TheoTsio/Health_Misinfo
收藏Hugging Face2023-08-28 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/TheoTsio/Health_Misinfo
下载链接
链接失效反馈官方服务:
资源简介:
---
task_categories:
- text-classification
language:
- en
tags:
- health_misinformation, credibility
size_categories:
- 1K<n<10K
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The health misinfo dataset is an English Document dataset containing just over 6k unique articles related to health issues from web. This dataset was created in an effort to detect the misinformation in health documents. This dataset was created from the relevance judgment of the TREC health misinformation
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
task_categories:
- 文本分类(text-classification)
language:
- 英语(en)
tags:
- 健康错误信息(health_misinformation)、可信度(credibility)
size_categories:
- 1千至1万条(1K<n<10K)
---
# 数据集卡片(Dataset Card)
## 数据集描述
- **主页:**
- **代码仓库:**
- **相关论文:**
- **排行榜:**
- **联系人:**
### 数据集摘要
健康错误信息数据集(health misinformation dataset)是一个英语文档数据集,包含源自网络的6000余篇与健康议题相关的非重复文章。本数据集旨在检测健康文档中的错误信息,其构建基于TREC健康错误信息任务的相关性标注结果。
## 支持任务与排行榜(Supported Tasks and Leaderboards)
[需补充更多信息]
## 语言(Languages)
[需补充更多信息]
## 数据集结构(Dataset Structure)
### 数据实例(Data Instances)
[需补充更多信息]
### 数据字段(Data Fields)
[需补充更多信息]
### 数据划分(Data Splits)
[需补充更多信息]
## 数据集构建(Dataset Creation)
### 遴选依据(Curation Rationale)
[需补充更多信息]
### 源数据(Source Data)
#### 初始数据收集与标准化(Initial Data Collection and Normalization)
[需补充更多信息]
#### 源语言生产者是谁?(Who are the source language producers?)
[需补充更多信息]
### 标注(Annotations)
#### 标注流程(Annotation process)
[需补充更多信息]
#### 标注人员是谁?(Who are the annotators?)
[需补充更多信息]
### 个人与敏感信息(Personal and Sensitive Information)
[需补充更多信息]
## 数据使用注意事项(Considerations for Using the Data)
### 数据集的社会影响(Social Impact of Dataset)
[需补充更多信息]
### 偏差讨论(Discussion of Biases)
[需补充更多信息]
