semeru/Text-Code-CodeSearchNet-Python
收藏Hugging Face2023-03-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/semeru/Text-Code-CodeSearchNet-Python
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
Programminglanguage: "Python"
version: "N/A"
Date: "Codesearchnet(Jun 2020 - paper release date)"
Contaminated: "Very Likely"
Size: "Standard Tokenizer (TreeSitter)"
---
### Dataset is imported from CodeXGLUE and pre-processed using their script.
# Where to find in Semeru:
The dataset can be found at /nfs/semeru/semeru_datasets/code_xglue/text-to-code/codesearchnet/python in Semeru
# CodeXGLUE -- Code Search (AdvTest)
## Task Definition
Given a natural language, the task is to search source code that matches the natural language. To test the generalization ability of a model, function names and variables in test sets are replaced by special tokens.
## Dataset
The dataset we use comes from [CodeSearchNet](https://arxiv.org/pdf/1909.09436.pdf) and we filter the dataset as the following:
- Remove examples that codes cannot be parsed into an abstract syntax tree.
- Remove examples that #tokens of documents is < 3 or >256
- Remove examples that documents contain special tokens (e.g. <img ...> or https:...)
- Remove examples that documents are not English.
Besides, to test the generalization ability of a model, function names and variables in test sets are replaced by special tokens.
### Data Format
After preprocessing dataset, you can obtain three .jsonl files, i.e. train.jsonl, valid.jsonl, test.jsonl
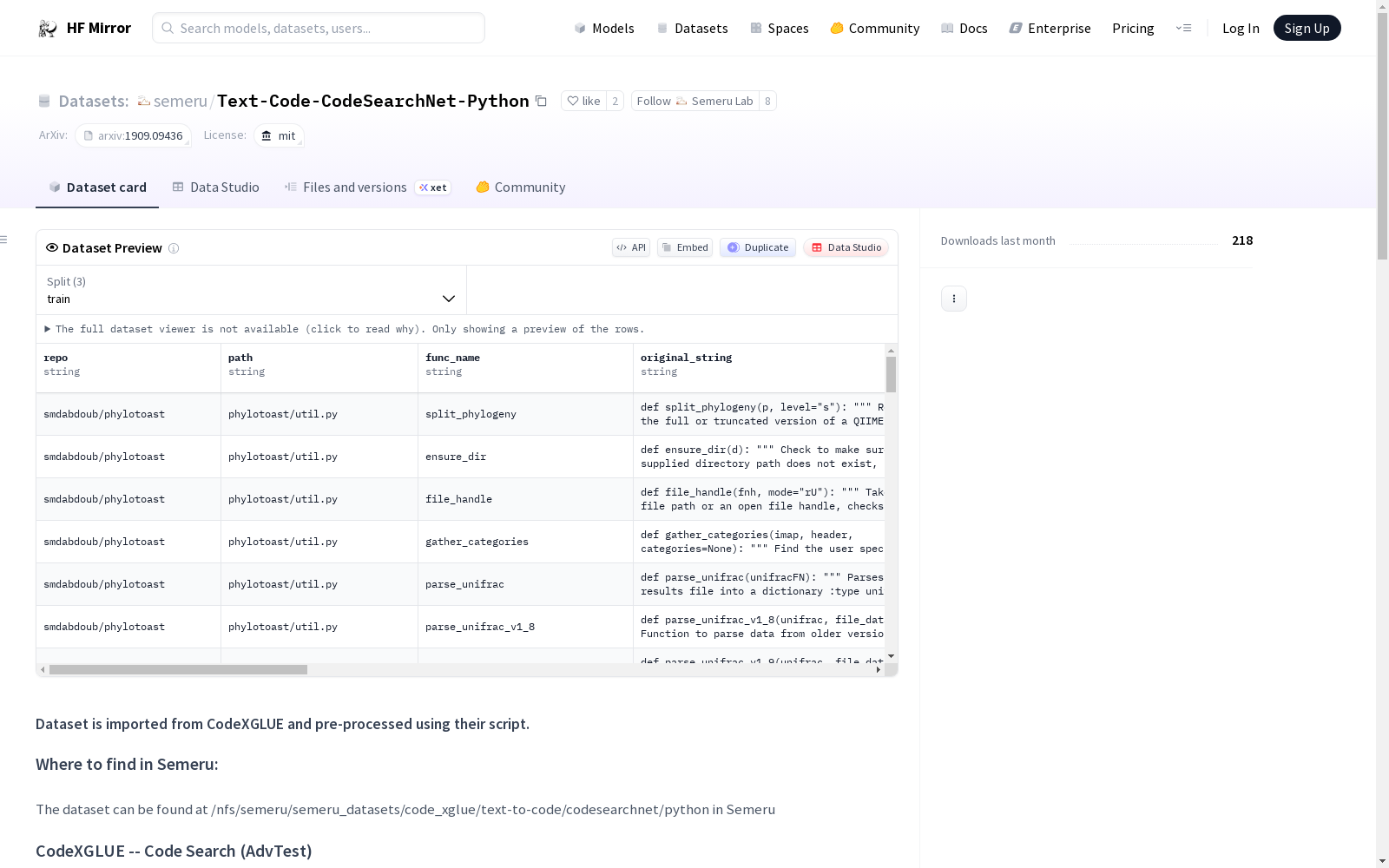
For each file, each line in the uncompressed file represents one function. One row is illustrated below.
- **repo:** the owner/repo
- **path:** the full path to the original file
- **func_name:** the function or method name
- **original_string:** the raw string before tokenization or parsing
- **language:** the programming language
- **code/function:** the part of the `original_string` that is code
- **code_tokens/function_tokens:** tokenized version of `code`
