matin-123/mad-cars
收藏Hugging Face2026-04-14 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/matin-123/mad-cars
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-sa-4.0
size_categories:
- 1M<n<10M
pretty_name: Multi-view Auto Dataset
tags:
- autonomous
- driving
- vehicles
- cars
task_categories:
- image-to-video
---
# MAD-Cars: Multi-view Auto Dataset 🚗
## Dataset Description
**MAD-Cars** is a large-scale collection of 360° car videos.
It comprises ~70,000 car instances with diverse brands, car types, colors, and lighting conditions. Each instance contains an average of ~85 frames, with most car instances available at a resolution of 1920x1080. The dataset statistics are presented in the figure below. The data is carefully curated by filtering the frames and entire car instances that can negatively affect 3D reconstruction.
This dataset is introduced in the research paper: \
**"[MADrive: Memory-Augmented Driving Scene Modeling](https://huggingface.co/papers/2506.21520)"**
Project page: https://yandex-research.github.io/madrive/
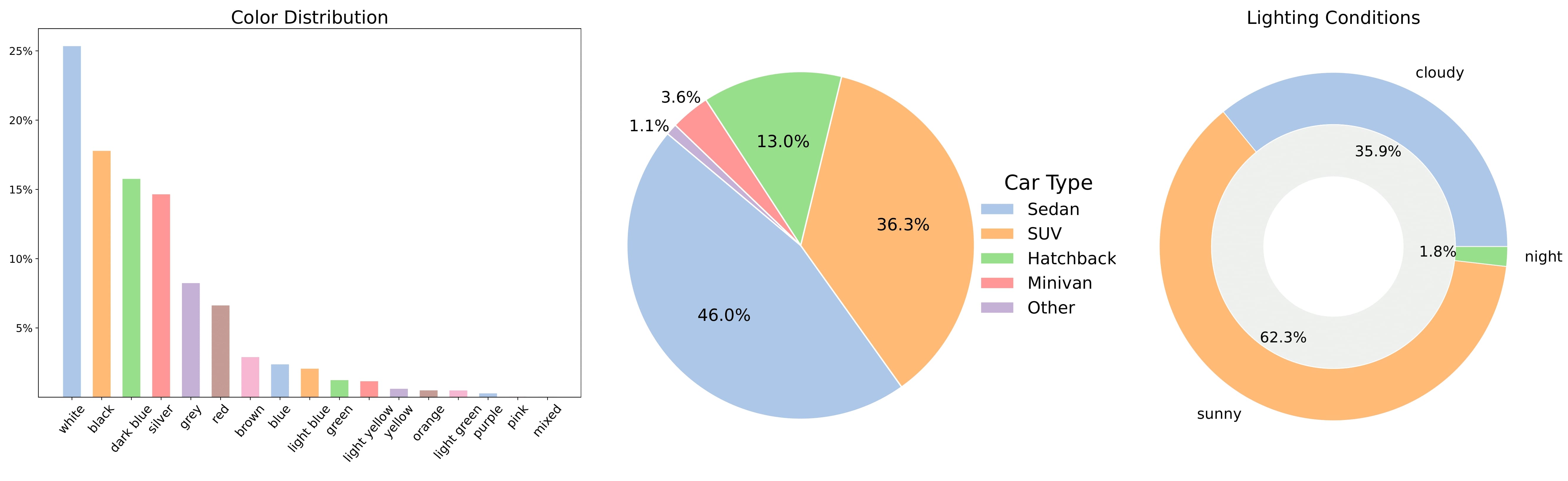
### Data Fields
Each instance in the dataset contains:
* `car_id`: Unique identifier for a single car instance.
* `view_id`: Identifier for a specific view of the car.
* `url`: URL to download the corresponding single car view.
* `color`: RGB color value representing the car's color.
* `brand`: Manufacturer or brand of the car.
* `model`: Specific model name or designation of the car.
Note that `view_id` is not aligned with a particular camera position or angle.
### Data Splits
The dataset contains a single split:
* `train`: 5,884,329 samples.
## Usage
The MAD dataset is designed for novel-view synthesis of cars. [MADrive](https://huggingface.co/papers/2506.21520) exploits this data for the retrieval-augmented driving scene reconstruction.
### Getting Started
**Loading the dataset:**
```python
from datasets import load_dataset
dataset = load_dataset("yandex/mad-cars", split="train")
```
**Exracting the first view:**
```python
from PIL import Image
import requests
from io import BytesIO
response = requests.get(dataset[0]['url'])
image = Image.open(BytesIO(response.content))
```
**Grouping by `car_id`:**
```python
car_id_to_urls = dataset.to_pandas().groupby("car_id")['url'].agg(list)
```
## Citation
```bibtex
@artcile{karpikova2025madrivememoryaugmenteddrivingscene,
title={MADrive: Memory-Augmented Driving Scene Modeling},
author={Polina Karpikova and Daniil Selikhanovych and Kirill Struminsky and Ruslan Musaev and Maria Golitsyna and Dmitry Baranchuk},
year={2025},
eprint={2506.21520},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.21520},
}
```
提供机构:
matin-123


