RuWikiTable-RAG
收藏Hugging Face2026-05-11 更新2026-05-12 收录
下载链接:
https://huggingface.co/datasets/kruvcraft/RuWikiTable-RAG
下载链接
链接失效反馈官方服务:
资源简介:
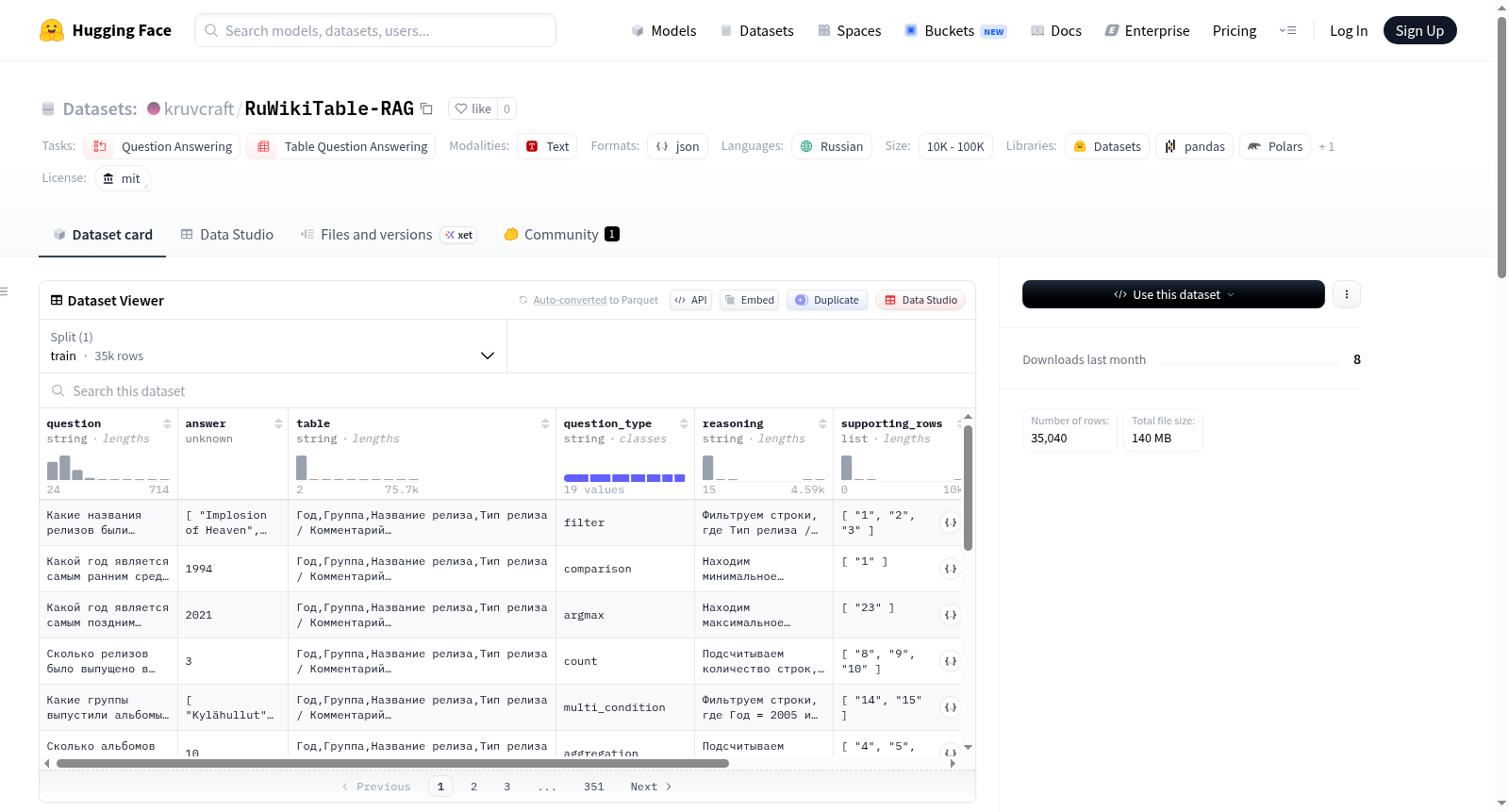
该数据集包含用于评估基于表格数据的检索增强生成(RAG)系统的合成问答对。数据通过自动化流程生成,问题基于俄语维基百科语料库中的表格,要求答案严格来自表格内容,无需外部知识。数据集当前版本包含35,040个训练样本,存储于train.jsonl文件中,未提供独立的验证集或测试集。每个数据样本包含以下字段:用俄语提出的问题、精确答案、以CSV字符串序列化的表格、问题类型(包括过滤、聚合、比较、最大值、最小值、计数和多条件)、获取答案的简要推理过程、用于回答的表格行索引、来源页面的元数据以及表格本身的元数据。数据集生成流程如下:从CSV文件读取表格并转换为Markdown格式,将文章元数据和表格名称输入提示词,使用大型语言模型为每个表格生成7个复杂问题,这些问题需具备自包含性、自然性并明确提及文章和表格名称,最后将问题、答案、推理和元数据保存为JSONL格式。仅包含至少3行的表格。该数据集适用于评估RAG系统的检索和推理能力、测试表格问答性能以及进行基于结构化数据的复杂问题生成实验。需要注意的是,数据集完全由LLM(nvidia/nemotron-3-nano-30b-a3b)基于俄语维基百科表格数据集合成生成;问题表述特意设计为提及文章和表格,这有利于检索任务但限制了问题的自由表述;部分小型表格以及读取或生成过程中出错的表格未被包含在最终数据集中。
This dataset contains synthetic question-answer pairs for evaluating retrieval-augmented generation (RAG) systems based on tabular data. The data is generated through an automated process, with questions based on tables from the Russian Wikipedia corpus, requiring answers strictly from the table content without external knowledge. The current version of the dataset includes 35,040 training samples stored in the train.jsonl file, with no separate validation or test sets provided. Each data sample contains the following fields: a question posed in Russian, an exact answer, a table serialized as a CSV string, question types (including filtering, aggregation, comparison, maximum, minimum, counting, and multi-condition), a brief reasoning process for obtaining the answer, row indices of the table used for answering, metadata of the source page, and metadata of the table itself. The dataset generation process is as follows: tables are read from CSV files and converted to Markdown format, article metadata and table names are input into prompts, and a large language model is used to generate seven complex questions per table; these questions must be self-contained, natural, and explicitly mention the article and table names, with