abacusai/HellaSwag_DPO_FewShot
收藏Hugging Face2024-02-26 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/abacusai/HellaSwag_DPO_FewShot
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
dataset_info:
features:
- name: prompt
dtype: string
- name: chosen
dtype: string
- name: rejected
dtype: string
splits:
- name: train
num_bytes: 288673226
num_examples: 119715
- name: eval
num_bytes: 74508834
num_examples: 30126
download_size: 80725728
dataset_size: 363182060
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: eval
path: data/eval-*
---

# Dataset Card for "HellaSwag_DPOP_FewShot"
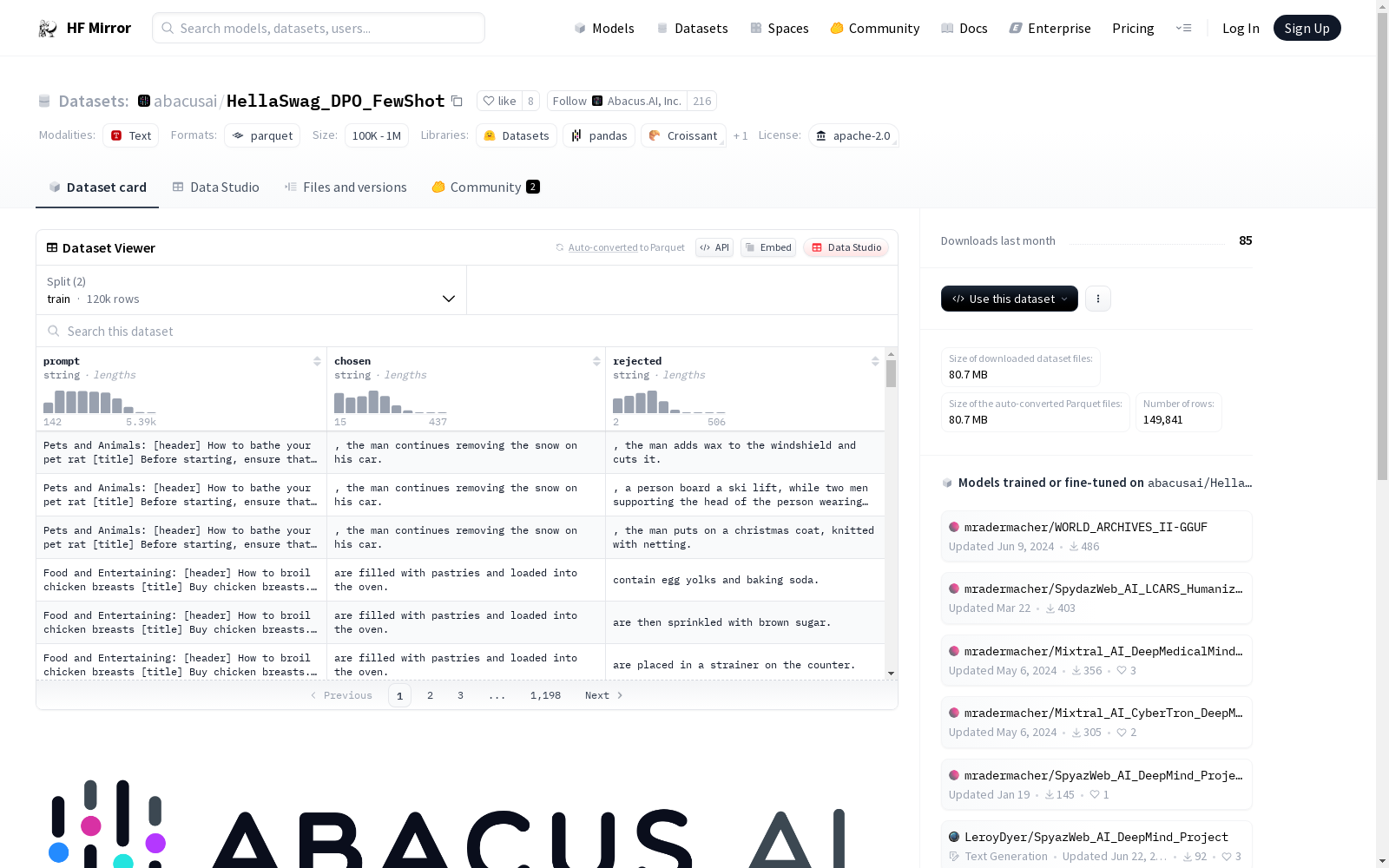
[HellaSwag](https://rowanzellers.com/hellaswag/) is a dataset containing commonsense inference questions known to be hard for LLMs.