- **docstring:** the top-level comment or docstring, if it exists in the original string
- **docstring_tokens:** tokenized version of `docstring`
- **url:** the url for the example (identify natural language)
- **idx**: the index of code (identify code)
### Data Statistics
Data statistics of the dataset are shown in the below table:
| | #Examples |
| ----- | :-------: |
| Train | 251,820 |
| Dev | 9,604 |
| Test | 19,210 |
### Example
Given a text-code file evaluator/test.jsonl:
```json
{"url": "url0", "docstring": "doc0","function": "fun0", "idx": 10}
{"url": "url1", "docstring": "doc1","function": "fun1", "idx": 11}
{"url": "url2", "docstring": "doc2","function": "fun2", "idx": 12}
{"url": "url3", "docstring": "doc3","function": "fun3", "idx": 13}
{"url": "url4", "docstring": "doc4","function": "fun4", "idx": 14}
```
### Input Predictions
For each url for natural language, descending sort candidate codes and return their idx in order. For example:
```json
{"url": "url0", "answers": [10,11,12,13,14]}
{"url": "url1", "answers": [10,12,11,13,14]}
{"url": "url2", "answers": [13,11,12,10,14]}
{"url": "url3", "answers": [10,14,12,13,11]}
{"url": "url4", "answers": [10,11,12,13,14]}
```
## Reference
<pre><code>@article{husain2019codesearchnet,
title={Codesearchnet challenge: Evaluating the state of semantic code search},
author={Husain, Hamel and Wu, Ho-Hsiang and Gazit, Tiferet and Allamanis, Miltiadis and Brockschmidt, Marc},
journal={arXiv preprint arXiv:1909.09436},
year={2019}
}</code></pre>
许可证:MIT许可证
编程语言:Python
版本:无可用信息
数据日期:CodeSearchNet(2020年6月——论文发布日期)
数据污染情况:极有可能存在污染
分词规格:采用标准分词器(TreeSitter)
本数据集源自CodeXGLUE,并使用其官方脚本完成预处理工作。
# 在Semeru平台中的获取路径
该数据集可于Semeru的/nfs/semeru/semeru_datasets/code_xglue/text-to-code/codesearchnet/python路径下获取。
# CodeXGLUE —— 代码搜索任务(AdvTest)
## 任务定义
给定一段自然语言,本任务旨在检索与之语义匹配的源代码。为测试模型的泛化能力,测试集中的函数名与变量均已替换为特殊标记(Token)。
## 数据集概况
本数据集源自[CodeSearchNet](https://arxiv.org/pdf/1909.09436.pdf),并按照如下规则进行过滤预处理:
- 移除无法被解析为抽象语法树(Abstract Syntax Tree)的样本
