OoDIS
收藏arXiv2024-06-18 更新2024-06-19 收录
下载链接:
https://vision.rwth-aachen.de/oodis
下载链接
链接失效反馈官方服务:
资源简介:
OoDIS是由亚琛工业大学、伍珀塔尔大学和北京理工大学合作开发的数据集,专注于异常实例分割,旨在提高自动驾驶车辆对环境中未知物体的识别能力。该数据集整合了多个现有的异常分割数据集,如Fishyscapes、RoadAnomaly21和RoadObstacle21,提供了多样化的真实世界道路异常案例。创建过程中,研究团队对这些数据集进行了扩展和重新标注,以支持实例分割任务。OoDIS的应用领域主要集中在自动驾驶技术,特别是解决在训练中未见过的异常物体的精确分割问题,这对于避免交通事故至关重要。
OoDIS is a dataset developed collaboratively by RWTH Aachen University, the University of Wuppertal, and Beijing Institute of Technology. It focuses on anomalous instance segmentation, aiming to enhance the ability of autonomous vehicles to recognize unknown objects in their surrounding environments. This dataset integrates multiple existing anomaly segmentation datasets, such as Fishyscapes, RoadAnomaly21, and RoadObstacle21, providing diverse real-world road anomaly cases. During its development, the research team expanded and re-annotated these datasets to support the instance segmentation task. The main application scenarios of OoDIS are concentrated in autonomous driving technology, particularly addressing the accurate segmentation of anomalous objects unseen during model training, which is crucial for avoiding traffic accidents.
提供机构:
亚琛工业大学(德国),伍珀塔尔大学(德国),北京理工大学(中国)
创建时间:
2024-06-18
搜集汇总
数据集介绍
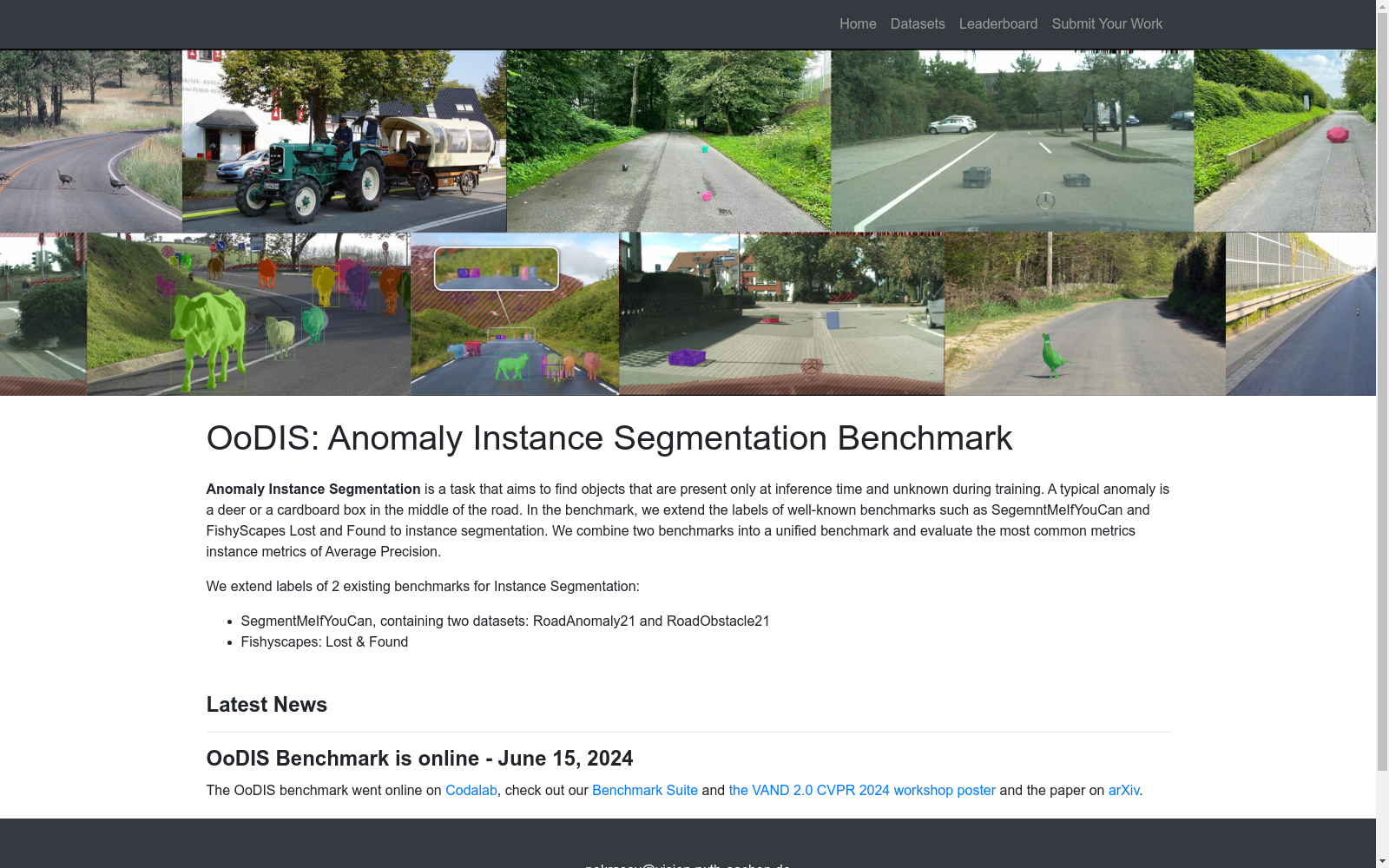
构建方式
OoDIS数据集的构建基于对现有异常分割数据集的扩展,特别是Fishyscapes、RoadAnomaly21和RoadObstacle21数据集。这些数据集原本用于语义异常分割,但缺乏实例级别的标注。为了填补这一空白,研究团队对这些数据集进行了重新标注,添加了实例分割的标签。标注过程中,每个异常对象都被单独标记,确保每个实例具有唯一的标识符。此外,为了适应自动驾驶场景的需求,标注策略特别关注了道路上的异常物体,如动物或丢失的货物,并采用了Cityscapes数据集中的平均精度(AP)指标进行评估。
特点