In the original dataset, each instance consists of a prompt, with one correct completion and three incorrect completions.
We create a paired preference-ranked dataset by creating three pairs for each correct response in the training split.
An example prompt is "Then, the man writes over the snow covering the window of a car, and a woman wearing winter clothes smiles. then"
And the potential completions from the original HellaSwag dataset are:
[", the man adds wax to the windshield and cuts it.", ", a person board a ski lift, while two men supporting the head of the person wearing winter clothes snow as the we girls sled.", ", the man puts on a christmas coat, knitted with netting.", ", the man continues removing the snow on his car."]
The dataset is meant to be used to fine-tune LLMs (which have already undergone SFT) using the DPOP loss function. We used this dataset to create the [Smaug series of models](https://github.com/abacusai/smaug). See our paper for more details.
This dataset contains 119,715 training examples and 30,126 evaluation examples.
See more details in the [datasheet](https://github.com/abacusai/smaug/blob/main/datasheet.md).
许可证:Apache-2.0
数据集信息:
特征列表:
- 字段名:prompt(提示文本),数据类型:字符串
- 字段名:chosen(优选响应),数据类型:字符串
- 字段名:rejected(弃选响应),数据类型:字符串
数据集划分:
- 划分名称:训练集,字节大小:288673226,样本数量:119715
- 划分名称:评测集,字节大小:74508834,样本数量:30126
下载大小:80725728字节
数据集总大小:363182060字节
配置项:
- 配置名称:默认配置,数据文件:
- 对应划分:训练集,文件路径:data/train-*
- 对应划分:评测集,文件路径:data/eval-*

# HellaSwag_DPOP_FewShot 数据集卡片
[HellaSwag](https://rowanzellers.com/hellaswag/) 是一款常识推理问答数据集,其设计的问题对大语言模型(Large Language Model,LLM)而言颇具挑战性。在原始数据集中,每个样本均包含一段提示文本(prompt)、1个正确补全项与3个错误补全项。我们通过为训练划分(split)中的每个正确响应生成三组配对样本,构建了一款带偏好排序的配对数据集。
示例提示文本为:"Then, the man writes over the snow covering the window of a car, and a woman wearing winter clothes smiles. then"
原始HellaSwag数据集中的潜在补全项如下:[", the man adds wax to the windshield and cuts it.", ", a person board a ski lift, while two men supporting the head of the person wearing winter clothes snow as the we girls sled.", ", the man puts on a christmas coat, knitted with netting.", ", the man continues removing the snow on his car."]
本数据集旨在通过DPOP损失函数对已完成监督微调(Supervised Fine-Tuning,SFT)的大语言模型进行微调。我们依托本数据集构建了[Smaug系列模型](https://github.com/abacusai/smaug),更多细节可参阅我们的相关研究论文。
本数据集共包含119715条训练样本与30126条评测样本。
更多细节可参阅[数据集说明文档](https://github.com/abacusai/smaug/blob/main/datasheet.md).
