MME-Benchmarks/Video-MME-v2
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/MME-Benchmarks/Video-MME-v2
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- video-text-to-text
language:
- en
tags:
- benchmark
- video
- multimodal
- MCQ
pretty_name: Video-MME-v2
size_categories:
- 1K<n<10K
---
<p align="center">
<img src="assets/logo.png" width="100%" height="100%" alt="Video-MME-v2 logo">
</p>
<div align="center">
[](https://video-mme-v2-tmp.netlify.app)
[](https://arxiv.org/abs/2604.05015)
[](https://github.com/MME-Benchmarks/Video-MME-v2)
[](https://video-mme-v2-tmp.netlify.app/#leaderboard)
</div>
<!-- <p align="center">
<a href="https://video-mme-v2.netlify.app/">🍎 Project Page</a> |
<a href="https://arxiv.org/abs/2604.05015">📖 Paper</a> |
<a href="https://huggingface.co/datasets/MME-Benchmarks/Video-MME-v2">🤗 Dataset</a> |
<a href="https://video-mme-v2.netlify.app/#leaderboard">🏆 Leaderboard</a>
</p> -->
---
# 🤗 About This Repo
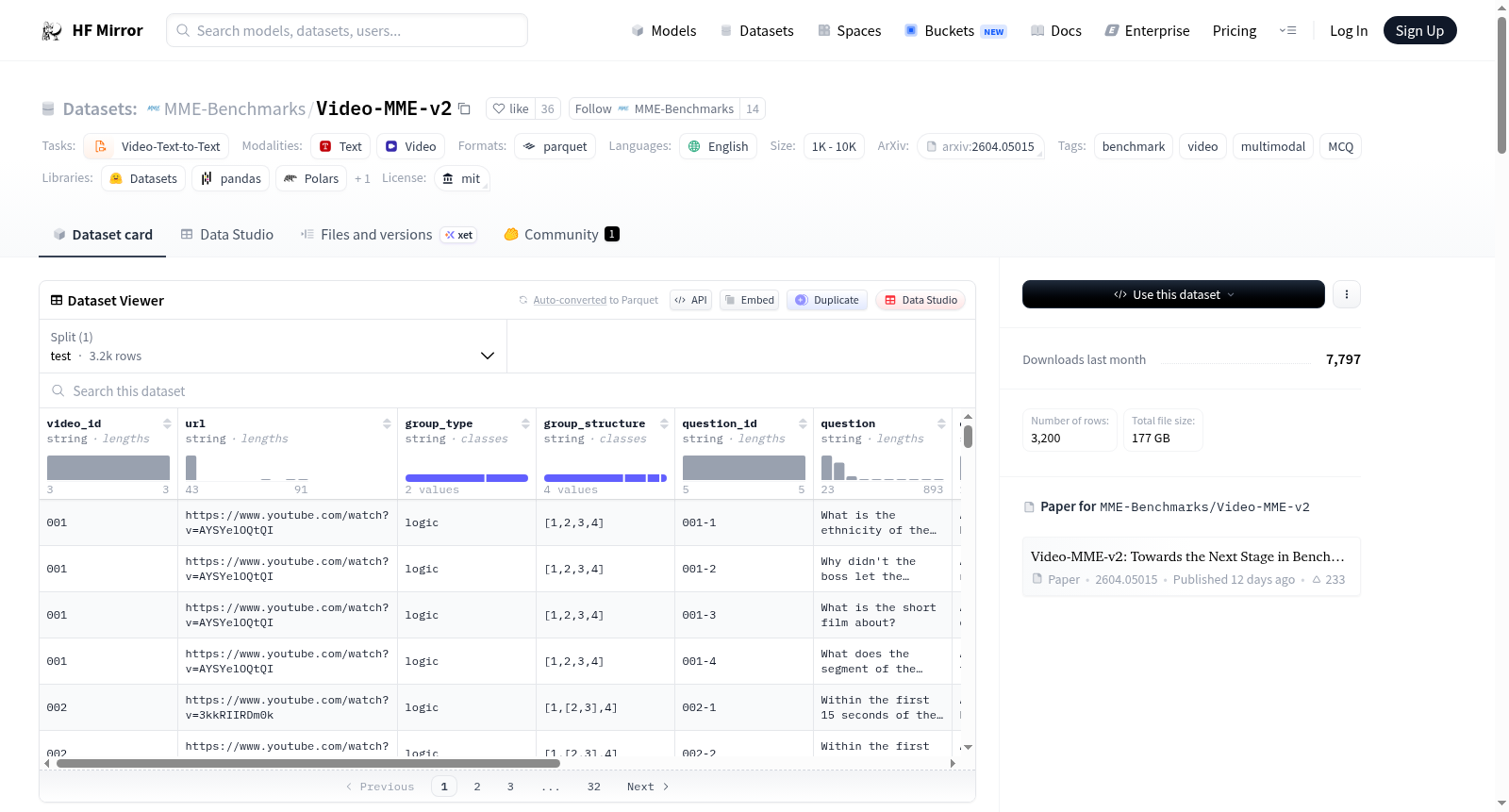
This repository contains annotation data for "[Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding](https://arxiv.org/abs/2604.05015)". It mainly consists of three parts: `videos/`, `test.parquet`, and `subtitle.zip`.
