雅鲁藏布江-长江-朋曲重矿物化学成分能谱数据集
收藏国家青藏高原科学数据中心2025-04-25 更新2024-03-06 收录
下载链接:
https://data.tpdc.ac.cn/zh-hans/data/a33f8f93-b4b8-4597-af5d-345b1116a61e
下载链接
链接失效反馈官方服务:
资源简介:
砂和砂岩广泛分布在海洋和陆地,是构成石油、天然气、地下水和砂岩型铀矿的主要储集层。砂和砂岩的重矿物记录了这些物质的产生、搬运和沉积的历史。通过研究砂和砂岩的重矿物,可以重塑源区的性质、追踪沉积迁移路径、绘制沉积物扩散模式、理解特殊的水力状况、定位潜在经济矿体,因而具有重要的研究价值。重矿物具有种类复杂、类型多样、稳定性差异大、颗粒粒径小、物理形态多变、颜色复杂、区域性分布等特征。长期以来,重矿物种类的快速、精确鉴定一直是地质学领域的一个技术瓶颈。无论是光学显微镜鉴定还是元素分析、光谱测试等,不仅要求较高的专业水平,并且耗时费力,测试经费居高不下,对实验仪器性能也要求很高。这严重限制了重矿物分析的广泛运用。 随着人工智能技术的快速发展,重矿物智能识别软件开发成为了可能。从描述重矿物化学组成的定点X射线能谱分析(EDS)开展重矿物自动识别方法的探索性研究,以求获得更为高效、精准且经济的重矿物智能识别软件技术。
第二次青藏高原综合科学考察研究任务二“亚洲水塔动态变化与影响” 所属专题“水系固体物质源-汇过程与演变”专门设置子专题“河流沙重矿物自动判别方法研究”(子专题编号:2019QZKK020405)来开展河流沙重矿物智能判别方法的研究。本数据集为开展此项研究专门测试、开发更为高效且精准的重矿物智能识别软件技术。
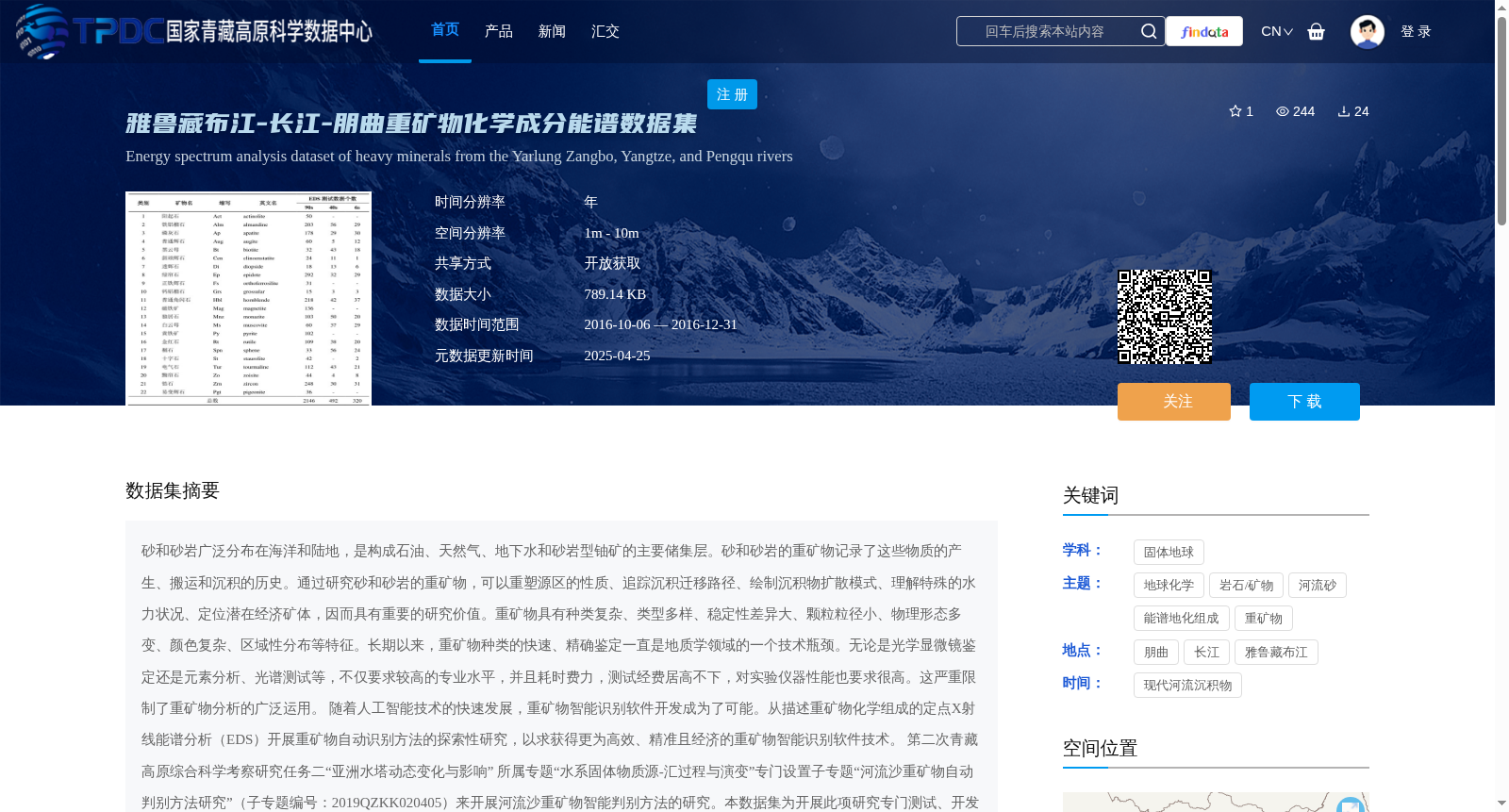
该数据集样本来自雅鲁藏布江(16A063,N29°19′13.5″,E88°51′28.4″,日喀则丛松村心滩沉积)、朋曲河(16B027,N28°09′35.96″,E87°20′45.87″,定日县曲当乡边滩沉积)、长江(16A001,N32°10′0.02″,E118°58′41.61″;南京栖霞山边滩)。使用南京大学内生金属矿床成矿机制研究国家重点实验室的场发射电镜Carl Zeiss Supra 55与能谱仪Oxford Aztec X-Max 150,在加速电压15Kv、束流60A环境下对所制重矿物靶样进行无标样能量散射X射线光谱定性和定量分析,分析时间分别为90秒、40秒和6秒,获得不同分析时间下重矿物中矿物元素的质量分数数据,包括22类重矿物共2256个颗粒。该数据集包含的河流砂重矿物类别为锆石、磷灰石、独居石、金红石、榍石、磁铁矿、黄铁矿、十字石、电气石、白云母、黑云母、普通辉石、斜顽辉石、透辉石、易变辉石、正铁辉石、铁铝榴石、钙铝榴石、普通角闪石、阳起石、绿帘石、黝帘石。EDS测试的元素氧化物含量包括50类:Ag2O, Al2O3, As2O3, Au2O3, BaO, Br2O5, CaO, Ce2O3, CoO, Cr2O3, Dy2O3, Eu2O3, Er2O3, FeO, Gd2O3, HfO2, HgO, In2O3, IrO2, K2O, La2O3, MgO, MnO, Na2O, NaO, Nb2O5, Nd2O3, OsO2, P2O5, Pm2O3, Pr2O3, PtO2, Rb2O, Ru203, Sc2O3, SiO2, Sm2O3, SO3, Ta2O5, TeO2, ThO2, TiO2, Tl2O, UO3, V2O5, WO3, Y2O3, Yb2O3, ZrO2, ZnO。
