tner/bc5cdr
收藏Hugging Face2022-07-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/tner/bc5cdr
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
task_categories:
- token-classification
task_ids:
- named-entity-recognition
pretty_name: BioCreative V CDR
---
# Dataset Card for "tner/bc5cdr"
## Dataset Description
- **Repository:** [T-NER](https://github.com/asahi417/tner)
- **Paper:** [https://academic.oup.com/database/article/doi/10.1093/database/baw032/2630271?login=true](https://academic.oup.com/database/article/doi/10.1093/database/baw032/2630271?login=true)
- **Dataset:** BioCreative V CDR
- **Domain:** Biomedical
- **Number of Entity:** 2
### Dataset Summary
BioCreative V CDR NER dataset formatted in a part of [TNER](https://github.com/asahi417/tner) project.
The original dataset consists of long documents which cannot be fed on LM because of the length, so we split them into sentences to reduce their size.
- Entity Types: `Chemical`, `Disease`
## Dataset Structure
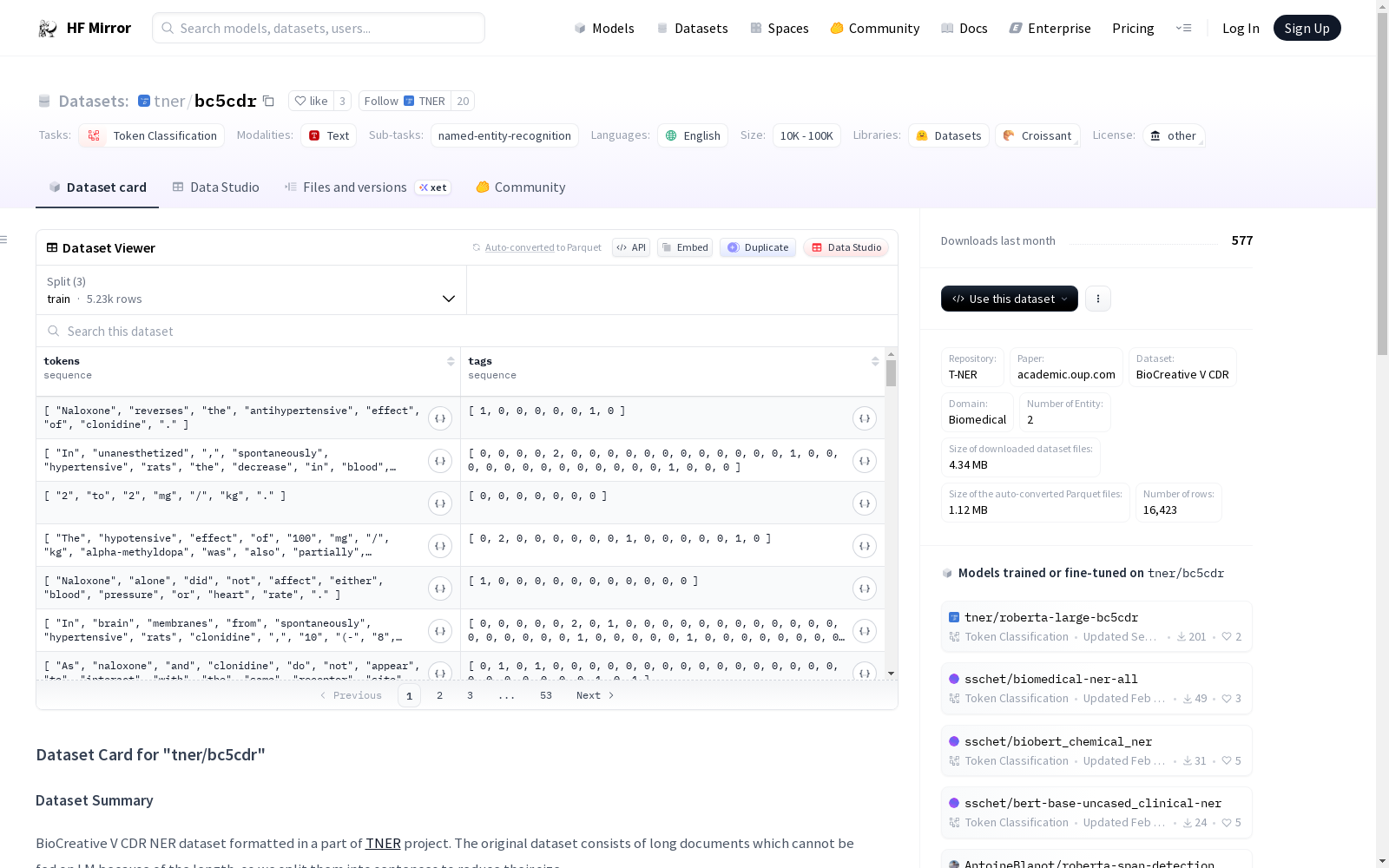
### Data Instances
An example of `train` looks as follows.