- 移除文档Token数量小于3或大于256的样本
- 移除文档中包含特殊标记的样本(例如<img ...>或https://格式的链接等)
- 移除文档非英文的样本
此外,为进一步验证模型泛化能力,测试集中的函数名与变量同样会被替换为特殊标记(Token)。
### 数据格式
完成预处理后,将得到三个.jsonl格式文件,分别为train.jsonl、valid.jsonl与test.jsonl。
每个文件的每一行均对应一个函数,下文将展示单条数据的格式示例:
- **repo**:代码仓库的所有者/仓库名
- **path**:原始文件的完整路径
- **func_name**:函数或方法名称
- **original_string**:分词或解析前的原始字符串
- **language**:所用编程语言
- **code/function**:`original_string`中对应的代码部分
- **code_tokens/function_tokens**:`code`的分词结果
- **docstring**:原始字符串中的顶层注释或文档字符串(若存在)
- **docstring_tokens**:`docstring`的分词结果
- **url**:该样本对应的自然语言查询链接(用于标识自然语言查询)
- **idx**:代码的索引编号(用于标识代码样本)
### 数据统计
数据统计情况如下表所示:
| | 样本数量 |
| ----- | :-------: |
| 训练集 | 251,820 |
| 验证集 | 9,604 |
| 测试集 | 19,210 |
### 样本示例
以evaluator/test.jsonl文本代码文件为例,以下为该文件的内容示例:
json
{"url": "url0", "docstring": "doc0","function": "fun0", "idx": 10}
{"url": "url1", "docstring": "doc1","function": "fun1", "idx": 11}
{"url": "url2", "docstring": "doc2","function": "fun2", "idx": 12}
{"url": "url3", "docstring": "doc3","function": "fun3", "idx": 13}
{"url": "url4", "docstring": "doc4","function": "fun4", "idx": 14}
### 预测输入格式
针对每个自然语言查询对应的url,需对候选代码按匹配度降序排序,并按顺序返回其idx编号。示例如下:
json
{"url": "url0", "answers": [10,11,12,13,14]}
{"url": "url1", "answers": [10,12,11,13,14]}
{"url": "url2", "answers": [13,11,12,10,14]}
{"url": "url3", "answers": [10,14,12,13,11]}
{"url": "url4", "answers": [10,11,12,13,14]}
## 参考文献
bibtex
@article{husain2019codesearchnet,
title={Codesearchnet challenge: Evaluating the state of semantic code search},
author={Husain, Hamel and Wu, Ho-Hsiang and Gazit, Tiferet and Allamanis, Miltiadis and Brockschmidt, Marc},
journal={arXiv preprint arXiv:1909.09436},
year={2019}
}
提供机构:
semeru
原始信息汇总
数据集概述
数据集来源与处理
- 来源: 数据集来自CodeSearchNet。
- 处理: 使用CodeXGLUE的脚本进行预处理,包括移除无法解析为抽象语法树的代码示例,以及不符合特定token数量和语言要求的文档。
数据集内容
- 格式: 包含三个.jsonl文件:train.jsonl, valid.jsonl, test.jsonl。
- 结构: 每个文件的每行代表一个函数,包含repo, path, func_name, original_string, language, code/function, code_tokens/function_tokens, docstring, docstring_tokens, url, idx等字段。
