VL2NL
收藏arXiv2024-01-22 更新2024-06-21 收录
下载链接:
https://hyungkwonko.info/chart-llm-data
下载链接
链接失效反馈官方服务:
资源简介:
VL2NL是由KAIST和首尔国立大学联合开发的,利用大型语言模型(LLM)框架生成自然语言数据集的工具。该数据集包含1,981个真实世界的Vega-Lite规范,旨在为数据可视化提供自然语言接口(NLI)。VL2NL通过引导发现和基于分数的改写技术,提高了数据集的语义准确性和语法多样性。该数据集不仅在复杂性和多样性上超越了现有的图表集合,还展示了在分析图表语义和生成L1/L2标题方面的高准确率。VL2NL的应用领域广泛,可用于自动生成图表描述、问题和对话,以支持数据可视化的交互和理解。
VL2NL is a tool co-developed by KAIST and Seoul National University for generating natural language datasets using Large Language Model (LLM) frameworks. This dataset contains 1,981 real-world Vega-Lite specifications, and aims to provide a Natural Language Interface (NLI) for data visualization. VL2NL improves the semantic accuracy and grammatical diversity of the dataset through guided discovery and score-based rewriting techniques. Not only does this dataset outperform existing chart collections in terms of complexity and diversity, but it also demonstrates high accuracy in analyzing chart semantics and generating L1/L2 titles. VL2NL has a wide range of application scenarios, and can be used to automatically generate chart descriptions, questions and dialogues to support the interaction and understanding of data visualization.
提供机构:
KAIST 韩国科学技术院
创建时间:
2023-09-19
搜集汇总
数据集介绍
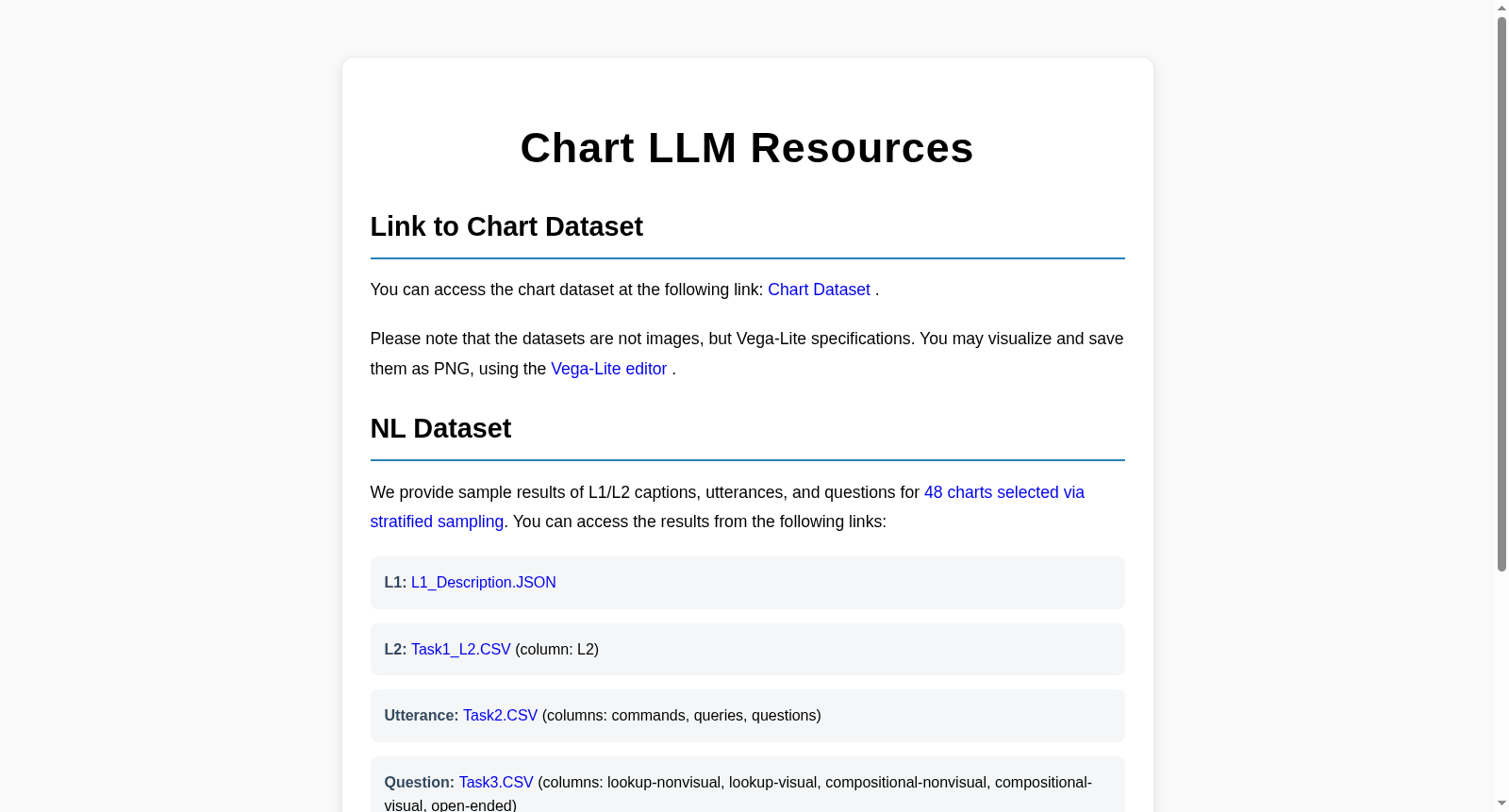
构建方式
在数据可视化自然语言接口研究领域,构建高质量的自然语言数据集是推动技术发展的关键。VL2NL数据集的构建依托于一个包含1,981个真实世界Vega-Lite规范的全新集合,这些规范通过GitHub API系统性地爬取获得。构建过程首先利用包含版本号和核心属性的多样化搜索查询,广泛收集相关代码文件。随后,通过严格的去重、许可证合规性审查以及手动有效性验证等多阶段后处理流程,确保了数据集的独特性和可复现性。最终形成的规范集合在复杂度和多样性上均超越了现有基准,其中超过86%的图表属于复杂或极其复杂级别,为生成丰富的自然语言描述提供了坚实的数据基础。
特点
VL2NL数据集的核心特点体现在其卓越的多样性和复杂性。该数据集不仅规模可观,更在结构深度上表现突出,其JSON结构的平均深度达到5.19,显著高于同类数据集。在多样性方面,它涵盖了362个独特的关键字,并拥有最高的平均配对编辑距离(1,549.48),表明图表之间在代码层面具有高度异质性。尤为突出的是,该集合包含了大量具有复合视图(746个)和交互功能(1,010个)的图表,并覆盖了从面积图到树状网络图在内的十种图表类型。这种在结构、功能和类型上的广泛覆盖,为训练能够理解复杂、交互式可视化的自然语言模型提供了前所未有的素材。