### 其他已知局限(Other Known Limitations)
[需补充更多信息]
## 附加信息(Additional Information)
### 数据集整理者(Dataset Curators)
[需补充更多信息]
### 许可信息(Licensing Information)
[需补充更多信息]
### 引用信息(Citation Information)
[需补充更多信息]
### 贡献(Contributions)
[需补充更多信息]
提供机构:
TheoTsio
原始信息汇总
数据集概述
数据集名称
- 名称: 健康误信息数据集
数据集描述
- 概述: 该数据集是一个包含超过6000篇独特文章的英文文档数据集,内容涉及健康问题,旨在检测健康文档中的误信息。数据集源自TREC健康误信息的相关判断。
数据集特征
- 任务类别: 文本分类
- 语言: 英语
- 标签: 健康误信息, 可信度
- 大小类别: 1K<n<10K
数据集结构
- 数据实例、数据字段、数据分割、数据创建详情: 待补充
使用数据集的考虑
- 社会影响、偏见讨论、其他已知限制: 待补充
附加信息
- 数据集管理员、许可信息、引用信息、贡献: 待补充
搜集汇总
数据集介绍
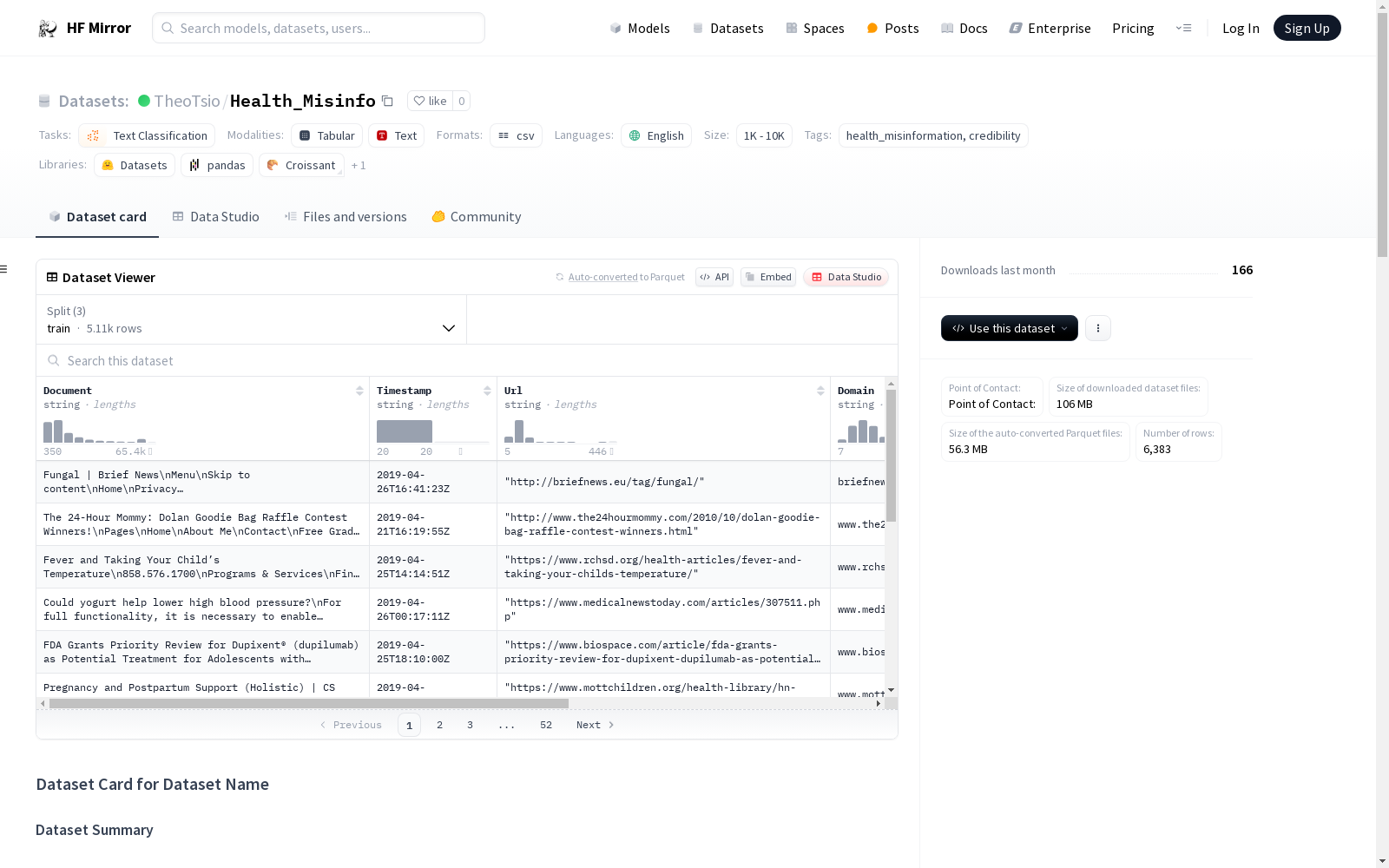
构建方式
在探索健康信息领域的真实挑战之际,该数据集通过搜集网络上关于健康问题的6k余篇独立文章,采用TREC健康误信息的相关性判断作为构建基础,旨在检测健康文献中的错误信息,从而为研究者和开发者提供了一手的素材。
特点
该数据集的一大特色在于其专注于健康领域内的误信息检测,收录的文章均为英文文档,具有较高的针对性和实用性。此外,数据集的构建充分考虑了信息的相关性判断,为后续的文本分类任务提供了可靠的数据支持。
使用方法
用户在使用该数据集时,可根据自身需求进行相应的文本分类任务,如健康信息误判检测等。数据集的具体结构和使用细节虽尚待完善,但基本的框架和目的已经明确,有助于研究者在健康信息领域开展深入的研究工作。
背景与挑战
背景概述
在健康信息日益丰富的数字化时代,错误信息的传播对公众健康构成了严重威胁。 TheoTsio/Health_Misinfo数据集应运而生,旨在通过对网络健康相关文章的收集与判断,检测并识别健康文档中的错误信息。该数据集由超过6000篇独特的英文文章组成,创建于对TREC健康错误信息相关性判断的研究项目中,由相关研究人员或机构精心编纂,为健康信息误传的检测与防范提供了宝贵的研究资源。
当前挑战
数据集在解决健康信息分类与可信度评估领域问题的同时,面临着多方面的挑战。首先,构建过程中需处理初始数据的收集与规范化,确保数据的准确性与代表性。其次,对于数据标注的过程,如何确保标注者的专业性和标注质量,以及避免标注过程中的主观偏差,是另一大挑战。此外,数据集还需关注其可能存在的偏见与社会影响,以及个人隐私信息的保护问题,这些都是数据集构建与使用过程中必须谨慎处理的重要议题。
常用场景
经典使用场景
在当前信息化时代,健康领域的虚假信息传播问题日益严峻,因此,TheoTsio/Health_Misinfo数据集应运而生。该数据集包含6000余份独特的英文健康相关文章,主要应用于文本分类任务,旨在识别和标注健康文档中的错误信息,为相关研究提供了丰富的实验材料。
衍生相关工作
基于该数据集,学术界已衍生出一系列研究工作,如构建更精确的健康信息分类模型、研究健康信息传播的规律以及分析健康谣言的社会影响等,这些工作进一步推动了健康信息领域的研究深度和广度。
数据集最近研究
最新研究方向
在健康信息领域, TheoTsio/Health_Misinfo 数据集正成为研究焦点,其汇集了6000余篇关于健康问题的独特文章,旨在检测网络健康文档中的虚假信息。该数据集的构建,源于对TREC健康虚假信息的相关性判断。当前,学术界正利用此数据集探索文本分类任务,以识别和标注健康信息的可信度,推动健康虚假信息的检测与防范研究。这一方向的研究不仅有助于提升公众健康信息的准确性,亦对构建清朗的网络环境具有重要意义。
以上内容由遇见数据集搜集并总结生成


