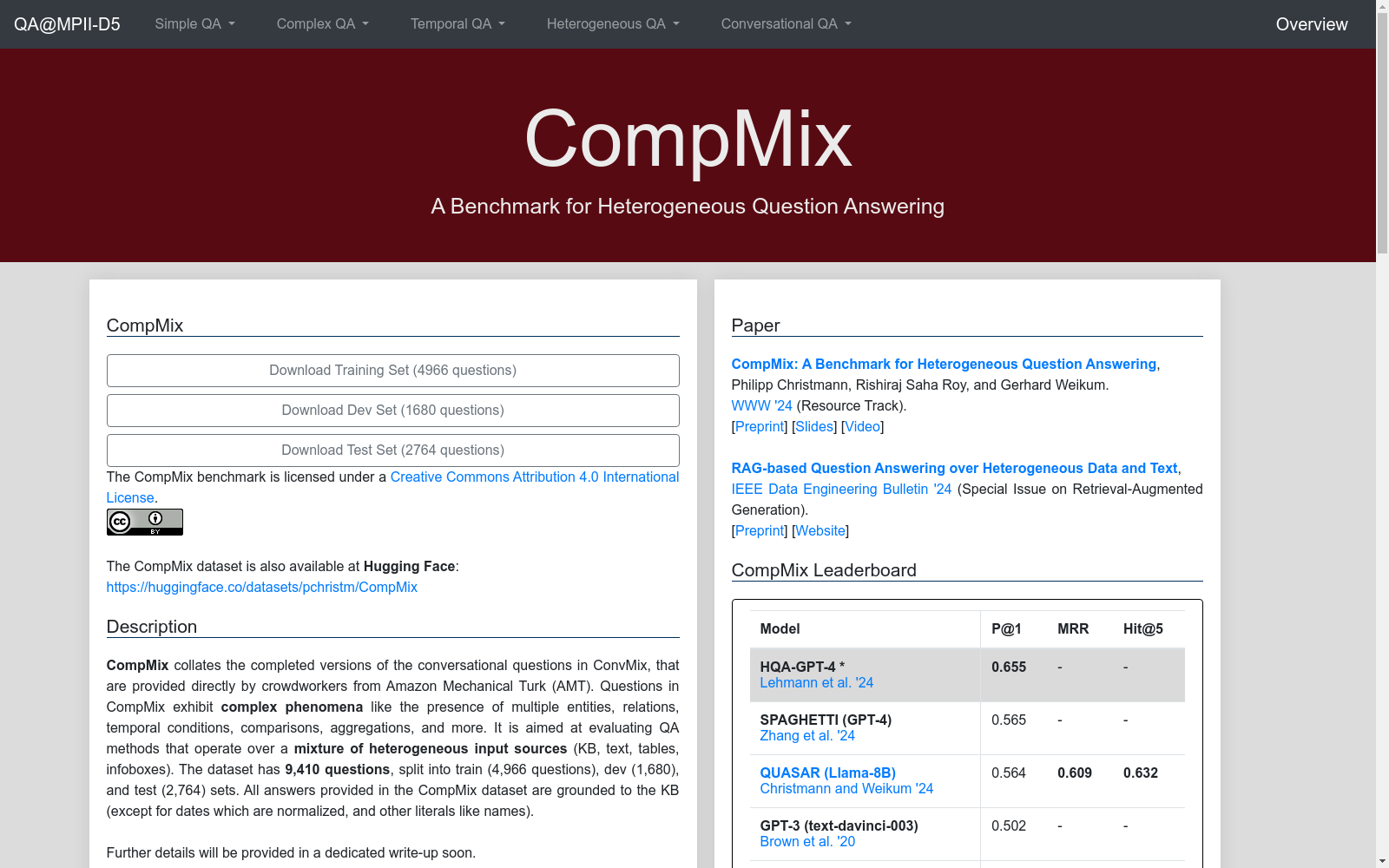
COMPMIX
收藏arXiv2023-08-20 更新2024-06-21 收录
下载链接:
https://qa.mpi-inf.mpg.de/compmix
下载链接
链接失效反馈官方服务:
资源简介:
COMPMIX是由马克斯·普朗克信息学研究所创建的一个众包QA基准,旨在通过集成多种输入源来评估异构问答系统。该数据集包含9,410个问题,涉及书籍、电影、音乐、电视系列和足球五个领域,要求系统从维基数据知识库、文本、表格和信息框中整合信息以提供答案。数据集的创建过程涉及众包工作者在特定领域内选择实体并提出问题,答案则基于这些实体从不同来源获取。COMPMIX的应用领域广泛,主要用于解决需要从多个异构信息源中提取和整合信息的问题,以提高问答系统的覆盖率和准确性。
COMPMIX is a crowdsourced QA benchmark developed by the Max Planck Institute for Informatics, which aims to evaluate heterogeneous question answering systems by integrating diverse input sources. This dataset consists of 9,410 questions across five domains: books, films, music, television series, and football. It necessitates that QA systems integrate information retrieved from Wikidata knowledge bases, plain texts, tables, and infoboxes to provide accurate answers. The construction of COMPMIX involves crowdsourced workers selecting entities within specific domains and formulating targeted questions, with answers derived from these entities across multiple heterogeneous sources. COMPMIX has broad application prospects, and it is primarily utilized to tackle tasks that require extracting and integrating information from multiple disparate information sources, thereby enhancing the coverage and accuracy of question answering systems.