本研究采用传统机器学习方法对重矿物的能谱数据进行自动分类识别。通过对不同分类器、不同决策因素、不同地区的数据进行对比试验,提出选择26个元素成分作为决策属性,采用随机森林算法可以很好地区分不同种类的重矿物。运用不同的机器学习方法对不同测试时间获得的能谱数据对比分析发现,测试6秒获得的能谱数据的分类效果与40秒和90秒有近似的效果,这为将来缩短实验的时间与成本、提高重矿物鉴定与量化分析效率提供了理论依据。针对河流砂重矿物分类中存在的单个流域带标记训练样本不足、带标记的重矿物样本数量稀少的问题,将每个流域的重矿物分类视为一个单独的任务,提出了一种多任务学习方法MTMC,捕获流域共享和流域特有的重矿物特征,联合训练各任务模型参数,可以有效提高每个流域和每个重矿物分类预测性能和分类准确性。
该数据集不仅对于认识青藏高原不同支流河流砂中重矿物的类别和组成,研究河流沉积物从源到汇搬运过程具有重要意义,还为快速、经济、准确地智能识别重矿物的优化算法提供了数据基础和依据,未来在更为高效、精准且经济的重矿物智能识别软件技术的研发上具有重要的科学意义和社会应用价值。
本数据集相关的论文发表在:Huizhen Hao, Ronghua Guo, Qing Gu, Xiumian Hu. Machine learning application to automatically classify heavy minerals in river sand by using SEM/EDS data. Minerals Engineering, 2019, 143, 105899. https://doi.org/10.1016/j.mineng.2019.105899.
Sand and sandstone are widely distributed in marine and terrestrial environments, and serve as the primary reservoirs for petroleum, natural gas, groundwater, and sandstone-type uranium deposits. Heavy minerals in sand and sandstone record the history of their generation, transportation, and deposition. Research on heavy minerals in sand and sandstone holds significant research value, as it allows reconstruction of source region properties, tracing of sediment migration paths, mapping of sediment dispersal patterns, understanding of specific hydraulic conditions, and localization of potential economic ore bodies.
Heavy minerals are characterized by complex and diverse species, large differences in stability, small particle sizes, variable physical morphologies, complex colors, and regional distribution.
For a long time, rapid and accurate identification of heavy mineral species has been a technical bottleneck in geology. Identification methods such as optical microscopy, elemental analysis, and spectral testing not only require high professional expertise, but are also time-consuming, labor-intensive, costly, and demand high-performance experimental instruments. These factors severely limit the widespread application of heavy mineral analysis.
