MegaScience
收藏Hugging Face2025-07-23 更新2025-07-24 收录
下载链接:
https://huggingface.co/datasets/MegaScience/MegaScience
下载链接
链接失效反馈官方服务:
资源简介:
MegaScience是一个包含125万个实例的大规模高质量开源科学推理数据集。它由多个公开数据集混合而成,经过综合的数据选择和清洗过程,为科学推理任务提供了高质量的数据子集。数据集支持训练大规模模型,并在性能上超越了官方的指令模型。
MegaScience is a large-scale high-quality open-source scientific reasoning dataset containing 1.25 million instances. It is curated from multiple public datasets and has undergone a comprehensive data selection and cleaning pipeline, providing high-quality data subsets tailored for scientific reasoning tasks. This dataset supports the training of large-scale models and outperforms official instruction-tuned models in terms of performance.
创建时间:
2025-07-18
原始信息汇总
MegaScience数据集概述
基本信息
- 许可证: CC-BY-NC-SA 4.0
- 任务类别: 文本生成
- 语言: 英语
- 规模: 1M<n<10M
数据集结构
- 特征:
- question (string): 问题
- answer (string): 答案
- subject (string): 主题
- reference_answer (string): 参考答案
- source (string): 来源
- 拆分:
- train:
- 字节数: 3719840088
- 样本数: 1253230
- train:
- 下载大小: 1878947811
- 数据集大小: 3719840088
数据集描述
MegaScience是一个大规模的高质量开源数据集混合体,包含125万个实例。数据集通过以下步骤构建:
- 从NaturalReasoning、Nemotron-Science和TextbookReasoning收集源数据
- 进行问题去重和基于LLM的去污染处理
- 通过全面的消融研究确定每个数据集的最佳数据选择方法
- 使用DeepSeek-V3为NaturalReasoning和Nemotron-Science标注逐步解决方案
应用效果
- 在Llama3.1、Qwen2.5和Qwen3系列基础模型上训练后,其科学推理性能优于官方指导模型
- 对更大更强的模型表现出更好的效果,显示科学指导调优的规模效益
引用
bibtex @article{fan2025megascience, title={MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning}, author={Fan, Run-Ze and Wang, Zengzhi and Liu, Pengfei}, year={2025}, journal={arXiv preprint arXiv:2507.16812}, url={https://arxiv.org/abs/2507.16812} }
论文链接
https://arxiv.org/abs/2507.16812
搜集汇总
数据集介绍