提供机构:
马克斯·普朗克信息学研究所
创建时间:
2023-06-21
搜集汇总
数据集介绍
构建方式
在异构问答领域,现有基准多局限于单一知识源,难以全面评估系统整合多源信息的能力。COMPMIX基准的构建采用众包方式,通过亚马逊土耳其机器人平台收集人类标注者生成的完整问题。标注者从书籍、电影、音乐、电视剧和足球五个领域中选择实体,并基于四种异构源——包括完整的Wikidata知识库、维基百科文本、表格及信息框——提出自然语言问题并提供答案。最终数据集包含9,410个问题,划分为训练集、开发集和测试集,确保问题真实反映用户多样化的表达方式和复杂意图。
使用方法
使用COMPMIX基准时,研究者可将其作为评估异构问答系统的标准测试平台。数据集提供了明确的问题、答案及对应的源标注,支持以精确匹配方式评估系统性能,常用指标包括P@1、MRR和Hit@5。系统需能够从知识库、文本、表格和信息框中检索并融合证据,以应对跨域的复杂查询。基准还包含大量未在现有系统中得到正确答案的挑战性问题,为开发更鲁棒的检索与推理模型提供了方向。
背景与挑战
背景概述
在事实性问答领域,传统研究通常聚焦于单一知识源,如知识库、文本或表格,这限制了系统在复杂信息需求下的覆盖能力。为应对这一局限,马克斯·普朗克信息学研究所的Philipp Christmann、Rishiraj Saha Roy和Gerhard Weikum于2023年推出了COMPMIX基准数据集。该数据集旨在通过整合异构知识源——包括Wikidata知识库、维基百科文本、表格和信息框——来评估问答系统在多样化信息环境中的表现。COMPMIX包含9,410个人工众包问题,涵盖书籍、电影、音乐、电视剧和足球五个领域,其核心研究问题是推动异构知识融合,以提升问答系统的答案覆盖率和置信度,对推动跨源信息检索与自然语言处理技术的融合具有重要影响力。
当前挑战
COMPMIX所解决的领域挑战在于异构知识问答,即如何有效整合来自知识库、文本、表格和信息框的多样化信息,以应对复杂意图如连接操作和时间条件等问题。构建过程中的挑战包括:确保问题自然且需多源回答,避免偏向单一知识源;通过众包收集真实用户问题,涵盖长尾实体和新兴内容,以反映现实场景的复杂性;以及设计统一评估框架,兼容提取式与生成式模型,同时处理实体标识与文本答案的标准化。这些挑战共同凸显了开发鲁棒异构问答系统的迫切需求。
常用场景
经典使用场景
在异构信息检索与问答系统评估领域,COMPMIX数据集为研究者提供了一个天然的测试平台,用于检验模型整合多种知识源的能力。该数据集包含来自书籍、电影、音乐、电视剧和足球五个领域的9410个人工标注问题,每个问题均需联合查询知识库、文本、表格和Infobox等多种异构信息源才能获得准确答案。其经典使用场景在于评估和比较不同异构问答系统的性能,特别是在处理复杂意图如连接操作、时间条件和聚合查询时,系统能否有效融合来自结构化与非结构化数据源的证据。
解决学术问题
COMPMIX数据集主要解决了异构问答研究中长期存在的评估基准单一性问题。传统问答基准往往仅针对单一知识源设计,导致模型在整合多源信息时的真实能力无法被公平衡量。该数据集通过构建必须依赖多种信息源才能解答的问题,为学术界提供了更贴近现实需求的评估环境。其意义在于推动了问答系统从依赖单一知识库或文本向综合利用知识图谱、文本、表格等异构数据的范式转变,促进了跨源检索、证据融合与答案验证等核心研究方向的发展。
实际应用
在实际应用层面,COMPMIX数据集能够指导开发面向真实世界的开放域问答系统。此类系统常需处理用户提出的、答案可能分散在百科知识库、新闻报道、统计表格等多种信息载体中的复杂问题。例如,在体育赛事分析、娱乐信息查询或金融数据解读等场景,系统必须能够同时检索并推理来自不同结构的数据。该数据集通过涵盖长尾实体和复杂查询,助力构建更具鲁棒性的智能助手、搜索引擎和决策支持工具,提升其在多源、动态信息环境下的实用价值。
数据集最近研究
最新研究方向
在事实性问答领域,COMPMIX数据集的推出标志着异构信息源融合研究的前沿进展。该数据集通过涵盖知识库、文本、表格和信息框四种异构源,并聚焦书籍、电影、音乐、电视剧和足球五大领域,为评估系统在真实复杂场景下的多源协同能力提供了天然测试平台。当前研究热点集中于开发能够有效检索、对齐和推理跨源证据的智能模型,以应对数据中存在的时序条件、聚合操作及长尾实体等挑战。尽管现有方法如UNIK-QA和EXPLAIGNN已取得初步进展,但性能仍显不足,而大型语言模型在此任务上的表现也仅达半数准确率,凸显了异构问答在信息互补与冗余利用方面的巨大探索空间。这一基准的建立不仅推动了跨模态检索与融合技术的发展,也为构建更稳健、可解释的问答系统奠定了关键基础。
相关研究论文
- 1CompMix: A Benchmark for Heterogeneous Question Answering马克斯·普朗克信息学研究所 · 2023年
以上内容由遇见数据集搜集并总结生成