数据集统计
| #Examples | |
|---|---|
| Train | 251,820 |
| Dev | 9,604 |
| Test | 19,210 |
任务定义
- 目标: 给定自然语言描述,搜索匹配的源代码。
- 测试: 为了测试模型的泛化能力,测试集中的函数名和变量被替换为特殊token。
数据集示例
- 文件: evaluator/test.jsonl
- 内容示例: 包含多个记录,每个记录有url, docstring, function, idx等字段。
输入预测
- 处理: 对每个自然语言的url,按降序排列候选代码并返回它们的idx。
- 示例: 返回的json格式包含url和对应的answers数组。
搜集汇总
数据集介绍
构建方式
在代码语义搜索领域,数据集的构建质量直接影响模型性能。本数据集源自CodeSearchNet,经过CodeXGLUE团队的精细处理,采用多阶段过滤策略以确保数据纯净性。具体而言,构建过程首先移除了无法解析为抽象语法树的代码示例,随后筛选文档标记数量在3至256之间的样本,并剔除包含特殊标记或非英语文档的条目。此外,为增强模型的泛化能力,测试集中的函数名和变量均被替换为特殊标记,最终形成包含训练集、验证集和测试集的标准化结构。
特点
该数据集聚焦于Python编程语言,专为代码搜索任务设计,其核心特点体现在数据规模与结构化表示上。数据集包含超过25万训练样本,覆盖广泛的代码库与文档对,每个样本均提供代码片段、对应的自然语言文档字符串及其标记化版本。值得注意的是,数据经过抽象语法树验证,确保了代码的语法正确性,同时测试集的特殊标记处理强化了模型对未知标识符的适应能力,为评估语义搜索模型的鲁棒性提供了可靠基准。
使用方法
使用本数据集时,研究人员可将其应用于代码搜索模型的训练与评估。数据集以JSON行格式组织,分为train.jsonl、valid.jsonl和test.jsonl三个文件,每行代表一个函数样本,包含代码、文档字符串、仓库路径等元数据。在模型训练阶段,可利用代码与文档字符串的对应关系学习语义映射;评估时则需根据自然语言查询对候选代码进行排序,并按照预测的索引顺序输出结果,以此衡量模型在真实场景下的搜索准确性。
背景与挑战
背景概述
在软件工程与人工智能交叉领域,代码语义搜索作为提升开发者效率的关键技术,其核心在于建立自然语言与编程语言间的精准映射。semeru/Text-Code-CodeSearchNet-Python数据集源于CodeXGLUE基准测试框架,由微软研究院等机构于2020年6月基于CodeSearchNet原始数据构建而成。该数据集聚焦于Python编程语言,旨在解决自然语言查询与源代码片段间的语义匹配问题,通过抽象语法树过滤与数据清洗,为代码智能、程序理解等研究方向提供了大规模高质量语料,显著推动了基于深度学习的代码搜索模型的发展。
当前挑战
该数据集所针对的代码语义搜索任务面临多重挑战:自然语言描述的模糊性与代码语法严格性之间的语义鸿沟,要求模型具备跨模态对齐能力;测试集中函数名与变量被替换为特殊令牌,旨在检验模型对未知标识符的泛化性能,这增加了语义解析的难度。在数据构建过程中,需从海量开源代码中提取有效函数,并克服代码解析错误、文档长度异常、非英语内容及特殊字符干扰等噪声过滤难题,确保数据纯净度与结构一致性成为关键瓶颈。
常用场景
经典使用场景
在软件工程与人工智能交叉领域,代码搜索任务旨在通过自然语言查询精准定位相关源代码片段。该数据集作为CodeSearchNet的Python子集,经过精细过滤与预处理,为模型训练与评估提供了高质量文本-代码对。其经典应用场景集中于训练深度神经网络,如基于Transformer的编码器-解码器架构,以学习自然语言描述与Python代码间的语义映射关系,从而提升代码检索的准确性与效率。
解决学术问题
该数据集有效应对了代码语义搜索中的泛化能力挑战。通过将测试集中的函数名与变量替换为特殊标记,迫使模型超越表面词汇匹配,深入理解代码结构与功能语义。此举解决了传统方法在变量重命名或代码重构时性能下降的难题,推动了基于抽象语法树与神经网络的代码表示学习研究,为程序理解与智能编程辅助奠定了数据基础。
衍生相关工作
围绕该数据集,学术界衍生了一系列经典研究工作。例如,CodeXGLUE基准将其纳入文本-代码检索任务,推动了如CodeBERT、GraphCodeBERT等预训练模型的性能评估与优化。这些工作进一步探索了多模态表示学习、跨语言代码搜索及对抗性测试方法,不仅丰富了代码智能领域的研究图谱,也为工业级代码搜索引擎的演进提供了理论支撑与技术启示。
以上内容由遇见数据集搜集并总结生成