```
{
'tags': [2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0],
'tokens': ['Fasciculations', 'in', 'six', 'areas', 'of', 'the', 'body', 'were', 'scored', 'from', '0', 'to', '3', 'and', 'summated', 'as', 'a', 'total', 'fasciculation', 'score', '.']
}
```
### Label ID
The label2id dictionary can be found at [here](https://huggingface.co/datasets/tner/bc5cdr/raw/main/dataset/label.json).
```python
{
"O": 0,
"B-Chemical": 1,
"B-Disease": 2,
"I-Disease": 3,
"I-Chemical": 4
}
```
### Data Splits
| name |train|validation|test|
|---------|----:|---------:|---:|
|bc5cdr|5228| 5330|5865|
### Citation Information
```
@article{wei2016assessing,
title={Assessing the state of the art in biomedical relation extraction: overview of the BioCreative V chemical-disease relation (CDR) task},
author={Wei, Chih-Hsuan and Peng, Yifan and Leaman, Robert and Davis, Allan Peter and Mattingly, Carolyn J and Li, Jiao and Wiegers, Thomas C and Lu, Zhiyong},
journal={Database},
volume={2016},
year={2016},
publisher={Oxford Academic}
}
```
---
语言:
- 英语
许可协议:
- 其他
多语言属性:
- 单语言
样本量范围:
- 10K < n < 100K
任务类别:
- 词元分类(Token Classification)
任务子类型:
- 命名实体识别(Named Entity Recognition)
展示名称: BioCreative V CDR
---
# 数据集卡片:「tner/bc5cdr」
## 数据集说明
- **代码仓库**:[T-NER](https://github.com/asahi417/tner)
- **相关论文**:[https://academic.oup.com/database/article/doi/10.1093/database/baw032/2630271?login=true](https://academic.oup.com/database/article/doi/10.1093/database/baw032/2630271?login=true)
- **数据集名称**:BioCreative V CDR
- **应用领域**:生物医学领域
- **实体类别数量**:2
### 数据集概述
BioCreative V CDR 命名实体识别(Named Entity Recognition)数据集,采用[T-NER](https://github.com/asahi417/tner)项目的格式进行组织。原始数据集包含过长的长文档,受限于长度无法直接输入至大语言模型(Large Language Model,LLM)中,因此我们将其拆分为句子以压缩样本规模。
- 实体类型:`Chemical`(化学物质)、`Disease`(疾病)
## 数据集结构
### 数据样例
训练集的一条样例如下:
{
'tags': [2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0],
'tokens': ['Fasciculations', 'in', 'six', 'areas', 'of', 'the', 'body', 'were', 'scored', 'from', '0', 'to', '3', 'and', 'summated', 'as', 'a', 'total', 'fasciculation', 'score', '.']
}
### 标签ID映射
标签与ID的映射关系可参见[此处](https://huggingface.co/datasets/tner/bc5cdr/raw/main/dataset/label.json):
python
{
"O": 0,
"B-Chemical": 1,
"B-Disease": 2,
"I-Disease": 3,
"I-Chemical": 4
}
### 数据划分
| 数据集名称 | 训练集样本数 | 验证集样本数 | 测试集样本数 |
|---------|----:|---------:|---:|
| bc5cdr | 5228 | 5330 | 5865 |
### 引用信息
@article{wei2016assessing,
title={Assessing the state of the art in biomedical relation extraction: overview of the BioCreative V chemical-disease relation (CDR) task},
author={Wei, Chih-Hsuan and Peng, Yifan and Leaman, Robert and Davis, Allan Peter and Mattingly, Carolyn J and Li, Jiao and Wiegers, Thomas C and Lu, Zhiyong},
journal={Database},
volume={2016},