questions, answers, reasoning, and metadata saved in JSONL format. Only tables with at least three rows are included. This dataset is suitable for evaluating the retrieval and reasoning capabilities of RAG systems, testing table-based question-answering performance, and conducting experiments on complex question generation based on structured data. It should be noted that the dataset is entirely synthetically generated by an LLM (nvidia/nemotron-3-nano-30b-a3b) based on Russian Wikipedia table data; the question formulation is intentionally designed to mention articles and tables, which benefits retrieval tasks but limits free expression in questions; some small tables and those with errors during reading or generation are not included in the final dataset.
创建时间:
2026-05-11
原始信息汇总
数据集概述
数据集名称: RuWikiTable-RAG
许可证: MIT
任务类别: 问答、表格问答
语言: 俄语
数据集摘要
该数据集包含用于评估基于表格数据的 RAG(检索增强生成)系统的合成问答对。所有问题均由俄语语料库中的表格自动生成,答案严格限定于表格内容,不依赖外部知识。
当前导出包含:
train.jsonl文件:35,040 个样本- 仅有一个训练集(train split),无独立的验证集或测试集
数据字段
每条记录包含以下字段:
question:俄语问题answer:精确答案table:以 CSV 字符串序列化的表格question_type:问题类型(包括filter、aggregation、comparison、argmax、argmin、count、multi_condition)reasoning:获取答案的简要解释supporting_rows:用于回答的表格行page_meta:来源页面的元数据table_meta:来源表格的元数据
数据来源与生成流程
数据集来源于 data/ 文件夹中的表格及相关元数据(page_meta.json、*_meta.json)。生成流程如下:
- 从 CSV 读取表格并转换为 markdown 格式
- 将文章元数据和表格标题输入提示(prompt)
- 使用大语言模型(LLM)对每个表格生成 7 个复杂问题
- 问题要求自包含、自然,并明确包含文章名称和表格标题
- 最终将问题、答案、推理过程和元数据保存为 JSONL 格式
用于生成的表格要求至少包含 3 行数据。
预期用途
该数据集适用于:
- 评估 RAG 系统的检索与推理能力
- 测试表格问答(table question answering)任务
- 开展基于结构化数据的复杂问题生成实验
局限性
- 数据集为合成数据,完全由大语言模型(nvidia/nemotron-3-nano-30b-a3b)生成,基于此数据集:https://gitlab.com/unidata-labs/ru-wiki-tables-dataset/-/tree/3afaefb031032513e1b36b4707fad73f488a5e00/
- 问题被特意设计为提及文章和表格名称,这有助于检索,但使表述方式不够自由
- 并非所有表格都包含在导出中:小型表格以及读取或生成过程中出错的表格会被跳过
搜集汇总
数据集介绍
构建方式
RuWikiTable-RAG数据集基于俄语维基百科表格语料库构建,通过自动化合成管道生成。首先从CSV文件中读取表格并转换为Markdown格式,随后将文章元数据和表格标题输入大语言模型(nvidia/nemotron-3-nano-30b-a3b),促使模型为每张至少包含三行数据的表格生成七个复杂问题。每个问题均要求严格依赖表格内容作答,避免引入外部知识,并需自然融入文章与表格的名称以确保自洽性。最终,生成的问题、精确答案、推理过程及相关元数据被保存为JSONL格式,形成了包含35,040个训练样本的数据集。
