RWKU
收藏Hugging Face2026-03-28 更新2026-03-29 收录
下载链接:
https://huggingface.co/datasets/ngiorgos/RWKU
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含两种配置形式:基础问答数据集(qa)和带释义扩展的问答数据集(qa_with_paraphrases)。基础版本包含三个核心字段:问题(question)、答案(answer)和主题(subject),而扩展版本额外包含问题释义列表(paraphrases)。数据按遗忘等级(forget_level1-3)和邻近等级(neighbor_level1-2)划分,共5个数据分片。基础版本总规模142KB/1,205条样本,扩展版本1.09MB/1,205条样本。适用于问答系统训练、模型遗忘行为研究等场景。
创建时间:
2026-03-23
原始信息汇总
RWKU 数据集概述
数据集基本信息
- 数据集地址:https://huggingface.co/datasets/ngiorgos/RWKU
- 配置数量:2
- 总下载大小:415,173 字节
- 总数据集大小:1,227,638 字节
配置详情
配置一:qa
- 特征:
- question(字符串)
- answer(字符串)
- subject(字符串)
- 数据划分:
- forget_level1:180 个样本,19,315 字节
- forget_level2:143 个样本,14,289 字节
- forget_level3:342 个样本,51,616 字节
- neighbor_level1:270 个样本,30,261 字节
- neighbor_level2:270 个样本,26,775 字节
- 下载大小:63,227 字节
- 数据集大小:142,256 字节
配置二:qa_with_paraphrases
- 特征:
- question(字符串)
- answer(字符串)
- subject(字符串)
- paraphrases(字符串序列)
- 数据划分:
- forget_level1:180 个样本,160,039 字节
- forget_level2:143 个样本,108,426 字节
- forget_level3:342 个样本,363,151 字节
- neighbor_level1:270 个样本,247,604 字节
- neighbor_level2:270 个样本,206,162 字节
- 下载大小:351,946 字节
- 数据集大小:1,085,382 字节
数据文件结构
- 配置
qa的数据文件路径模式:qa/forget_level1-*qa/forget_level2-*qa/forget_level3-*qa/neighbor_level1-*qa/neighbor_level2-*
