IIIT-AR-13K
收藏arXiv2020-08-06 更新2024-06-21 收录
下载链接:
http://cvit.iiit.ac.in/usodi/iiitar13k.php
下载链接
链接失效反馈官方服务:
资源简介:
IIIT-AR-13K数据集是由国际信息技术研究所视觉信息中心创建,专注于商业文档中的图形对象检测,特别是年度报告。该数据集包含13000个手动标注的页面,涵盖五种不同类别的图形对象:表格、图表、自然图像、标志和签名。数据集的创建涉及从多个公司和多种语言的公开年度报告中随机选择文档,并手动标注图形对象的边界框。IIIT-AR-13K数据集的应用领域包括商业文档和科技文章中的图形对象检测,旨在提高自动处理商业文档的效率和准确性。
The IIIT-AR-13K dataset was developed by the Visual Information Center at the International Institute of Information Technology, focusing on graphical object detection in business documents, particularly annual reports. This dataset contains 13,000 manually annotated pages, covering five categories of graphical objects: tables, charts, natural images, logos, and signatures. The construction of the dataset involves randomly selecting documents from public annual reports of multiple companies across various languages, followed by manual annotation of bounding boxes for graphical objects. Application scenarios of the IIIT-AR-13K dataset include graphical object detection in business documents and scientific articles, aiming to improve the efficiency and accuracy of automated business document processing.
提供机构:
国际信息技术研究所视觉信息中心
创建时间:
2020-08-06
搜集汇总
数据集介绍
构建方式
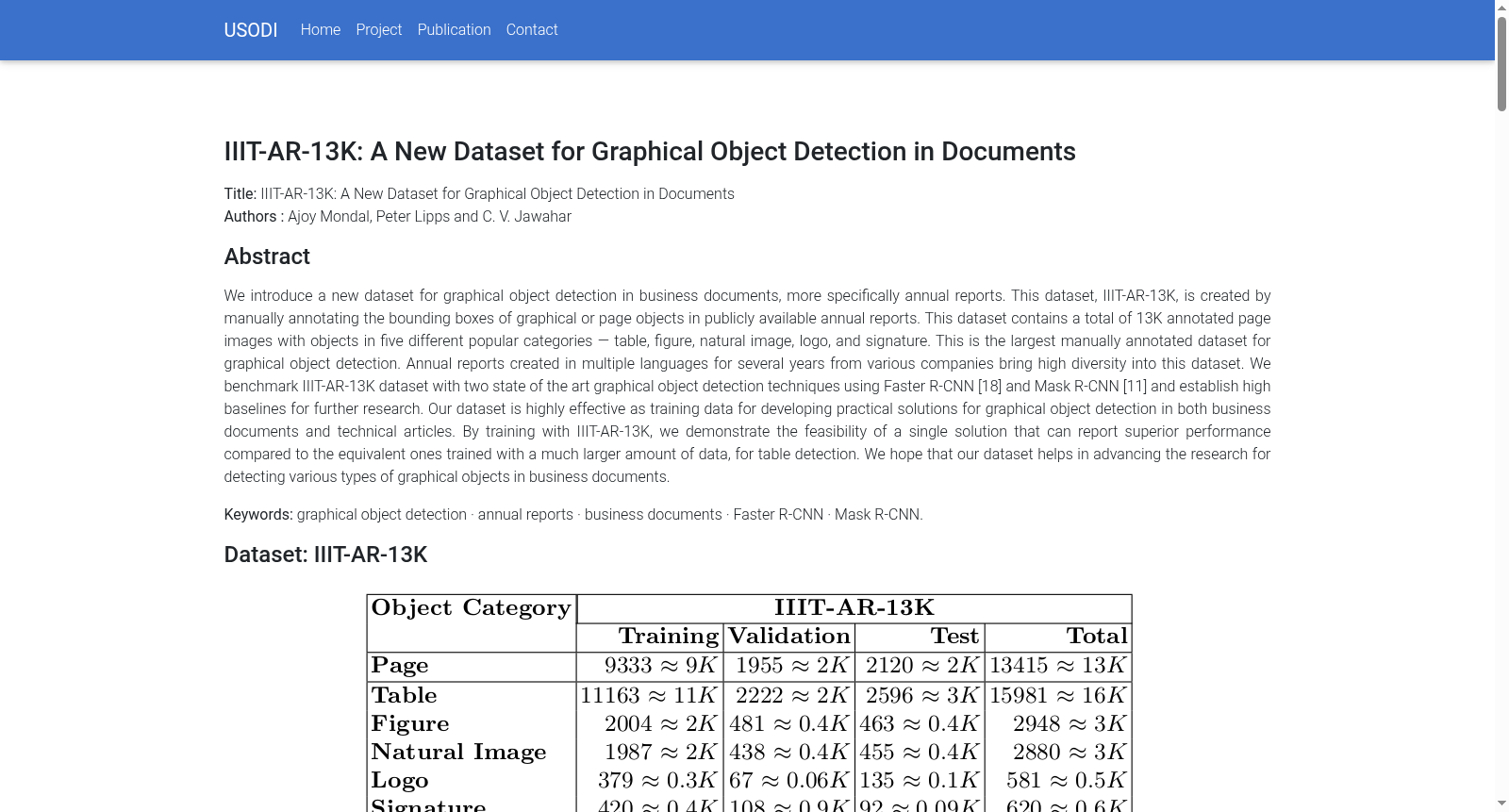
在文档图像分析领域,图形对象检测是理解文档内容的关键步骤。IIIT-AR-13K数据集的构建过程体现了严谨的学术规范,其核心在于从公开可获取的年度报告中手工标注图形对象的边界框。研究团队随机选取了二十九家不同公司、跨越十余年、涵盖英语及法语、日语、俄语等多种语言的年度报告作为数据源,以确保数据在语言、版面布局和对象外观上的高度多样性。标注工作聚焦于五类常见图形对象:表格、图表、自然图像、徽标和签名。最终,该数据集包含了约13,000张标注页面,总计超过23,000个标注实例,成为目前该领域规模最大的人工标注数据集。
使用方法
该数据集主要用于训练和评估文档图像中图形对象检测的深度学习模型。研究者在论文中已使用Faster R-CNN和Mask R-CNN两种先进检测架构建立了性能基准。数据集已预先划分为训练集(约9,000张图像)、验证集(约2,000张图像)和测试集(约2,000张图像),便于进行标准的模型训练、调优和性能评估。实验表明,即使其规模小于某些自动标注的大型数据集,但以其高质量标注和丰富多样性训练出的单一模型,在多个现有基准测试中展现出优越的泛化性能。此外,该数据集还可用于模型微调,仅需少量其样本便能显著提升在其他数据集上预训练模型的检测效果。