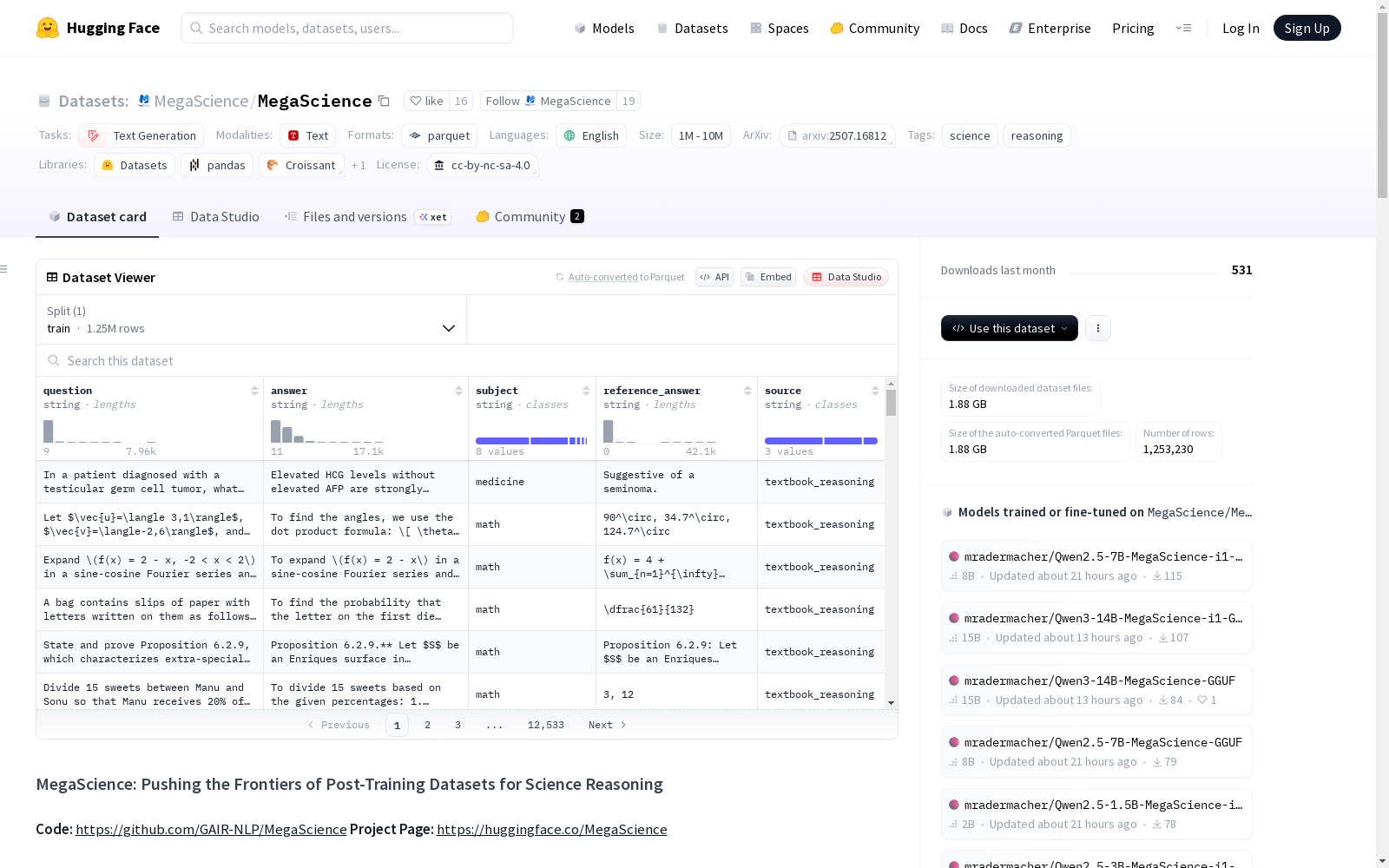
构建方式
在科学推理领域数据资源日益重要的背景下,MegaScience数据集通过系统化流程构建而成。研究团队首先整合了NaturalReasoning、Nemotron-Science和TextbookReasoning等多个优质开源数据集,采用问题去重和基于大语言模型的去污染处理确保数据纯净度。通过开展全面的消融实验,团队为每个子数据集确定了最优的数据选择方法,并运用DeepSeek-V3模型为大部分数据标注了分步解决方案,最终形成包含125万条样本的高质量科学推理数据集。
特点
作为规模突破百万的科学推理专用数据集,MegaScience展现出显著的领域特性。其核心优势体现在经过严格筛选的样本质量,每条数据均包含问题、参考答案、学科分类和来源信息等结构化字段。特别值得注意的是,该数据集通过标注分步解决方案增强了模型的推理可解释性,且实验证明其对大尺寸模型表现出明显的规模效益,模型性能随参数增长呈现持续提升趋势,为科学领域的指令微调提供了理想基准。
使用方法
该数据集主要面向科学推理任务的模型训练与评估场景。使用者可通过Git LFS工具克隆完整数据集,具体包含问题陈述、标准答案及分步推理过程等关键字段。实践应用时建议结合官方提供的监督微调指南,特别注意数据集对不同规模模型表现出的缩放特性。对于需要复现研究结果的用户,可参考项目GitHub仓库中的数据处理流程和评估方案,该方案已成功应用于Llama3.1和Qwen系列模型的性能提升。
背景与挑战
背景概述
MegaScience数据集由GAIR-NLP团队于2025年推出,旨在推动科学推理领域后训练数据集的前沿发展。该数据集整合了NaturalReasoning、Nemotron-Science和TextbookReasoning等多个高质量开源数据集,经过严格筛选和优化,最终形成包含125万条样本的大规模科学推理语料库。研究人员通过系统性的消融实验确定了各子数据集的最优选择方法,并采用DeepSeek-V3模型为多数样本标注了分步解答。该数据集的建立显著提升了开源社区在科学领域的模型表现,尤其对Llama3.1、Qwen2.5和Qwen3等大模型展现出明显的规模效益。
当前挑战
构建MegaScience数据集面临多重挑战:在领域问题层面,科学推理任务需要处理复杂的跨学科知识整合,涉及物理、化学、生物等多个学科领域的专业表述;在数据构建过程中,研究人员需解决原始数据重复问题,采用基于大语言模型的去污染技术确保数据纯净度。此外,为保持数据质量的一致性,团队需要对不同来源的异构数据进行标准化处理,并通过人工校验确保分步解答标注的准确性。这些挑战的克服为后续科学推理模型的训练奠定了坚实基础。
常用场景
经典使用场景
在科学推理领域,MegaScience数据集以其125万条高质量实例成为研究者的重要资源。该数据集通过整合多个公开数据集并优化数据选择方法,为科学问题解答和推理任务提供了丰富素材。经典应用场景包括训练大型语言模型进行科学问答、多步骤推理以及跨学科知识整合,尤其适合需要深度理解科学概念和逻辑推演的研究。
解决学术问题
MegaScience有效解决了科学教育中复杂概念理解和推理能力评估的难题。通过提供带步骤标注的解答,该数据集支持模型学习科学推理的中间过程,而非简单记忆答案。其规模和质量优势显著提升了模型在物理、化学等学科的表现,填补了开源社区在科学领域高质量训练数据的空白,为AI系统的科学素养评估设立了新基准。
衍生相关工作
MegaScience催生了多个突破性研究,包括Llama3.1和Qwen3系列模型的科学推理优化。相关衍生工作聚焦于数据选择方法的理论探索,以及步骤标注对模型解释性的影响分析。其基准测试框架已成为评估模型科学素养的主流方案,后续研究在此基础上发展了面向特定学科的专业化数据集构建方法。
以上内容由遇见数据集搜集并总结生成