使用方法
VL2NL框架为利用该数据集生成多样化自然语言描述提供了系统化的方法。其使用流程分为三个核心阶段:首先对Vega-Lite规范及其底层数据进行预处理与最小化,以适配大语言模型的输入。随后,框架通过融入引导式发现策略,利用脚手架和关键问题提示,使大语言模型能够自主、准确地分析和整合图表语义,从而生成诸如L1/L2描述、图表生成话语及问答等多种类型的自然语言数据。最后,通过基于分数的复述技术,沿清晰度、专业性、正式度和主观性四个语言轴对生成语句进行语法层面的多样性增强。该方法支持全自动和混合主动两种模式,研究者可根据需要生成特定任务的高质量、高多样性语料,用于训练和评估自然语言接口模型。
背景与挑战
背景概述
VL2NL数据集由KAIST与首尔国立大学的研究团队于2024年提出,旨在应对数据可视化领域自然语言接口开发中高质量标注数据稀缺的挑战。该数据集以Vega-Lite规范为输入,利用大语言模型框架自动生成多样化的自然语言描述,涵盖图表标题、生成指令及问答等多种任务类型。其核心研究问题聚焦于如何高效合成兼具语义准确性与句法多样性的语言数据,以降低传统众包标注的成本与时间消耗,推动可视化自然语言交互系统的快速发展。该工作通过引入包含1981个真实世界Vega-Lite图表的集合,显著提升了数据集的复杂性与多样性,为相关领域提供了重要的基准资源。
当前挑战
VL2NL数据集致力于解决数据可视化中自然语言接口构建的挑战,其核心在于自动生成能够准确描述图表语义并覆盖多样化语言风格的自然语言数据。具体挑战包括:在领域问题层面,需确保生成的语言描述能精确对应图表的视觉编码、统计特征及交互属性,同时适应不同用户群体在专业术语、表达习惯及句式结构上的差异;在构建过程中,面临真实世界Vega-Lite图表收集与清洗的复杂性,以及如何通过引导发现与基于分数的复述技术,使大语言模型在缺乏明确模板的情况下自主产生忠实且多样的语言输出。此外,还需克服图表类型识别、复合视图解析及交互功能描述等技术难点,以保障生成数据的可靠性与实用性。
常用场景
经典使用场景
在数据可视化与自然语言处理交叉领域,VL2NL数据集框架的经典应用场景在于为可视化自然语言接口(NLIs)的研发提供高质量、多样化的训练语料。该框架通过解析Vega-Lite图表规范,自动生成涵盖图表描述、生成指令及问答等多种类型的自然语言数据,极大地简化了NLIs模型训练中数据标注的繁复流程。其生成的数据集能够精准捕捉图表语义,并模拟人类语言在清晰度、专业性、正式度及主观性等多个维度的句法变异,为构建鲁棒且用户友好的可视化交互系统奠定了坚实基础。
实际应用
在实际应用层面,VL2NL生成的数据集可直接用于微调专用语言模型,以提升其在图表类型分类、自然语言到可视化代码转换等下游任务中的性能。研究证明,将生成数据与人类标注数据结合使用,能有效提升模型准确率。此外,该框架支持全自动与混合主动两种模式,使研究人员能够根据需求快速生成大规模基准数据集,或通过交互式引导精细化控制生成内容,以填补数据分布中的稀疏区域。这为开发智能数据分析助手、无障碍图表阅读工具等实际应用提供了高效的数据生产流水线。
衍生相关工作
VL2NL框架及其伴随发布的1981个真实世界Vega-Lite图表集合,已催生并支撑了可视化与NLP交叉领域的多项经典研究工作。其生成的高质量语料被用于训练和评估各类图表描述生成模型、自然语言到可视化规范(NL2Vis)的转换模型以及图表问答系统。该框架所倡导的利用LLM生成训练数据的范式,也与“通过数据教学”的研究趋势相呼应,启发了后续研究探索如何利用合成数据扩展现有基准、提升小规模模型在特定可视化任务上的性能,推动了自动化、低成本构建领域专用数据资源的方法论发展。
以上内容由遇见数据集搜集并总结生成


