multilingual-fluency
收藏Hugging Face2025-11-19 更新2025-11-20 收录
下载链接:
https://huggingface.co/datasets/geoalgo/multilingual-fluency
下载链接
链接失效反馈官方服务:
资源简介:
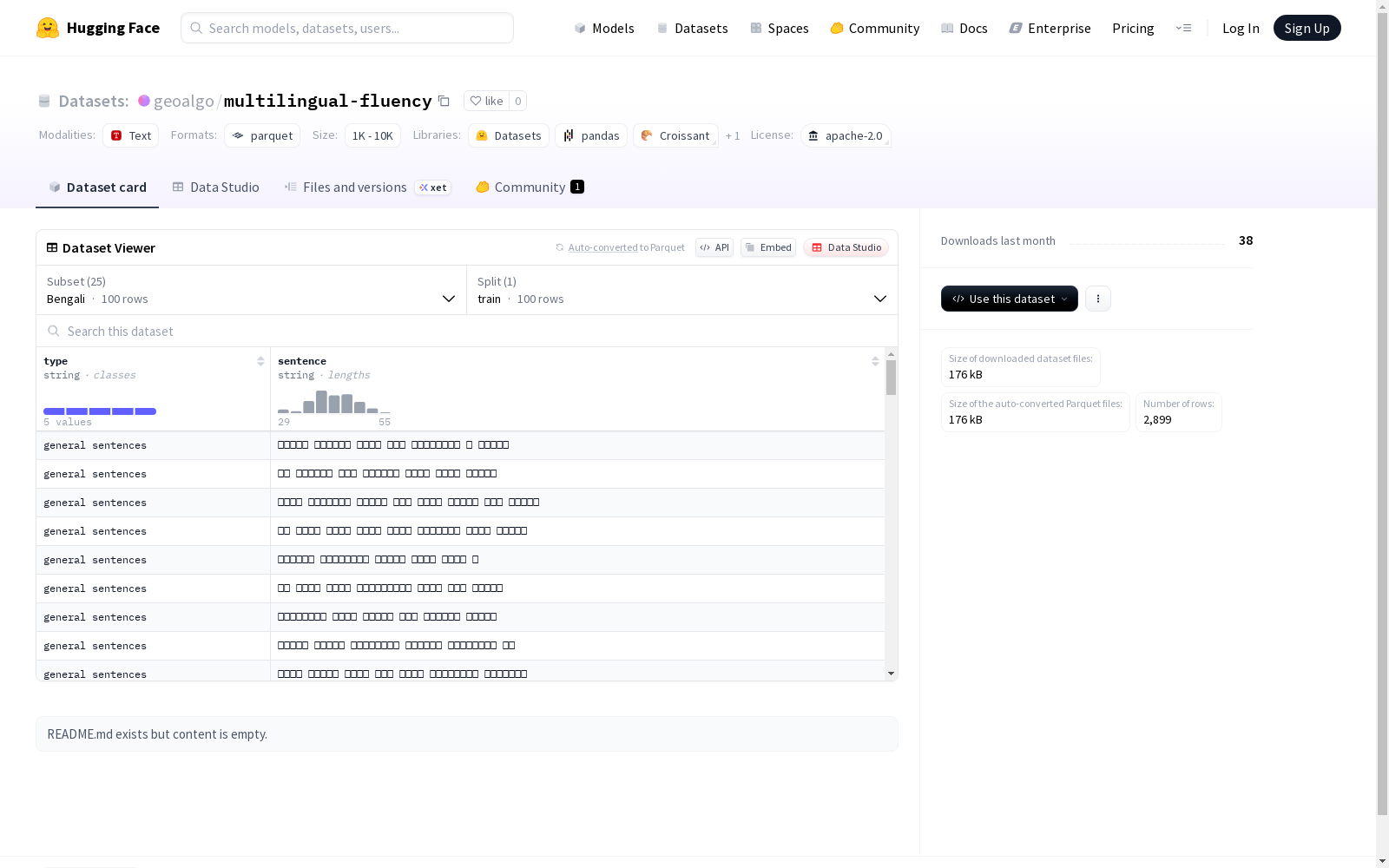
一个包含多种语言训练数据的集合,每种语言的数据都包含类型和句子两种字符串类型的特征,并且有对应的训练集信息,如文件大小、示例数量、下载大小和数据集大小。
创建时间:
2025-11-14
原始信息汇总
数据集概述
基本信息
- 许可证: Apache-2.0
- 数据集地址: https://huggingface.co/datasets/geoalgo/multilingual-fluency
语言配置
数据集包含以下25种语言配置:
- 孟加拉语 (Bengali)
- 保加利亚语 (Bulgarian)
- 加泰罗尼亚语 (Catalan)
- 捷克语 (Czech)
- 丹麦语 (Danish)
- 荷兰语 (Dutch)
- 英语 (English)
- 法语 (French)
- 德语 (German)
- 希腊语 (Greek)
- 印地语 (Hindi)
- 匈牙利语 (Hungarian)
- 印度尼西亚语 (Indonesian)
- 意大利语 (Italian)
- 日语 (Japanese)
- 普通话中文 (Mandarin Chinese)
- 波兰语 (Polish)
- 葡萄牙语 (Portuguese)
- 罗马尼亚语 (Romanian)
- 俄语 (Russian)
- 西班牙语 (Spanish)
- 标准阿拉伯语 (Standard Arabic)
- 瑞典语 (Swedish)
- 土耳其语 (Turkish)
- 乌克兰语 (Ukrainian)
数据结构
特征字段
- type: 字符串类型
- sentence: 字符串类型
数据分割
所有语言配置仅包含训练集 (train)
数据规模
按语言统计
| 语言 | 样本数量 | 数据集大小(字节) | 下载大小(字节) |
|---|---|---|---|
| 孟加拉语 | 100 | 13,161 | 7,113 |
| 保加利亚语 | 100 | 13,172 | 8,058 |
| 加泰罗尼亚语 | 100 | 7,652 | 5,976 |
| 捷克语 | 100 | 7,250 | 6,165 |
| 丹麦语 | 100 | 7,164 | 5,858 |
| 荷兰语 | 100 | 7,804 | 6,257 |
| 英语 | 200 | 15,758 | 10,667 |
| 法语 | 100 | 8,202 | 6,442 |
| 德语 | 100 | 8,452 | 6,841 |
| 希腊语 | 99 | 12,152 | 7,705 |
| 印地语 | 200 | 23,104 | 10,419 |
| 匈牙利语 | 100 | 8,595 | 6,669 |
| 印度尼西亚语 | 100 | 7,568 | 5,878 |
| 意大利语 | 100 | 8,008 | 6,499 |
| 日语 | 100 | 6,329 | 5,032 |
| 普通话中文 | 200 | 9,376 | 6,554 |
| 波兰语 | 100 | 8,430 | 6,920 |
| 葡萄牙语 | 100 | 7,514 | 6,071 |
| 罗马尼亚语 | 100 | 7,994 | 6,409 |
| 俄语 | 100 | 12,462 | 7,761 |
| 西班牙语 | 200 | 15,841 | 10,320 |
| 标准阿拉伯语 | 100 | 10,383 | 6,406 |