year={2016},
publisher={Oxford Academic}
}
提供机构:
tner
原始信息汇总
数据集概述
数据集描述
- 名称: BioCreative V CDR
- 领域: 生物医学
- 实体类型:
Chemical,Disease - 数据处理: 原始数据集包含长文档,因长度限制无法直接用于语言模型,因此被分割成句子以减小尺寸。
数据集结构
数据实例
-
示例:
{ tags: [2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0], tokens: [Fasciculations, in, six, areas, of, the, body, were, scored, from, 0, to, 3, and, summated, as, a, total, fasciculation, score, .] }
标签ID
- 标签映射: python { "O": 0, "B-Chemical": 1, "B-Disease": 2, "I-Disease": 3, "I-Chemical": 4 }
数据分割
| 名称 | 训练 | 验证 | 测试 |
|---|---|---|---|
| bc5cdr | 5228 | 5330 | 5865 |
引用信息
@article{wei2016assessing, title={Assessing the state of the art in biomedical relation extraction: overview of the BioCreative V chemical-disease relation (CDR) task}, author={Wei, Chih-Hsuan and Peng, Yifan and Leaman, Robert and Davis, Allan Peter and Mattingly, Carolyn J and Li, Jiao and Wiegers, Thomas C and Lu, Zhiyong}, journal={Database}, volume={2016}, year={2016}, publisher={Oxford Academic} }
搜集汇总
数据集介绍
构建方式
在生物医学信息抽取领域,BioCreative V CDR数据集作为化学与疾病实体识别任务的重要基准,其构建过程体现了严谨的学术规范。原始数据集由长篇幅的生物医学文献摘要构成,鉴于语言模型对输入长度的限制,研究团队通过句子分割技术对文档进行了预处理,将每个摘要拆分为独立的句子单元,从而生成适合模型训练的序列化数据。这一处理不仅保留了原文的语义完整性,还确保了实体标注在句子层面的连续性,为后续的命名实体识别研究提供了结构化的基础。
特点
该数据集聚焦于生物医学文本中的两类核心实体——化学物质与疾病,其标注体系采用经典的BIO(Begin, Inside, Outside)格式,精准区分实体的边界与类型。数据规模适中,包含超过一万个训练、验证与测试样本,覆盖了多样化的生物医学语境。经过句子级分割后,数据实例长度显著缩短,有效缓解了语言模型因序列过长而产生的计算负担,同时保持了实体分布的原始特征,为模型在有限上下文内的性能评估提供了可靠依据。
使用方法
研究人员可通过HuggingFace平台直接加载该数据集,利用其预定义的训练、验证与测试划分进行模型开发与评估。典型应用流程包括:将文本令牌化后,根据提供的标签映射字典将实体类别转换为数值标识,进而训练序列标注模型(如BERT等预训练模型的变体)以识别化学与疾病实体。数据集的标准化格式确保了与主流自然语言处理工具链的无缝集成,支持端到端的实验复现与结果比较,有力推动了生物医学实体识别技术的迭代与创新。
背景与挑战
背景概述
BioCreative V CDR数据集诞生于2016年,由美国国家生物技术信息中心等机构的科研团队共同构建,旨在推动生物医学文本挖掘领域的发展。该数据集聚焦于化学物质与疾病实体识别这一核心研究问题,通过标注大量科学文献摘要,为后续关系抽取任务奠定基础。其出现显著提升了生物医学命名实体识别的精度,成为该领域评估模型性能的重要基准之一,对药物发现和临床信息学产生了深远影响。
当前挑战
该数据集致力于解决生物医学文本中化学物质与疾病实体识别的挑战,其难点在于专业术语的多样性和表述的复杂性,例如同义词、缩写及嵌套结构频繁出现,对模型的语义理解能力提出较高要求。在构建过程中,面临标注一致性与质量控制的难题,需依赖领域专家进行精细标注,同时原始文档长度过长,需通过句子分割以适应语言模型的输入限制,这增加了数据预处理的复杂度。
常用场景
经典使用场景
在生物医学信息抽取领域,BioCreative V CDR数据集作为化学与疾病实体识别任务的核心基准,常被用于评估命名实体识别模型的性能。该数据集通过标注化学物质和疾病实体,为研究者提供了标准化的测试平台,尤其在处理生物医学文献时,模型能够精准识别复杂术语,如药物名称与病理状态,从而支撑下游关系抽取任务。其句子级别的分割设计,有效缓解了长文档输入的限制,使得基于预训练语言模型的微调成为可能,推动了实体识别技术在生物医学文本中的深入应用。
解决学术问题
该数据集主要解决了生物医学文本中化学与疾病实体识别的标准化评估难题,为学术研究提供了统一的标注框架。通过明确界定化学物质和疾病两类实体,它帮助研究者克服了生物医学术语歧义性高、命名不规范等挑战,促进了实体识别算法的比较与优化。其意义在于建立了可重复的实验基准,加速了自然语言处理技术在生物医学领域的融合,为药物发现、疾病机制探索等研究提供了可靠的数据基础,推动了跨学科知识发现的发展。
衍生相关工作
基于BioCreative V CDR数据集,衍生了一系列经典研究工作,包括基于深度学习的实体识别模型优化,如BiLSTM-CRF和BERT变体的微调实验。这些工作进一步扩展了数据集的用途,例如结合关系抽取任务构建端到端的生物医学知识图谱,或用于迁移学习以提升小样本场景下的性能。此外,该数据集还激发了跨语言和跨领域的适配研究,推动了生物医学自然语言处理社区的协作与发展,为后续更复杂的生物实体识别任务奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