提供机构:
abacusai
原始信息汇总
数据集卡片 "HellaSwag_DPOP_FewShot"
数据集信息
特征
- prompt: 字符串类型
- chosen: 字符串类型
- rejected: 字符串类型
分割
- train:
- 字节数: 288673226
- 样本数: 119715
- eval:
- 字节数: 74508834
- 样本数: 30126
大小
- 下载大小: 80725728
- 数据集大小: 363182060
配置
- default:
- 训练数据文件路径: data/train-*
- 评估数据文件路径: data/eval-*
数据集描述
HellaSwag 是一个包含常识推理问题的数据集,这些问题对大型语言模型(LLMs)来说很难。在原始数据集中,每个实例包含一个提示,有一个正确的完成和三个不正确的完成。我们通过为训练分割中的每个正确响应创建三个配对来创建配对偏好排序数据集。
示例提示:“然后,那个男人在覆盖汽车窗户的雪上写字,一个穿着冬装的女人微笑。然后”
原始 HellaSwag 数据集中的潜在完成包括:
[", 那个男人在挡风玻璃上添加蜡并切割它。", ", 一个人登上滑雪缆车,而两个男人支持穿着冬装的人的头部,女孩们在雪地上滑行。", ", 那个男人穿上一件圣诞外套,用网眼编织。", ", 那个男人继续清除他汽车上的雪。"]
该数据集旨在用于使用 DPOP 损失函数对已经进行过 SFT 的 LLMs 进行微调。我们使用此数据集创建了 Smaug 系列模型。更多详细信息请参阅我们的论文。
该数据集包含 119,715 个训练样本和 30,126 个评估样本。
更多详细信息请参阅 datasheet。
搜集汇总
数据集介绍
构建方式
HellaSwag_DPOP_FewShot数据集的构建基于原始HellaSwag数据集,针对每个正确答案在训练集中创建了三个配对的偏好排名。该数据集包含一个提示和四个可能的完成句子,其中一个正确,三个错误。通过这种方式,数据集旨在为机器学习模型提供细粒度的偏好学习场景。
特点
本数据集的特点在于其精心设计的配对偏好排名,这使得模型能够在细粒度上学习偏好。数据集遵循Apache-2.0许可证,包含119,715个训练示例和30,126个评估示例,规模适中,便于在合理时间内进行处理。此外,数据集通过DPOP损失函数,为LLM模型的微调提供了有效的支持。
使用方法
使用HellaSwag_DPOP_FewShot数据集,用户首先需要下载并解压数据。之后,可以根据数据集提供的路径加载训练和评估数据。该数据集适用于已经经历少量样本训练的LLM模型,通过DPOP损失函数进行微调,以提升模型在常识推理任务上的性能。详细的使用指南和模型训练步骤可以在相关论文和代码库中找到。
背景与挑战
背景概述
HellaSwag_DPOP_FewShot数据集,作为一类旨在提升大型语言模型在常识推理任务上的表现的数据集,由Abacus AI团队开发并于近期公布。该数据集的创建,旨在解决大型语言模型在处理复杂、细微的常识推理问题时所表现出的局限性,为相关领域的研究提供了新的视角和工具。数据集的构建基于HellaSwag原始数据集,通过为每个正确回答生成三个配对偏好排序,进而形成了适用于DPOP损失函数微调的格式。其研究成果已应用于Smaug系列模型的创建,对自然语言处理领域产生了积极的影响。
当前挑战
该数据集在构建过程中面临的挑战主要包括:如何精确地衡量和提升大型语言模型在常识推理任务上的性能,以及如何有效地利用DPOP损失函数进行模型微调。此外,数据集在处理原始HellaSwag数据时,需要解决如何生成配对偏好排序的问题,保证数据集的质量和可用性。在解决领域问题上,HellaSwag_DPOP_FewShot数据集挑战在于,如何使模型能够在仅有少量标注数据的情况下,准确地完成常识推理任务,这对于提升模型的泛化能力和实际应用价值具有重要意义。
常用场景
经典使用场景
在自然语言处理领域,尤其是对于大型语言模型的微调任务,HellaSwag_DPO_FewShot数据集提供了一个独特的视角。该数据集通过构建具有偏好排序的对偶示例,使得模型能够学习到在给定情境下更为合理的推断能力,从而在少样本学习的场景下,模型能够更好地理解和生成符合常识的文本。
衍生相关工作
基于HellaSwag_DPO_FewShot数据集,研究者们已经衍生出了一系列相关工作,如Smaug模型系列,这些工作进一步探索了如何在不同的任务和场景中利用该数据集进行模型的训练和评估,推动了少样本学习在自然语言处理中的应用和发展。
数据集最近研究
最新研究方向
在自然语言处理领域,细粒度commonsense推理任务一直是大型语言模型面临的挑战。HellaSwag_DPO_FewShot数据集为此提供了专门的研究平台,其通过引入DPOP损失函数对已进行少量样本微调的语言模型进行训练,旨在提高模型在复杂情境下的推理能力。近期研究集中于如何利用该数据集优化模型结构,以及提升模型对异常情境的识别与推理精度,这对于推动自然语言理解技术的发展具有重要的理论与实际意义。
以上内容由遇见数据集搜集并总结生成