- `videos/` contains **800 1080p MP4 files**, organized sequentially into 40 zip archives. For example, `001.mp4` to `020.mp4` are stored in `001.zip`.
- `test.parquet` contains **3200 QA instances**, with each video paired with **4 questions**. Each instance includes the **question**, **options**, **answer**, and auxiliary metadata such as the **video id** and **task type**.
- `subtitle.zip` contains **800 JSONL files**, each corresponding to a unique **video id**, with word-level entries and timestamps.
---
# 🩷 About This Benchmark
In 2024, our [**Video-MME**](https://video-mme.github.io/) benchmark became a standard evaluation set for frontier models like Gemini and GPT. However, as model capabilities rapidly evolve, scores on existing benchmarks are saturating, yet a clear gap remains between **leaderboard performance and actual user experience**. This indicates that current evaluation paradigms fail to capture true video understanding abilities. To address this, we spent a year redesigning the evaluation system from first principles and now introduce **Video-MME v2**—a progressive and robust benchmark designed to drive the next generation of video understanding models.
<p align="center">
<img src="assets/teaser.png" width="100%" height="100%" alt="Teaser">
</p>
- **Dataset Size**
The dataset consists of 800 videos and 3,200 QA pairs, with each video associated with four MCQ-based questions.
- **Multi-level Evaluation Hierarchy**
- 🔍 **Level 1:** Retrieval & Aggregation
- ⏱️ **Level 2:** Level 1 + Temporal Understanding
- 🧠 **Level 3:** Level 2 + Complex Reasoning.
- **Group-based Evaluation Strategy**
- **Capability consistency groups** examine the breadth of a specific fundamental perception skill.
- **Reasoning coherence groups** assess the depth of a model’s reasoning ability.
- **Video Sources**
All videos are collected from YouTube. Over 80% were published in 2025 or later, with nearly 40% published after October 2025.
- **Video Categories**
The dataset includes four top-level domains, further divided into 31 fine-grained subcategories.
- **Metrics**
A non-linear scoring mechanism is applied to all question groups, and a first error truncation mechanism is used for reasoning coherence groups.
---
# 🍺 About a Concrete Case
> **💡 Why this example matters?**
> This video QA group demonstrates our **Reasoning Coherence** evaluation strategy and **Multi-level Hierarchy**. To answer the final state correctly, a model must successfully track the object backwards through temporal swaps. If a model guesses the initial state correctly but fails the intermediate swaps, our **first error truncation mechanism** will accurately penalize it for flawed reasoning.
<p align="left">
<a href="https://huggingface.co/datasets/MME-Benchmarks/Video-MME-v2/resolve/main/assets/demo.mp4">
<img src="assets/demo_cover.png" width="45%" alt="Demo video cover"/>
</a>
</p>
<p align="left">
<strong>👆 Click the cover image to view the demo video.</strong>
</p>
<p>
<strong>Q1:</strong> Did the ball exist underneath any of the shells?<br>
A. No.<br>
B. Yes. ✅<br>
C. Cannot be determined.
</p>
<p>
<strong>Q2:</strong> Underneath which shell was the ball located at the end?<br>
A. There is no ball under any shell.<br>
B. The third shell.<br>
C. The sixth shell.<br>
D. The second shell.<br>
E. The seventh shell.<br>
F. The fifth shell.<br>
G. The fourth shell. ✅<br>
H. The first shell.
</p>
<p>
<strong>Q3:</strong> The host performed a total of two shell swaps (defining a single swap as an instance where all shells return to an approximately straight line). Underneath which shell was the ball located after the first swap?<br>
A. There is no ball under any shell.<br>
B. The seventh shell.<br>
C. The fourth shell. ✅<br>
D. The fifth shell.<br>
E. The sixth shell.<br>
F. The second shell.<br>
G. The third shell.<br>
H. The first shell.
</p>
<p>
<strong>Q4:</strong> The host performed a total of two shell swaps (defining a single swap as an instance where all shells return to an approximately straight line). Underneath which shell was the ball located initially?<br>
