SINAI/HEP
收藏Hugging Face2024-03-22 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/SINAI/HEP
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-sa-4.0
pretty_name: HEP
configs:
- config_name: default
data_files:
- split: hepth
path: Dataset/metadata-hepth.csv
- split: hepex
path: Dataset/metadata-hepex.csv
- split: astroph
path: Dataset/metadata-astroph.csv
---
---
# HEP - High Energy Physics collection.
## Description:
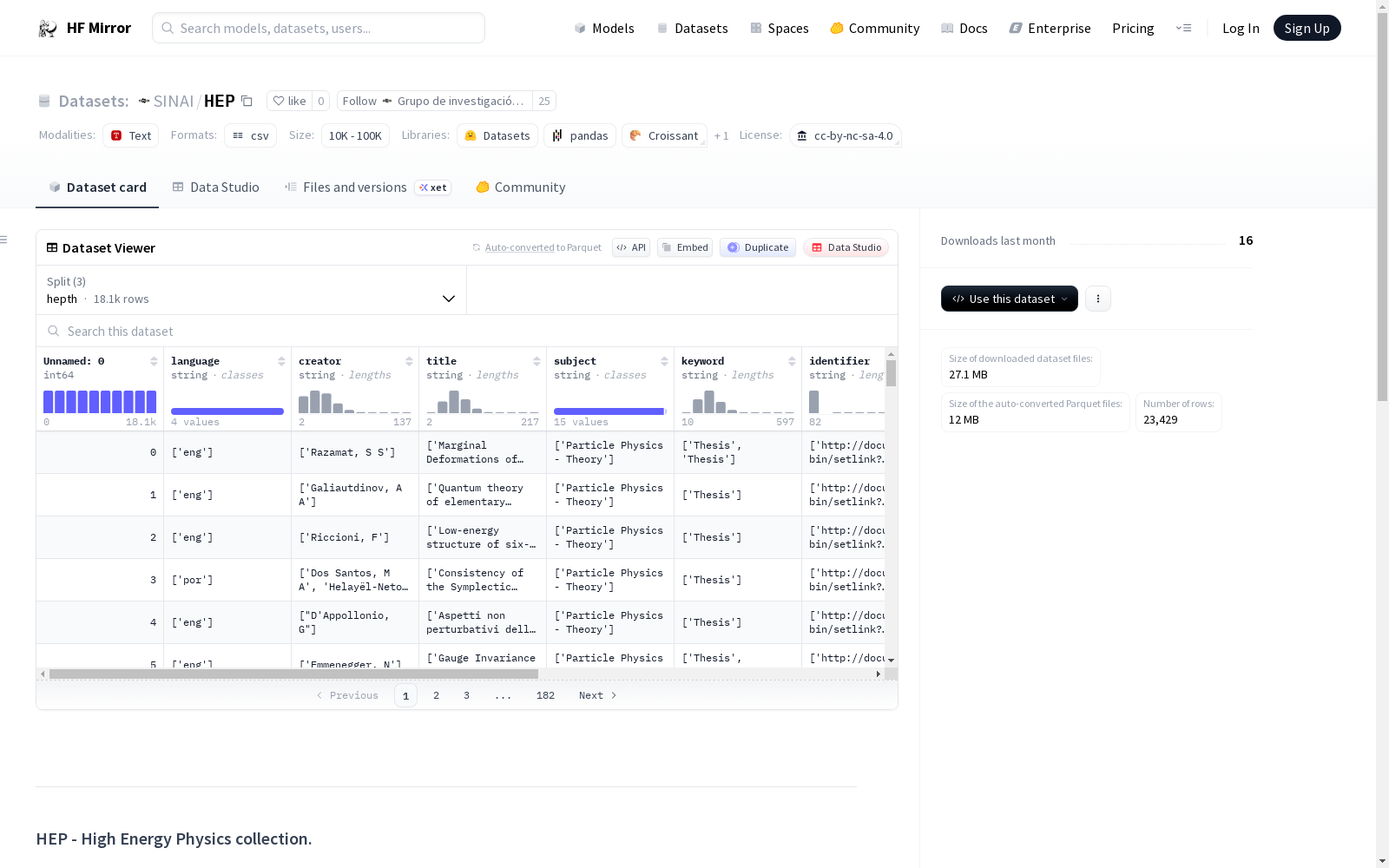
This corpus is oriented to the study of multi-labeled text classifiers. It is composed of scientific articles in the area of High Energy Physics (HEP) obtained from the CDS document server of the European Nuclear Physics Laboratory (CERN). The corpus is divided into three subsets (called partitions), where each partition is composed, in turn, of two files: one containing the records of each article (with information such as abstracts, authors and, of course, classes or keywords) in compressed XML format, and another containing a plain text version of the full article generated from the PDF available in the CERN databases (in tar + gzip format) The classes are delimited by the XML tag KEYWORD. These are the manually assigned DESY thesaurus tags. More information about the DESY thesaurus is available.
