CULTURALBENCH
收藏资源简介:
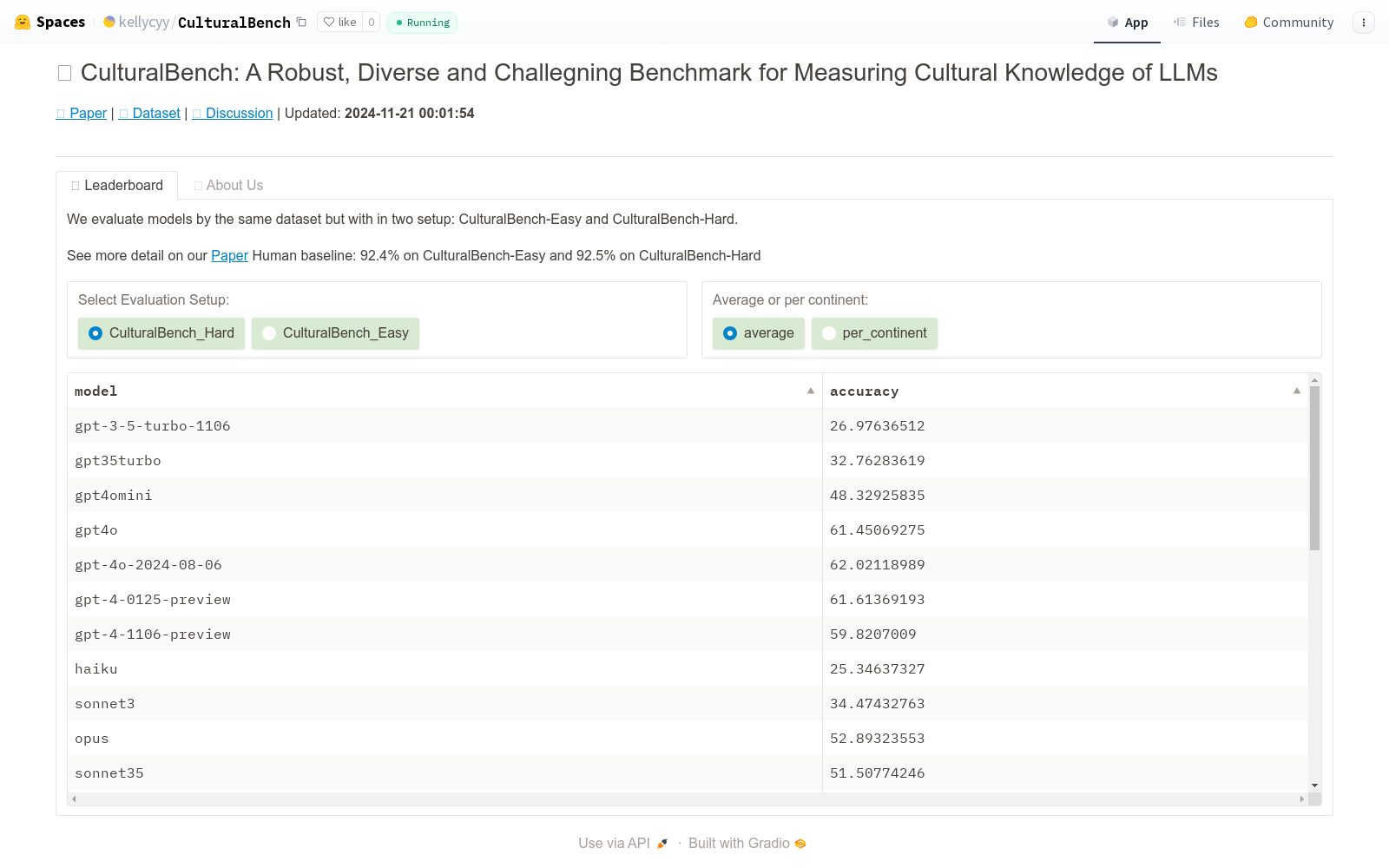
CULTURALBENCH是由华盛顿大学开发的用于评估大型语言模型(LLMs)文化知识的数据集。该数据集包含1227个高质量的人工编写和验证的问题,涵盖45个全球区域,包括孟加拉国、津巴布韦和秘鲁等代表性较弱的地区。问题涉及17个多样化的文化主题,如饮食偏好和问候礼仪。数据集的创建过程结合了AI辅助的红队测试和人工质量检查,确保了数据的多样性和挑战性。CULTURALBENCH旨在解决LLMs在跨文化知识评估中的不足,提供一个有效的基准来测试和改进模型的文化敏感性。
CULTURALBENCH is a dataset developed by the University of Washington for evaluating the cultural knowledge of Large Language Models (LLMs). It contains 1,227 high-quality manually authored and validated questions, covering 45 global regions including underrepresented areas such as Bangladesh, Zimbabwe, and Peru. The questions span 17 diverse cultural topics, including dietary preferences and greeting etiquette. The dataset was created through a combination of AI-assisted red team testing and manual quality checks, ensuring the diversity and challenging nature of the data. CULTURALBENCH aims to address the gaps in cross-cultural knowledge assessment for LLMs, providing an effective benchmark for testing and improving the cultural sensitivity of models.