A. The seventh shell.<br>
B. The fourth shell.<br>
C. The fifth shell.<br>
D. The third shell. ✅<br>
E. The second shell.<br>
F. There is no ball under any shell.<br>
G. The first shell.<br>
H. The sixth shell.
</p>
提供机构:
MME-Benchmarks
搜集汇总
数据集介绍
构建方式
在视频理解领域,随着模型性能的快速演进,现有评估基准逐渐显现出饱和趋势,难以真实反映模型的实际理解能力。Video-MME-v2数据集旨在应对这一挑战,其构建过程体现了严谨的系统设计。该数据集从YouTube平台精心采集了800个1080p分辨率的MP4格式视频,其中超过80%的视频发布于2025年之后,确保了内容的时效性与新颖性。每个视频均被配以四道多项选择题,共计形成3200个问答实例,这些实例以Parquet格式存储,并附有视频ID、任务类型等元数据。此外,数据集还提供了与每个视频对应的、包含词级条目与时间戳的JSONL格式字幕文件,为细粒度的时序分析提供了支持。整个构建流程强调从第一性原理出发,重新设计评估体系,以推动下一代视频理解模型的发展。
特点
Video-MME-v2数据集的核心特征在于其设计了一套渐进且鲁棒的多层次评估框架。数据集涵盖四个顶级领域,并进一步细分为31个精细子类别,确保了评估内容的广泛性与多样性。其评估体系构建了一个三级层次结构:第一级侧重于检索与信息聚合能力;第二级在第一级基础上引入了时序理解要求;第三级则进一步整合了复杂推理任务。这种分层设计使得评估能够系统性地衡量模型从基础感知到高级认知的递进能力。此外,数据集采用了基于组的评估策略,包括用于检验特定基础感知技能广度的能力一致性组,以及用于评估模型推理深度与连贯性的推理一致性组。在度量机制上,数据集对所有问题组应用了非线性评分方法,并对推理一致性组引入了首次错误截断机制,旨在精准识别并惩罚存在缺陷的推理过程,从而更真实地反映模型的综合理解水平。
使用方法
作为一项前沿的视频理解基准,Video-MME-v2数据集主要用于对多模态模型进行系统性评估与性能排名。研究人员或开发者可通过Hugging Face平台获取数据集,其中视频文件以压缩包形式组织,问答对存储于Parquet文件中,字幕信息则独立打包。在使用时,评估者需加载视频及其对应的四个多选题,模型需要基于视频内容进行分析并给出答案。数据集鼓励用户遵循其定义的多层次评估框架与分组策略,对模型的检索、时序理解和复杂推理能力进行分阶段测试。评估结果可提交至项目官方排行榜,以参与模型性能的比较。该基准旨在弥合排行榜分数与真实用户体验之间的差距,为衡量模型在开放域视频中的实际理解能力提供了一个标准化、可复现的测试环境。
背景与挑战
背景概述
随着多模态人工智能技术的飞速发展,视频理解已成为计算机视觉与自然语言处理交叉领域的核心前沿。由MME-Benchmarks团队于2024年提出的Video-MME基准,迅速成为评估Gemini、GPT等前沿模型视频理解能力的标准工具。然而,模型能力的快速演进导致现有基准测试分数趋于饱和,榜单性能与真实用户体验之间仍存在显著鸿沟,这揭示了当前评估范式在捕捉模型深层理解能力上的不足。为此,研究团队历时一年,从第一性原理出发重新设计评估体系,并于2025年正式推出Video-MME-v2。该数据集包含800个高清视频与3200个多项选择题对,旨在通过多层次评估层级与分组策略,系统性地衡量模型在检索聚合、时序理解与复杂推理等方面的综合能力,从而推动下一代视频理解模型的发展。
当前挑战
Video-MME-v2致力于解决视频问答领域中模型真实理解能力与表面性能指标脱节的挑战。具体而言,该领域长期面临模型虽能在静态基准上取得高分,却难以应对需要时序追踪、多步推理及上下文连贯分析的复杂现实场景。在数据集构建过程中,研究团队亦需克服多重困难:为确保评估的前沿性与时效性,超过80%的视频采集自2025年及之后发布的YouTube内容,这要求严格的版权审核与内容质量控制;同时,设计涵盖31个精细子类别的视频分类体系,并构建具有推理连贯性评估的分组问题,需在问题难度、逻辑链条与评估公平性之间取得精妙平衡。此外,实施非线性评分机制与首次错误截断策略,也对评估框架的严谨性与可解释性提出了更高要求。
常用场景
经典使用场景
在视频理解领域,Video-MME-v2数据集作为前沿基准测试工具,其经典使用场景集中于评估多模态大模型在复杂视频问答任务中的综合能力。该数据集通过精心设计的3200个多选题对,覆盖了从基础检索到深层推理的多层次理解需求,为研究者提供了系统化的模型性能检验平台。模型需解析800个高清视频内容,结合字幕时序信息,完成涉及物体追踪、事件因果推断等挑战性任务,从而精准衡量其在真实世界视频理解中的上限。
解决学术问题
该数据集有效应对了当前视频理解评估中普遍存在的基准饱和与用户体验脱节问题。通过引入三级评估层次与分组策略,它解决了传统基准难以捕捉模型时序推理与复杂逻辑能力的学术痛点。其非线性评分机制与首次错误截断设计,能够更细致地甄别模型在感知一致性与推理连贯性上的缺陷,为推动下一代视频理解模型的发展提供了可靠的度量标准,填补了评估体系与真实能力之间的关键鸿沟。
衍生相关工作
围绕Video-MME-v2数据集,已衍生出一系列推动领域进步的经典研究工作。其前身Video-MME已成为评估GPT、Gemini等前沿模型的标准集,而v2版本则进一步激发了针对视频时序理解、多步推理架构的创新。相关研究聚焦于设计更鲁棒的多模态融合机制、开发对抗基准饱和的新型训练范式,以及构建可解释的视频问答模型,这些工作共同深化了对视频内容深层语义与动态结构建模的理论与实践探索。
以上内容由遇见数据集搜集并总结生成