- hepth split: 18,114 Theoretical Physics documents (metadata - 5.3 Mb) (articles - 226 Mb)
- hepex split: 2,599 papers of Experimental Physics (metadata - 1.6 Mb) (articles - 28 Mb)
- astroph split: 2,716 Astrophysics documents (metadata - 1.1 Mb) (articles - 29 Mb)
### Licensing Information
HEP Collection is released under the [Apache-2.0 License](http://www.apache.org/licenses/LICENSE-2.0).
## Citation:
This corpus has been prepared by Arturo Montejo Ráez, with metadata provided by Jens Vigen and the help of the CDS Team.
```bibtex
@Article{montejo2004,
author = {Montejo-Ráez, A. and Steinberger, R. and Ureña-López, L. A.},
title = {Adaptive selection of base classifiers in one-against-all learning for large multi-labeled collections},
booktitle = {Advances in Natural Language Processing: 4th International Conference, EsTAL 2004},
pages = {1--12},
year = {2004},
editor = {Vicedo J. L. et al.},
location = {Alicante, Spain},
number = {3230},
series = {Lectures notes in artifial intelligence},
publisher = {Springer}
}
```
许可证:CC BY-NC-SA 4.0
数据集简称:HEP
配置项:
- 配置名称:default
数据文件:
- 拆分集:hepth,路径:Dataset/metadata-hepth.csv
- 拆分集:hepex,路径:Dataset/metadata-hepex.csv
- 拆分集:astroph,路径:Dataset/metadata-astroph.csv
---
---
# HEP——高能物理(High Energy Physics, HEP)数据集
## 数据集说明
本语料库面向多标签文本分类器研究,由欧洲核子研究中心(CERN)CDS文档服务器获取的高能物理领域学术文章组成。该语料库划分为三个子集(又称分区),每个子集又包含两类文件:一类为压缩XML格式的单篇文章记录文件,涵盖摘要、作者、类别与关键词等信息;另一类为从CERN数据库的PDF文件提取的完整文章纯文本版本,采用tar+gzip格式打包。类别信息通过XML标签`KEYWORD`界定,均为人工标注的DESY叙词表标签。更多关于DESY叙词表的相关信息可另行查阅。
- hepth拆分集:收录18114篇理论物理文献(元数据:5.3 Mb;文章文件:226 Mb)
- hepex拆分集:收录2599篇实验物理文献(元数据:1.6 Mb;文章文件:28 Mb)
- astroph拆分集:收录2716篇天体物理文献(元数据:1.1 Mb;文章文件:29 Mb)
### 授权信息
HEP数据集采用[Apache-2.0许可证](http://www.apache.org/licenses/LICENSE-2.0)发布。
## 引用信息
本语料库由Arturo Montejo Ráez整理,元数据由Jens Vigen提供,并得到CDS团队的协助。
bibtex
@Article{montejo2004,
author = {Montejo-Ráez, A. and Steinberger, R. and Ureña-López, L. A.},
title = {Adaptive selection of base classifiers in one-against-all learning for large multi-labeled collections},
booktitle = {Advances in Natural Language Processing: 4th International Conference, EsTAL 2004},
pages = {1--12},
year = {2004},
editor = {Vicedo J. L. et al.},
location = {Alicante, Spain},
number = {3230},
series = {Lectures notes in artifial intelligence},
publisher = {Springer}
}
提供机构:
SINAI
原始信息汇总
HEP - High Energy Physics Collection
数据集描述