特点
该数据集的核心特色在于其专为评估检索增强生成系统对表格数据的处理能力而设计。所有问题均为合成产生的复杂类型,涵盖过滤、聚合、比较、极值查询、计数及多条件筛选等七种范式,要求模型精准定位表格中的支持行并完成符号推理。数据集中每条记录均包含显式的推理链与支撑行索引,这不仅增强了透明度,还为诊断模型错误提供了细粒度依据。此外,每道问题均明确提及来源文章和表格标题,模拟了现实场景中需要先检索再回答的流程,从而使数据集特别适合用于测试RAG系统的检索与推理联合性能。
使用方法
RuWikiTable-RAG数据集适用于多种信息检索与表格问答任务的研究与评测。开发者可直接加载JSONL格式的训练文件,利用其中的question字段作为输入,answer字段作为标准答案,在RAG框架下评估检索器从表格中定位相关信息的能力,以及生成器基于这些信息做出准确回答的推理能力。数据集没有预设验证集或测试集划分,用户可根据需求自行分割,或将其整体用于模型微调、提示工程实验以及跨领域检索系统的基准对比。借助question_type与supporting_rows字段,还可对模型在不同推理类型上的表现进行细粒度分析。
背景与挑战
背景概述
在检索增强生成(RAG)系统蓬勃发展的背景下,如何有效评估其对表格数据的检索与推理能力成为亟待解决的问题。RuWikiTable-RAG数据集由俄罗斯研究团队基于俄语维基百科表格语料库构建,发布于2024年,旨在为表格问答任务提供高质量的合成评估基准。该数据集通过自动化流水线从俄语维基百科表格中生成3.5万余个复杂问题,涵盖过滤、聚合、比较等七种推理类型,并确保答案严格来源于表格内容而不依赖外部知识。作为首个专注于俄语表格RAG评测的数据集,它为多语言表格问答研究提供了关键支撑,推动了非英语环境下结构化知识检索与推理评估的发展。
当前挑战
该数据集面临的核心挑战在于双重维度。领域问题方面,现有RAG系统在处理表格数据时存在检索不精确与推理链断裂的瓶颈,传统问答模型难以准确执行跨行计算或条件过滤,亟需针对结构化数据的专用评估基准来揭示模型在复杂逻辑操作上的短板。构建过程中,团队需克服合成数据质量控制的难题:完全依赖大语言模型生成问题可能导致语言模式僵化、自然度不足;同时从海量表格中筛选满足最低行数要求、避免格式错误的样本,以及确保生成问题与表格内容严格对齐且问题类型分布均衡,均构成重大工程挑战。
常用场景
经典使用场景
在自然语言处理与信息检索的交汇处,表格数据问答始终是衡量模型结构化理解能力的重要试金石。RuWikiTable-RAG数据集专为评估基于检索增强生成(RAG)的表格问答系统而生,其核心设计围绕检索与推理两大能力展开。每条样本包含一个基于俄语维基百科表格生成的复杂问题、精确答案、序列化表格元数据以及推理路径,支持过滤、聚合、比较、极值查找和多条件筛选等七类典型查询。研究者可借此测试系统在检索相关表格行、执行跨行逻辑推理以及生成忠实于表格内容的答案方面的综合表现,尤其适用于检验RAG流程中检索模块与生成模块之间的协同效率。
衍生相关工作
围绕RuWikiTable-RAG衍生出一系列富有启发性的研究工作。其生成管道基于LLM(如Nemotron)从俄语表格语料库自动合成问题,这一方法催生了低资源语言的问答数据自动构建范式。后续工作可沿两个方向展开:一是借鉴其多类型问题框架,开发支持时间推理、数值比较等更细粒度操作的变体数据集;二是以该数据集为评估基准,改进稀疏检索与稠密检索在表格场景中的融合策略,或探索基于图神经网络的表格行间关系建模。该数据集还启发了跨语言迁移学习实验,研究者尝试利用其俄语合成数据增强英语表格问答模型的零样本泛化能力。
数据集最近研究
最新研究方向
在检索增强生成(RAG)系统快速发展的背景下,RuWikiTable-RAG数据集聚焦于表格数据的问答评估,填补了俄语场景下结构化数据检索与推理能力评测的空白。该数据集通过自动化流水线从俄语维基百科表格中生成3.5万余个合成问答对,涵盖过滤、聚合、比较及多条件查询等复杂问题类型,为评估RAG系统在表格检索、精确推理与答案生成方面的协同性能提供了标准化基准。其设计强调答案完全源自表格内容且需显式引用文章来源,这一特性契合当前研究中对可解释性和事实一致性的迫切需求,尤其推动了对跨模态检索与结构化信息理解的研究。此外,数据集的生成过程采用大语言模型与元数据引导的筛选策略,体现了合成数据构建与可控性问题生成方法的融合趋势,为多语言、多类型表格问答系统的鲁棒性评估与优化开辟了新路径。
以上内容由遇见数据集搜集并总结生成


