MasterMind
收藏arXiv2025-03-18 更新2025-03-20 收录
下载链接:
https://huggingface.co/datasets/OpenDILabCommunity/MasterMind
下载链接
链接失效反馈官方服务:
资源简介:
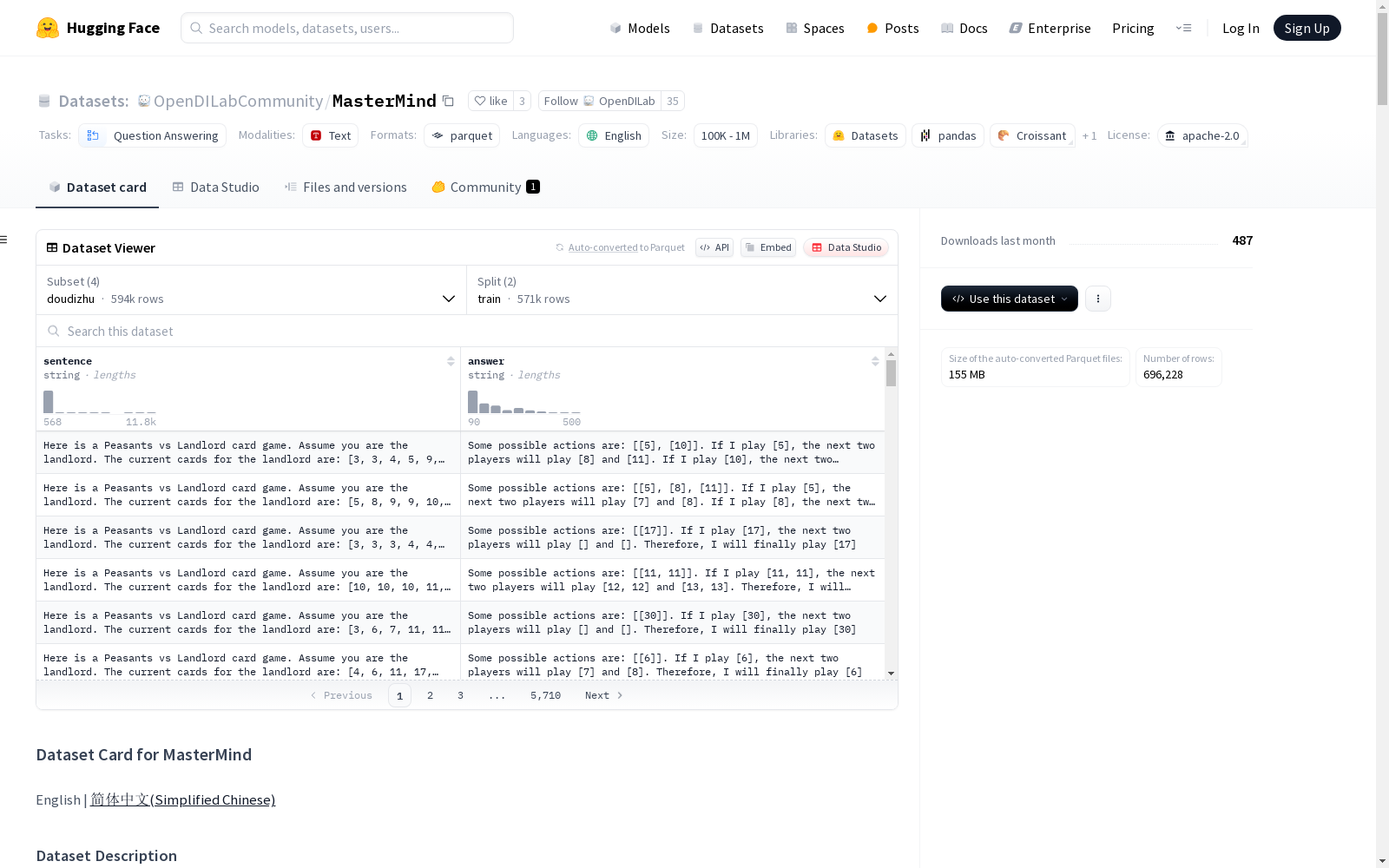
MasterMind数据集是由上海人工智能实验室等机构创建,针对决策游戏设计的数据集。该数据集通过从斗地主和围棋两种经典游戏中合成数据,旨在提升大型语言模型在决策游戏中的推理能力。数据集包含多样化的策略和对手水平,适用于训练LLM以掌握决策游戏的复杂推理和决策制定过程。
The MasterMind Dataset is a curated dataset developed by institutions including the Shanghai AI Laboratory, specifically designed for decision-making games. It synthesizes data from two classic games, Dou Dizhu and Go, with the aim of enhancing the reasoning capabilities of large language models (LLMs) in decision-making game contexts. The dataset features diverse strategies and varying opponent skill levels, making it suitable for training LLMs to master the complex reasoning and decision-making processes involved in decision-making games.