With the rapid development of artificial intelligence technology, the development of intelligent heavy mineral recognition software has become feasible. An exploratory study on automatic heavy mineral recognition methods was conducted using energy-dispersive X-ray spectroscopy (EDS) that characterizes the chemical composition of heavy minerals, aiming to develop more efficient, accurate, and economical intelligent heavy mineral recognition software technologies.
The Second Tibetan Plateau Scientific Expedition and Research (STEP) Program, Task 2 "Dynamic Changes and Impacts of the Asian Water Tower", under the special topic "Source-Sink Processes and Evolution of Solid Materials in River Systems", has established a sub-topic "Research on Automatic Identification Methods of Heavy Minerals in River Sand" (Sub-topic No. 2019QZKK020405) to conduct research on intelligent identification methods for heavy minerals in river sand. This dataset was specifically developed and tested for this research to facilitate the creation of more efficient and accurate intelligent heavy mineral recognition software technologies.
The samples of this dataset were collected from the Yarlung Zangbo River (16A063, N29°19′13.5″, E88°51′28.4″, mid-channel bar deposit at Congsong Village, Xigazê), the Pengqu River (16B027, N28°09′35.96″, E87°20′45.87″, marginal bar deposit at Qudang Township, Dingri County), and the Yangtze River (16A001, N32°10′0.02″, E118°58′41.61″; marginal bar deposit at Qixiashan, Nanjing).