背景与挑战
背景概述
文档图像理解领域长期致力于从复杂版面中定位图形对象,以支撑信息检索与自动化处理。2020年,国际信息技术学院海德拉巴分校视觉信息技术中心的Ajoy Mondal、C V Jawahar与Open Text Software GmbH的Peter Lipps共同创建了IIIT-AR-13K数据集,专注于商业文档特别是年度报告中的图形对象检测。该数据集包含约1.3万页来自29家不同公司、跨越十余年、涵盖多种语言的年度报告图像,并手工标注了表格、图表、自然图像、徽标与签名五类对象的边界框。作为当前规模最大的手工标注图形对象检测数据集,其通过引入商业文档特有的版面多样性与对象结构复杂性,显著推动了文档版面分析与企业文档自动化处理的研究进展。
当前挑战
该数据集旨在解决商业文档中多类别图形对象的精准检测问题,其核心挑战在于:年度报告的版面设计高度异构,单栏、双栏与多栏布局混杂,且同类对象(如表格)在不同公司、年份的视觉表现形式差异巨大,导致模型需具备极强的泛化能力。构建过程中的挑战则体现在:手工标注需应对五类对象形态的多样性,例如徽标与签名的尺寸微小且位置随机,而图表与自然图像的视觉特征易混淆;同时,数据需平衡多语言、多公司、多年份的覆盖,以确保样本的代表性与均衡性,避免因标注样本数量不均(如徽标仅500余个)引发的模型偏差。
常用场景
经典使用场景
在文档图像分析领域,IIIT-AR-13K数据集主要应用于图形对象检测任务,尤其聚焦于商业文档中的多类别目标识别。该数据集通过提供包含表格、图形、自然图像、徽标和签名五类对象的精确边界框标注,为研究者构建和评估检测模型奠定了坚实基础。其经典使用场景体现在利用Faster R-CNN和Mask R-CNN等先进深度学习架构进行端到端的对象定位,通过大量异构的年度报告页面图像,系统验证模型在复杂文档布局下的泛化能力与鲁棒性。
解决学术问题
该数据集有效解决了文档分析中图形对象检测的若干核心学术问题。针对现有数据集多局限于科学文献、标注规模有限或类别单一的现状,IIIT-AR-13K通过大规模手动标注和多样化的商业文档来源,显著提升了模型在真实场景下的适应能力。其意义在于首次构建了面向商业文档的大规模多类别检测基准,突破了传统数据集在布局多样性和对象异质性方面的瓶颈,为高精度文档理解任务提供了至关重要的数据支撑,推动了文档图像分析向实用化、精细化方向发展。
实际应用
在实际应用层面,IIIT-AR-13K数据集为商业文档自动化处理提供了关键技术支持。基于该数据集训练的检测模型可广泛应用于企业年度报告的信息抽取、财务文档智能解析、法律文件关键要素定位等场景。通过准确识别文档中的表格、签名和徽标等结构化元素,能够大幅提升文档数字化流程的效率,支撑智能归档、合规性审查和数据挖掘等企业级应用,体现了学术研究向产业实践转化的重要价值。
数据集最近研究
最新研究方向
在文档图像理解领域,IIIT-AR-13K数据集的推出显著推动了商业文档中图形对象检测的前沿研究。该数据集以其大规模手动标注和高度多样性,成为训练鲁棒检测模型的关键资源。当前研究焦点集中于利用该数据集探索跨领域迁移学习与少样本适应策略,旨在解决商业文档布局复杂、对象类别间相似性高的挑战。基于深度学习的检测架构,如Mask R-CNN及其变体,通过在该数据集上的预训练与微调,已在多种文档类型上展现出卓越的泛化能力。这一进展不仅提升了表格、图表等关键信息的自动化提取精度,也为金融、法律等行业的文档智能处理提供了坚实的技术基础,促进了文档数字化向语义理解层面的深化。
相关研究论文
- 1IIIT-AR-13K: A New Dataset for Graphical Object Detection in Documents国际信息技术研究所视觉信息中心 · 2020年
以上内容由遇见数据集搜集并总结生成