OoDIS数据集的主要特点在于其专注于异常实例分割任务,这在自动驾驶领域尤为重要。数据集包含了多样化的真实世界异常场景,涵盖了不同大小、形状和数量的异常物体。与传统的语义异常分割数据集不同,OoDIS提供了实例级别的标注,使得模型能够区分场景中的多个异常对象。此外,数据集还引入了AP50指标,用于评估模型在50%交并比(IoU)阈值下的表现,特别适用于小尺寸异常物体的检测。这种设计使得OoDIS成为评估和推动异常实例分割方法发展的理想基准。
使用方法
OoDIS数据集的使用方法主要包括模型训练、验证和测试。研究人员可以使用Cityscapes数据集中的19个类别作为内部分布数据进行训练,并允许使用辅助数据(如COCO)来引入虚拟异常。在验证和测试阶段,模型需要在未见过异常物体的情况下进行实例分割。评估时,仅关注异常类别的预测结果,忽略内部分布和模糊区域的预测。通过计算平均精度(AP)和AP50指标,研究人员可以量化模型在异常实例分割任务上的表现。此外,数据集还提供了公开的提交门户,允许研究人员提交新的方法并参与基准测试。
背景与挑战
背景概述
OoDIS(Out-of-Distribution Instance Segmentation)数据集由德国亚琛工业大学、伍珀塔尔大学等机构的研究团队于2024年提出,旨在解决自动驾驶场景中的异常实例分割问题。该数据集扩展了现有的异常分割基准,如Fishyscapes、RoadAnomaly21和RoadObstacle21,增加了实例级别的标注,以支持对未知对象的精确分割。OoDIS的提出填补了异常实例分割领域缺乏专用基准的空白,推动了自动驾驶系统在复杂环境下的感知能力提升。该数据集的核心研究问题是如何在训练数据中未见的对象(如野生动物或道路上的障碍物)出现时,实现精确的实例分割,从而避免潜在的交通事故。OoDIS的发布为相关领域的研究提供了重要的评估工具,促进了异常实例分割方法的发展。
当前挑战
OoDIS数据集面临的挑战主要体现在两个方面。首先,异常实例分割任务本身具有极高的复杂性,尤其是在自动驾驶场景中,模型需要在不依赖特定异常类别训练的情况下,准确分割出未知对象。这种开放集分割问题要求模型具备强大的泛化能力,而现有方法在处理远距离或小尺寸异常对象时表现较差。其次,数据集的构建过程中也面临诸多挑战,例如如何确保实例标注的精确性,尤其是在复杂场景中多个异常对象重叠或遮挡的情况下。此外,OoDIS数据集需要平衡不同场景的多样性,以确保评估结果的广泛适用性。这些挑战不仅推动了异常实例分割算法的创新,也为未来研究提供了明确的方向。
常用场景
经典使用场景
OoDIS数据集主要用于自动驾驶领域中的异常实例分割任务。该数据集通过扩展现有的异常分割基准,提供了对未知对象的实例级分割标注,特别适用于在训练过程中未见的对象(如野生动物或道路上的障碍物)的识别与分割。这一任务对于自动驾驶系统的安全导航至关重要,能够帮助车辆在复杂环境中识别并避免潜在的碰撞风险。
解决学术问题
OoDIS数据集解决了自动驾驶领域中异常实例分割的学术难题。传统的语义分割方法在处理未见过的对象时表现不佳,容易将未知对象错误分类为已知类别。OoDIS通过提供实例级的分割标注,使得模型能够更精确地识别和分割单个异常对象,从而提升了对复杂场景的理解能力。这一数据集填补了异常实例分割领域的空白,推动了相关算法的研究与改进。
衍生相关工作
OoDIS数据集的发布推动了异常实例分割领域的多项经典工作。例如,UGainS、Mask2Anomaly和U3HS等方法均基于该数据集进行了算法优化与性能评估。这些方法通过结合不确定性引导、类无关实例分割等技术,显著提升了异常实例分割的精度与鲁棒性。此外,OoDIS还为后续研究提供了统一的评估基准,促进了该领域的进一步发展。
以上内容由遇见数据集搜集并总结生成