提供机构:
上海人工智能实验室, 北京航空航天大学, 香港中文大学, 新西伯利亚国立大学
创建时间:
2025-03-18
搜集汇总
数据集介绍
构建方式
MasterMind数据集的构建基于两种经典决策游戏——斗地主和围棋。研究人员首先从这些游戏中收集了广泛的离线数据,并通过精心设计的数据合成策略将这些数据转化为适合大语言模型(LLM)训练的文本格式。具体而言,斗地主的数据通过将卡牌映射为整数并简化动作空间来降低复杂性,而围棋的数据则通过将棋盘状态转化为文本表示,并结合KataGo等开源代理生成的分析数据。此外,研究人员还设计了防止模型过拟合的技术,确保模型专注于核心推理过程。
特点
MasterMind数据集的特点在于其多样性和复杂性。斗地主部分包含了不同策略和对手的数据,模拟了真实游戏中的不确定性;围棋部分则通过多层次的推理任务,逐步提升模型对复杂规则和策略的理解。数据集不仅涵盖了游戏的基本规则,还通过自然语言分析增强了模型对游戏状态的理解。此外,数据集还引入了工具函数来辅助模型进行数值计算,减轻了模型的认知负担。
使用方法
MasterMind数据集的使用方法主要包括两个阶段:训练和推理。在训练阶段,研究人员通过混合不同任务的数据样本,使用标准的监督微调(SFT)损失函数对LLM进行微调。推理阶段则通过逐步推理的方式,模型首先预测可能的动作,分析对手的反应,最终选择最优决策。对于围棋任务,模型还通过工具函数进行棋盘状态的数值计算,确保推理的准确性。实验结果表明,经过训练的MasterMind模型在斗地主和围棋任务中表现出色,并在通用推理任务中展现出一定的提升。
背景与挑战
背景概述
MasterMind数据集由上海人工智能实验室、北京航空航天大学、香港中文大学和新西伯利亚国立大学的研究团队于2025年发布,旨在通过决策游戏数据提升大语言模型(LLMs)的复杂推理能力。该数据集基于两种经典游戏——斗地主和围棋,通过数据合成策略生成大量离线数据,并开发了一系列技术将这些数据有效融入LLM的训练中。研究团队提出了两种新型代理:Mastermind-Dou和Mastermind-Go,实验结果表明这些代理在各自游戏中表现出色。此外,研究还探讨了决策游戏数据是否能够提升LLMs的通用推理能力,结果表明这种训练方式能够改善某些推理能力,为LLM数据收集与合成策略的优化提供了重要见解。
当前挑战
MasterMind数据集在构建和应用过程中面临多重挑战。首先,决策游戏本身具有复杂的逻辑结构和多步推理需求,尤其是在斗地主和围棋这类游戏中,模型需要处理不完全信息和复杂的策略规划。其次,数据集的构建过程中,如何将游戏数据转化为适合LLM训练的文本表示形式是一个关键难题。例如,斗地主的动作空间庞大且动态变化,而围棋的二维棋盘信息需要转化为一维序列,同时保留空间关系。此外,模型在训练过程中容易过拟合于特定游戏规则,而忽略核心推理能力的提升。最后,如何确保模型在提升游戏表现的同时,不牺牲其在其他通用推理任务上的能力,也是一个亟待解决的问题。
常用场景
经典使用场景
MasterMind数据集主要用于评估和增强大型语言模型(LLMs)在复杂决策游戏中的推理能力。通过从经典游戏如斗地主和围棋中提取数据,该数据集为LLMs提供了丰富的推理示例,帮助模型在游戏环境中进行多步推理和策略规划。特别是在斗地主和围棋这类需要多层次逻辑推理的游戏中,MasterMind数据集通过精细的数据合成策略,显著提升了模型的表现。
解决学术问题
MasterMind数据集解决了LLMs在复杂推理任务中表现不佳的问题。传统的LLMs虽然在语言理解和生成任务上表现出色,但在需要深层次逻辑推理的决策任务中往往表现欠佳。通过引入决策游戏数据,MasterMind数据集为LLMs提供了新的训练素材,帮助模型在推理过程中更好地模拟人类的逐步思考过程。实验结果表明,经过该数据集训练的模型不仅在特定游戏中表现出色,还在一般推理任务中展现出显著的性能提升。
衍生相关工作
MasterMind数据集衍生了一系列相关研究工作,特别是在LLMs与强化学习(RL)结合的应用中。例如,基于该数据集的研究提出了Mastermind-Dou和Mastermind-Go两种新型代理,分别在斗地主和围棋中表现出色。此外,该数据集还启发了更多关于如何利用游戏数据提升LLMs推理能力的研究,推动了LLMs在复杂决策任务中的应用。
以上内容由遇见数据集搜集并总结生成


