structured-stern-neon-articles
收藏Hugging Face2024-10-21 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/dotwee/structured-stern-neon-articles
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含约5000篇用户撰写的文本、文章和诗歌,这些内容来自Stern NEON网站的档案。Stern NEON是一个社区平台,用户可以在上面撰写和发布自己的文章。许多文章是个人故事、诗歌或观点文章。这些文章结构化,可用于进一步分析。数据集的语言为德语,适用于文本分类、问答、文本生成和文本到文本生成任务。数据集由Lukas Wolfsteiner整理,通过抓取Stern NEON网站的多个档案(包括Wayback Machine)创建。数据集包含标题、副标题、文本、创建时间戳、作者、个人资料URL、原始URL、主类别、子类别和ID等属性。数据集可能包含个人和敏感信息,使用时需考虑潜在的偏见、风险和限制。
创建时间:
2024-10-14
原始信息汇总
Structured Stern NEON Community Articles
数据集概述
- 数据集名称: Structured Stern NEON Community Articles
- 数据集描述: 该数据集包含约5000篇用户撰写的文本、文章和诗歌,这些内容来自Stern NEON网站的存档。Stern NEON是一个社区平台,用户可以在该平台上撰写和发布自己的文章。许多文章是个人故事、诗歌或观点文章。
- 语言: 德语
- 数据集大小: 10K<n<100K
- 许可证: 未知
数据集用途
- 直接用途:
- 文本分类: 用于训练模型将文章分类到不同类别。
- 问答: 用于训练模型回答关于文章的问题。
- 文本生成: 用于训练模型生成新文章。
- 文本到文本生成: 用于训练模型生成文章摘要。
- 超出范围的用途:
- 情感分析: 数据集未标注用于情感分析任务。
- 命名实体识别: 数据集未标注用于命名实体识别任务。
- 机器翻译: 数据集未标注用于机器翻译任务。
- 语音识别: 数据集未标注用于语音识别任务。
- 图像识别: 数据集未标注用于图像识别任务。
- 对象检测: 数据集未标注用于对象检测任务。
数据集结构
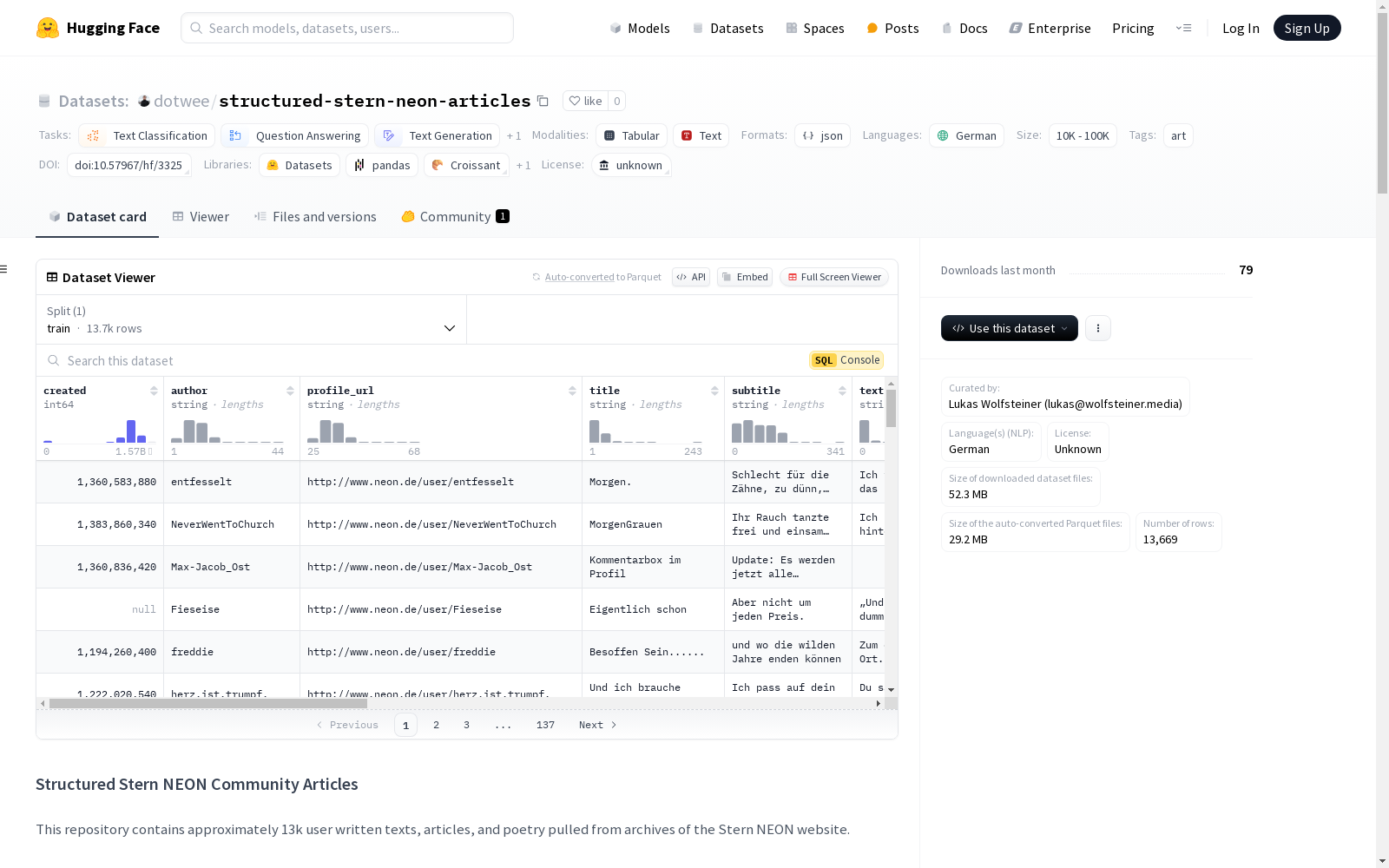
- 数据格式: 文章以行分隔的JSON对象存储。
- 文章属性:
title: 文章标题subtitle: 可选的副标题,如果没有提供则为nulltext: 文章的实际文本内容created: 发布日期的时间戳author: 作者的用户名profile_url: 作者个人资料的URLurl: 文章原始URLmain_category: 文章主类别sub_category: 文章次类别id: 文章ID
数据集创建
- 创建理由: 提供一个结构化的用户撰写文章数据集,来自Stern NEON网站。
- 数据来源: 数据集通过抓取Stern NEON网站的多个存档创建,包括Wayback Machine。
- 数据处理: 使用
waybackpyPython包访问Wayback Machine API,并从HTML页面中提取相关信息。 - 数据生产者: 数据由Stern NEON网站的用户生成,数据收集自Wayback Machine存档。
偏见、风险和限制
- 时间范围: 文章的时间范围为2009年至2016年。
- 代表性: 数据集可能不代表Stern NEON网站的当前状态。
- 敏感信息: 数据集包含个人故事和观点,可能包含敏感信息,应谨慎处理。
- 内容偏见: 数据集可能包含过时、有偏见或冒犯性内容。
- 适用性: 数据集可能不适合所有受众或研究目的。
更多信息
- 相关链接:
搜集汇总
数据集介绍
构建方式
