混淆率、编辑准确率、控制线性度、谐波编辑分数及身份相似度等多维度量化指标,能够综合衡量模型在表情转换准确性、身份保持一致性以及控制线性可控性等方面的综合性能,为前沿研究提供了精细的测评视角。
使用方法
使用FFE-Bench进行模型评估时,研究者可依据其设定的两种互补基准场景展开。在通用编辑场景下,可将通用图像编辑模型或专用面部编辑模型在数据集上运行,通过计算结构混淆、编辑准确率与身份一致性等指标进行横向比较。在线性控制场景下,则专门针对设计用于可控表情操纵的方法,评估其控制线性度、编辑质量与身份保持的平衡。用户需按照数据集提供的任务定义处理输入,并利用其标准指标计算脚本对生成结果进行量化分析,从而客观评估模型在细粒度表情编辑任务上的综合能力。
背景与挑战
背景概述
在计算机视觉与生成式人工智能的交叉领域,细粒度面部表情编辑是一项极具前沿性与实用价值的研究课题。FFE-Bench 基准数据集由 Jiabin Hua 等研究人员于2026年提出,旨在为人类与动漫肖像的精细表情编辑提供一个系统性的评估框架。该数据集的核心研究问题聚焦于如何实现高保真、可控且身份一致的表情属性操控,从而推动生成模型在情感计算、数字内容创作及人机交互等领域的深入应用。通过构建包含丰富多样表情类别的任务集合,FFE-Bench 为量化评估模型的编辑准确性、结构混淆率及线性控制能力奠定了重要基础,对相关研究方向的发展产生了积极的引导作用。
当前挑战
FFE-Bench 所针对的细粒度面部表情编辑领域,其核心挑战在于如何精准解耦并操控面部肌肉运动的微妙特征,同时严格保持人物身份的固有属性。具体而言,模型需克服不同表情类别间存在的语义重叠与结构混淆问题,例如‘微笑’与‘咧嘴笑’之间的细微界限,这要求算法具备极高的感知与区分能力。在数据集构建过程中,挑战同样显著:需要精心设计涵盖人类与动漫双域、且具有足够多样性与平衡性的样本集合,并为每个样本标注无强度修饰符的文本提示,以确保评估任务既贴近真实场景又具备可复现的客观标准。这些挑战共同构成了该领域技术突破的关键瓶颈。
常用场景
经典使用场景
在计算机视觉与生成式人工智能领域,FFE-Bench作为细粒度面部表情编辑的基准测试集,其经典使用场景集中于评估和比较各类图像编辑模型在表情操控任务上的性能。该数据集精心设计了涵盖人类与动漫肖像的多样化表情类别,为研究者提供了一个标准化的测试平台,用以系统检验模型在保持身份一致性的前提下,精准生成或修改特定细微表情的能力。通过其结构化的任务定义与多维度评估指标,FFE-Bench已成为推动可控面部编辑技术迭代与优化的重要工具。
实际应用
超越纯学术研究,FFE-Bench所针对的技术在实际应用中展现出广泛潜力。在数字娱乐与内容创作产业,其支撑的技术可用于游戏角色、虚拟偶像或动漫人物的表情精细化定制,提升角色表现力与用户沉浸感。在心理研究、人机交互乃至辅助医疗领域,能够生成精确、可控面部表情的系统,可用于情绪识别训练、社交技能辅助或情感计算研究,为开发更自然、更具共情能力的智能交互界面提供了关键技术验证场景。
衍生相关工作
围绕FFE-Bench基准,已衍生出一系列具有影响力的经典研究工作。例如,原论文提出的PixelSmile模型便是在此基准上验证其细粒度编辑能力。同时,该基准也被用于评估如Seedream-4.5、FLUX.2 Klein等通用编辑模型,以及SAEdit、ConceptSlider等专为可控属性操作设计的模型在面部表情这一特定任务上的适应性。这些比较研究不仅揭示了不同技术路线的优势与局限,也进一步催生了针对表情强度控制、跨域表情迁移等更深入子方向的新方法与新模型。
以上内容由遇见数据集搜集并总结生成