Using the field-emission scanning electron microscope Carl Zeiss Supra 55 and energy dispersive spectrometer Oxford Aztec X-Max 150 from the State Key Laboratory of Mineral Deposit Research at Nanjing University, qualitative and quantitative analyses of the prepared heavy mineral target samples were performed via standardless energy-dispersive X-ray spectroscopy, under the conditions of an accelerating voltage of 15 kV and beam current of 60 nA. The analysis durations were 90 s, 40 s, and 6 s, respectively, yielding mass fraction data of mineral elements in heavy minerals under different analysis times. The dataset includes a total of 2256 particles belonging to 22 categories of heavy minerals.
The heavy mineral categories in river sand included in this dataset are zircon, apatite, monazite, rutile, titanite, magnetite, pyrite, staurolite, tourmaline, muscovite, biotite, augite, enstatite, diopside, pigeonite, ferrosilite, almandine, grossular, hornblende, actinolite, epidote, and zoisite.
The elemental oxide contents measured by EDS include 50 categories: Ag2O, Al2O3, As2O3, Au2O3, BaO, Br2O5, CaO, Ce2O3, CoO, Cr2O3, Dy2O3, Eu2O3, Er2O3, FeO, Gd2O3, HfO2, HgO, In2O3, IrO2, K2O, La2O3, MgO, MnO, Na2O, NaO, Nb2O5, Nd2O3, OsO2, P2O5, Pm2O3, Pr2O3, PtO2, Rb2O, Ru2O3, Sc2O3, SiO2, Sm2O3, SO3, Ta2O5, TeO2, ThO2, TiO2, Tl2O, UO3, V2O5, WO3, Y2O3, Yb2O3, ZrO2, ZnO.
This study employed traditional machine learning methods for automatic classification and recognition of heavy mineral spectral data. Through comparative experiments using different classifiers, decision factors, and data from different regions, it was proposed that selecting 26 elemental components as decision attributes and using the Random Forest algorithm can effectively distinguish between different types of heavy minerals.
Comparative analysis of spectral data obtained from different test durations using different machine learning methods revealed that the classification performance of spectral data from 6-second tests is similar to that of 40-second and 90-second tests. This provides a theoretical basis for reducing experimental time and costs, and improving the efficiency of heavy mineral identification and quantitative analysis in the future.
To address the issues of insufficient labeled training samples and scarcity of labeled heavy mineral samples for heavy mineral classification in river sand, this study treated heavy mineral classification for each river basin as an individual task, and proposed a multi-task learning method MTMC. This method captures both basin-shared and basin-specific heavy mineral characteristics, and jointly trains the model parameters of each task, effectively improving the classification prediction performance and accuracy for each basin and each heavy mineral category.
This dataset is not only of great significance for understanding the categories and compositions of heavy minerals in river sands of different tributaries on the Tibetan Plateau, and for studying the source-to-sink transportation processes of river sediments, but also provides a data foundation and reference for optimizing algorithms for rapid, economical, and accurate intelligent heavy mineral recognition. It holds important scientific significance and social application value for the future development of more efficient, accurate, and economical intelligent heavy mineral recognition software technologies.
The paper related to this dataset has been published as: Huizhen Hao, Ronghua Guo, Qing Gu, Xiumian Hu. Machine learning application to automatically classify heavy minerals in river sand by using SEM/EDS data. Minerals Engineering, 2019, 143, 105899. https://doi.org/10.1016/j.mineng.2019.105899.
提供机构:
郝慧珍,胡修棉,赖文,郭荣华
创建时间:
2022-05-18
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含雅鲁藏布江、长江和朋曲河流砂中22类重矿物的化学成分能谱数据,共2256个颗粒,用于支持重矿物智能识别技术的研究和开发。
以上内容由遇见数据集搜集并总结生成