该数据集通过从Stern NEON网站的多个存档中抓取数据构建而成,包括使用Wayback Machine的存档。数据收集过程中,使用了`waybackpy` Python包,该工具能够便捷地访问Wayback Machine API。随后,从HTML页面中提取了相关信息,并进行了结构化处理,最终形成了包含约13,000篇用户撰写的文章、诗歌和文本的数据集。每篇文章均以JSON格式存储,包含标题、副标题、正文、发布日期、作者信息、分类等详细属性。
特点
该数据集的主要特点在于其多样化的文本类型和丰富的结构化信息。数据集涵盖了个人故事、诗歌和观点文章等多种文本形式,且每篇文章均附有详细的元数据,如作者信息、发布日期、分类等。这些结构化信息为文本分类、问答系统、文本生成等自然语言处理任务提供了坚实的基础。此外,数据集的语言为德语,适用于德语相关的NLP研究。然而,数据集的时间范围为2009年至2016年,可能无法反映当前Stern NEON网站的最新状态。
使用方法
该数据集适用于多种自然语言处理任务,包括文本分类、问答系统、文本生成和文本到文本生成。用户可以通过加载JSON格式的数据,提取文章标题、正文、作者信息等字段,进行相应的模型训练和测试。例如,在文本分类任务中,可以利用文章的主分类和子分类标签进行模型训练;在问答任务中,可以根据文章内容生成问题和答案对。需要注意的是,该数据集不适用于情感分析、命名实体识别、机器翻译等任务,且在使用时应谨慎处理可能包含的个人信息和敏感内容。
背景与挑战
背景概述
Structured Stern NEON Community Articles数据集源自Stern NEON网站的用户生成内容,该网站曾是一个社区平台,用户可在此发布个人故事、诗歌及观点文章。数据集由Lukas Wolfsteiner于2016年之前整理,涵盖了2009年至2016年间的约13,000篇文章。这些文章以结构化形式存储,便于进一步分析。该数据集主要用于文本分类、问答、文本生成及文本到文本生成等自然语言处理任务,为德语文本分析提供了丰富的素材。其创建旨在为研究人员提供一个结构化的用户生成文本库,以支持多样化的文本分析研究。
当前挑战
Structured Stern NEON Community Articles数据集在构建与应用过程中面临多重挑战。首先,数据集的时效性受限,文章时间跨度为2009至2016年,可能无法反映当前的语言使用趋势或社会议题。其次,数据集中包含大量个人故事和观点,可能存在偏见或敏感信息,需谨慎处理。此外,数据集未标注情感分析、命名实体识别等任务所需的标签,限制了其在某些自然语言处理任务中的应用。数据采集过程中,依赖Wayback Machine的存档,可能导致部分数据不完整或存在误差。最后,数据集的语言仅限于德语,限制了其在多语言研究中的通用性。
常用场景
经典使用场景
Structured Stern NEON Community Articles数据集在自然语言处理领域具有广泛的应用潜力,尤其是在文本分类、问答系统、文本生成和文本到文本生成等任务中表现突出。该数据集包含了大量用户撰写的文章、诗歌和故事,这些内容为模型训练提供了丰富的语料库。通过分析这些文本,研究者可以深入探讨德语语境下的语言模式、文体特征以及用户生成内容的结构化特点。
解决学术问题
该数据集为学术研究提供了宝贵的资源,特别是在德语自然语言处理领域。它能够帮助研究者解决文本分类中的类别划分问题,提升问答系统的准确性和文本生成模型的流畅性。此外,数据集的结构化设计使得研究者能够更高效地进行数据分析和模型训练,从而推动相关领域的技术进步。
衍生相关工作
基于Structured Stern NEON Community Articles数据集,研究者已经开展了一系列相关研究。例如,利用该数据集训练的文本分类模型在德语文本分类任务中取得了显著的效果提升。此外,该数据集还被用于开发基于深度学习的文本生成模型,这些模型能够生成高质量的德语文章和诗歌。这些研究不仅推动了自然语言处理技术的发展,也为德语文学研究提供了新的视角。
以上内容由遇见数据集搜集并总结生成