该数据集旨在支持多标签文本分类器的研究,包含从欧洲核物理实验室(CERN)的CDS文档服务器获取的高能物理(HEP)领域的科学文章。数据集分为三个子集(称为分区),每个分区包含两个文件:一个包含每篇文章的记录(如摘要、作者和关键词)的压缩XML格式文件,另一个包含从CERN数据库中的PDF生成的全文纯文本版本(tar + gzip格式)。关键词由XML标签KEYWORD定义,这些标签是手动分配的DESY叙词表标签。
数据集分区
- hepth分区:包含18,114篇理论物理文档,元数据大小为5.3 Mb,文章大小为226 Mb。
- hepex分区:包含2,599篇实验物理论文,元数据大小为1.6 Mb,文章大小为28 Mb。
- astroph分区:包含2,716篇天体物理学文档,元数据大小为1.1 Mb,文章大小为29 Mb。
数据文件配置
- 默认配置:
- hepth分区:路径为
Dataset/metadata-hepth.csv - hepex分区:路径为
Dataset/metadata-hepex.csv - astroph分区:路径为
Dataset/metadata-astroph.csv
- hepth分区:路径为
许可证信息
HEP Collection 根据 Apache-2.0 License 发布。
搜集汇总
数据集介绍
构建方式
在粒子物理学研究领域,文本数据的系统化整理对于知识发现至关重要。HEP数据集构建于欧洲核子研究中心(CERN)的CDS文献服务器,通过提取高能物理学领域的科学论文形成。该数据集包含三个独立子集:理论物理学(hepth)、实验物理学(hepex)以及天体物理学(astroph)。每个子集均由两部分组成:一是采用压缩XML格式存储的元数据文件,记录摘要、作者及人工标注的DESY叙词表关键词;二是通过PDF转换生成的纯文本全文,以tar+gzip格式归档。所有关键词均通过XML标签KEYWORD进行界定,确保了标注的一致性与可解析性。
特点
作为多标签文本分类研究的重要资源,HEP数据集展现了鲜明的学科特性。其核心特点在于采用多标签标注体系,每篇论文均关联多个DESY叙词表关键词,精准反映了高能物理学文献的复杂主题分布。数据集规模较为均衡,总计涵盖两万三千余篇文献,其中理论物理学部分占据主体,实验与天体物理学文献则提供了必要的领域补充。数据以结构化元数据与原始全文并存的形式呈现,既支持基于元数据的快速分析,也允许进行深入的全文挖掘。这种设计使得数据集能够适应从关键词分类到内容理解的多层次研究需求。
使用方法
在自然语言处理与信息检索的应用场景中,HEP数据集为算法验证提供了坚实基础。研究者可依据不同子集划分训练、验证与测试数据,构建多标签文本分类模型,尤其适用于评估算法在专业科学文本上的性能。元数据文件中的结构化字段便于进行特征工程,而全文文本则支持基于深度学习的端到端建模。使用前需解压相应的压缩文件,并解析XML格式以获取关键词标签。鉴于其学术用途,该数据集遵循CC-BY-NC-SA 4.0许可协议,确保了在符合许可条款下的研究与共享。
背景与挑战
背景概述
高能物理学作为探索物质基本结构与宇宙起源的前沿领域,其研究成果常以海量学术文献形式呈现。为促进多标签文本分类方法的发展,欧洲核子研究中心(CERN)的CDS文档服务器提供了丰富的科学论文资源。在此背景下,由Arturo Montejo Ráez等研究人员于2004年构建的HEP数据集应运而生,该数据集专注于高能物理领域的文献分析,涵盖理论物理、实验物理与天体物理三大子集,旨在通过人工标注的DESY叙词表关键词,为多标签分类算法提供高质量的标注语料,从而推动自然语言处理技术在专业学术文本中的应用。
当前挑战
HEP数据集致力于解决高能物理领域学术文献的多标签分类问题,其核心挑战在于专业术语的复杂性与标签体系的层次化结构,这要求分类模型具备深度的领域知识理解能力。在构建过程中,研究人员面临数据异构性难题,包括从压缩XML格式中提取结构化元数据、将PDF文档转化为纯文本,并保持语义完整性;同时,手动依据DESY叙词表进行关键词标注需耗费大量人力,且需确保跨子集标签的一致性,以维护数据集的整体质量与可用性。
常用场景
经典使用场景
在自然语言处理与信息检索领域,HEP数据集为多标签文本分类研究提供了宝贵的实验平台。该数据集收录了来自欧洲核子研究中心的高能物理学文献,涵盖理论物理、实验物理与天体物理三大子集,每篇文献均附有手动标注的DESY叙词表关键词。研究者常利用其丰富的多标签结构,探索分类算法在复杂科学文本中的性能表现,尤其是在处理大规模、高维度标签空间时的挑战,为学术文献自动标注与组织奠定了数据基础。
实际应用
在实际应用中,HEP数据集为高能物理学领域的知识发现与文献管理提供了技术支持。基于该数据集训练的模型能够自动为新增学术文献分配关键词,辅助构建智能化的文献检索与推荐系统,显著提升科研人员获取相关资料的效率。此外,它还可用于监测学科发展趋势,通过分析标签共现模式揭示物理学子领域间的交叉联系,为科研决策与资源分配提供数据驱动的见解。
衍生相关工作
围绕HEP数据集,学术界衍生了一系列经典研究工作。例如,Montejo-Ráez等人利用该数据集提出了自适应基分类器选择方法,优化了一对多学习策略在大规模多标签集合上的性能。后续研究进一步探索了基于标签嵌入的分类模型、层次多标签学习框架以及深度学习架构在该数据集上的应用,这些工作不仅深化了对多标签分类问题的理解,也推动了自然语言处理技术在科学文本分析中的持续创新。
以上内容由遇见数据集搜集并总结生成