| 瑞典语 | 100 | 6,975 | 5,719 |
| 土耳其语 | 100 | 7,920 | 6,163 |
| 乌克兰语 | 100 | 12,126 | 7,803 |
总体统计
- 总语言数量: 25种
- 总样本数量: 2,799条
- 样本数量分布: 大多数语言100条,英语、印地语、普通话中文、西班牙语各200条,希腊语99条
搜集汇总
数据集介绍
构建方式
在跨语言自然语言处理研究领域,multilingual-fluency数据集通过系统化采集25种语言的文本语料构建而成。该数据集涵盖从孟加拉语到乌克兰语的广泛语言谱系,每种语言均包含100个训练样本,其中英语、印地语、中文和西班牙语特别扩充至200个样本。构建过程中采用统一的文本处理流程,确保所有语言版本均包含类型标注和原始语句两个核心特征,形成标准化的多语言平行语料库。
特点
该数据集最显著的特征在于其语言覆盖的广度和数据结构的统一性。25种语言涵盖印欧、汉藏、阿尔泰等多个语系,每个语言配置均严格保持相同的特征字段设计。数据规模呈现差异化分布,非拉丁文字语言如孟加拉语和印地语具有更大的字节容量,反映出不同文字系统的存储特性。所有语种均采用Apache 2.0开源协议,为学术研究和商业应用提供灵活的使用权限。
使用方法
研究人员可通过HuggingFace平台按语言配置灵活加载特定语种子集,每个语言独立的数据文件路径便于针对性实验设计。数据集支持直接用于多语言文本生成质量评估、跨语言流畅度比较研究等任务。使用时应关注不同语言样本量的差异,英语等主要语言的双倍样本量为模型训练提供更充分的数据支撑。数据加载接口兼容主流深度学习框架,可实现多语言并行处理流程的快速部署。
背景与挑战
背景概述
在全球化数字时代背景下,多语言自然语言处理研究面临语料资源分布不均的困境。multilingual-fluency数据集应运而生,其构建旨在系统覆盖包括孟加拉语、保加利亚语、中文等二十余种语言的文本语料,通过统一标注框架解决跨语言流畅度评估的基准缺失问题。该数据集由国际研究团队基于Apache 2.0协议发布,每个语言模块包含百级规模的句子样本,通过类型标记与原始文本的双重特征设计,为语言模型的多语言泛化能力评估提供重要基础设施。
当前挑战
该数据集致力于攻克多语言流畅度评估中的领域难题,包括语言结构差异导致的评估标准统一困境,以及低资源语言建模时面临的数据稀疏性挑战。构建过程中需应对多语言平行语料采集的复杂性,涉及非拉丁文字系统的字符编码处理,以及不同语言社区文化语境对流畅度标注的主观性影响。此外,保持各语言分支在数据规模与质量上的均衡性,亦是构建跨语言可比数据集的核心难点。
常用场景
经典使用场景
在跨语言自然语言处理研究中,multilingual-fluency数据集被广泛应用于评估和提升机器翻译系统的流畅度。该数据集涵盖23种语言的句子对,为研究者提供了丰富的多语言平行语料,常用于训练和测试神经机器翻译模型,特别是在处理低资源语言时展现出独特价值。通过分析不同语言间的句法结构和语义对应关系,该数据集助力于构建更精准的跨语言表示模型。
解决学术问题
该数据集有效解决了多语言自然语言处理中的核心挑战,即如何在不同语系间建立可靠的语义对应关系。通过提供标准化的多语言平行语料,研究者能够系统评估跨语言模型的泛化能力,特别是在处理形态丰富语言时的表现。这一资源显著推进了语言模型跨语言迁移学习的研究,为探索语言普遍性假设提供了实证基础。
衍生相关工作
基于该数据集衍生的经典研究包括多语言BERT的预训练优化、跨语言序列标注模型的开发等。这些工作通过利用数据集中丰富的语言对比特征,显著提升了跨语言自然语言推理任务的性能。后续研究进一步扩展了数据集的适用场景,如在低资源语言处理任务中将其作为数据增强的来源,推动了多语言模型在资源受限环境下的应用突破。
以上内容由遇见数据集搜集并总结生成