- 配置
qa_with_paraphrases的数据文件路径模式:qa_with_paraphrases/forget_level1-*qa_with_paraphrases/forget_level2-*qa_with_paraphrases/forget_level3-*qa_with_paraphrases/neighbor_level1-*qa_with_paraphrases/neighbor_level2-*
搜集汇总
数据集介绍
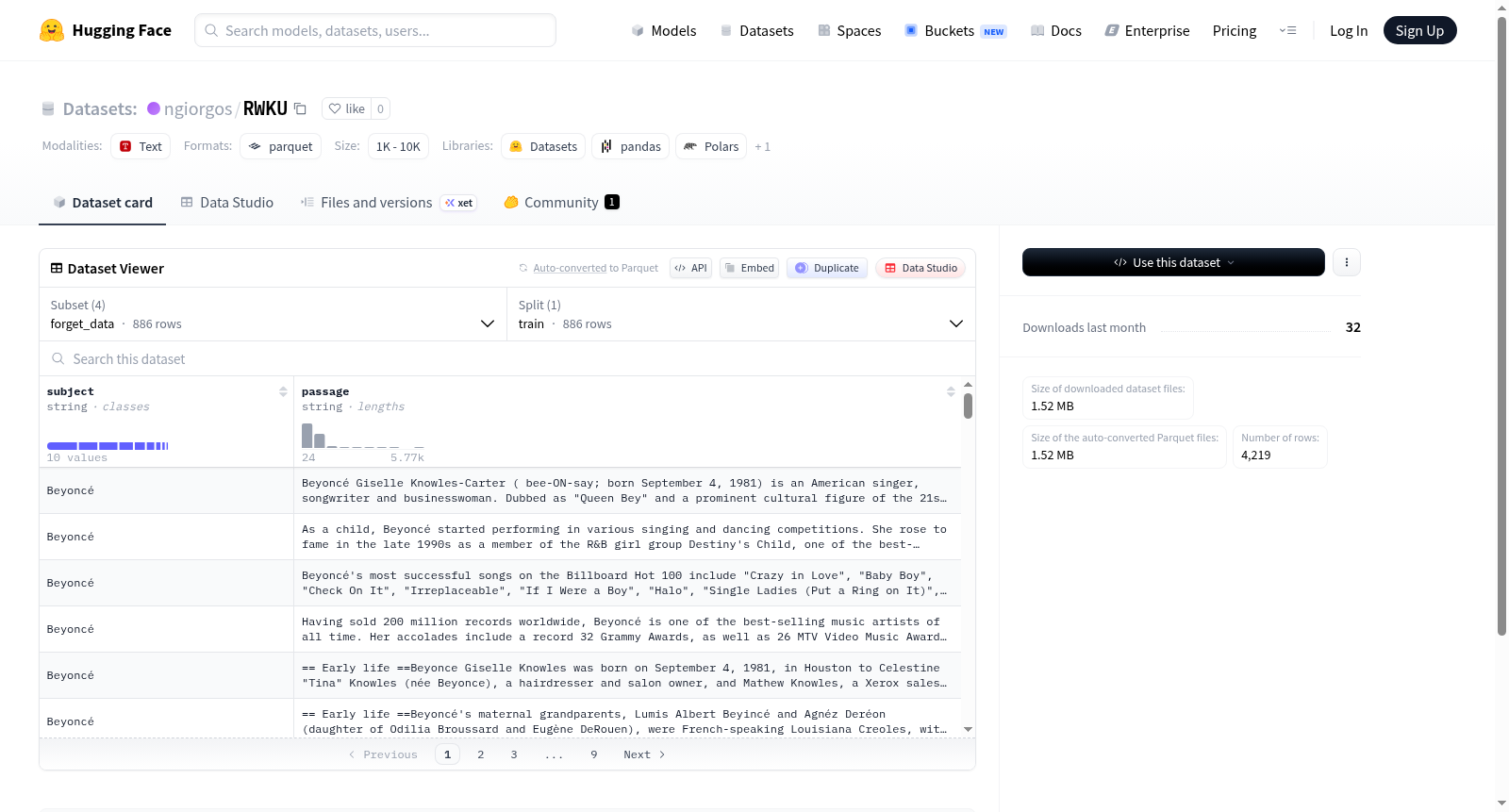
构建方式
在机器遗忘研究领域,RWKU数据集通过精心设计的问答对构建而成,其核心在于模拟知识遗忘的渐进过程。该数据集包含两种配置:基础问答配置(qa)以及带有释义变体的扩展配置(qa_with_paraphrases)。构建时,依据遗忘程度(forget_level1至level3)与邻近知识层级(neighbor_level1至level2)对样本进行系统化划分,每个层级均包含特定数量的问答实例,并辅以详尽的字节与样本数统计,确保了数据结构的层次性与可追溯性。
特点
RWKU数据集的显著特征在于其多维度的知识组织架构。它不仅提供了标准的问题、答案及学科主题字段,更在扩展配置中引入了“释义”序列,为同一问题生成多种语言表达,极大地丰富了语义多样性。数据集通过遗忘层级与邻近层级的交叉划分,精准刻画了知识遗忘的边界效应与关联性,为研究模型在特定知识上的遗忘行为及其对周边知识的影响提供了细腻的观测尺度。
使用方法
使用RWKU数据集时,研究者可根据实验目标灵活选择配置。若需考察模型在核心知识上的遗忘表现,可加载基础问答配置并按遗忘层级分割数据进行评估;若需探究模型对问题表述变化的鲁棒性及遗忘的泛化特性,则应选用带释义的扩展配置。数据文件已按配置名与分割名称清晰组织,支持直接通过指定路径加载相应分割,便于进行对照实验与量化分析,服务于机器遗忘、知识编辑及模型鲁棒性等前沿研究方向。
背景与挑战
背景概述
在机器学习模型安全与伦理研究领域,模型遗忘技术旨在精准移除预训练模型中的特定知识,同时最大程度保留其整体性能。RWKU数据集应运而生,专注于评估模型在知识遗忘任务上的能力。该数据集由研究机构构建,其核心研究问题在于如何量化模型对特定事实的遗忘程度,并区分不同遗忘难度级别。通过提供结构化的问题-答案对及对应学科主题,RWKU为衡量遗忘算法的有效性与泛化性提供了基准,推动了可解释与可控人工智能系统的发展。
当前挑战
RWKU数据集所应对的核心挑战在于模型知识遗忘这一新兴且复杂的领域问题。具体而言,如何定义并量化‘遗忘’本身即构成理论挑战,需在移除目标知识的同时确保模型在其他任务上不出现性能退化。在构建过程中,挑战体现在数据的设计与标注上:需要精心构造具有不同遗忘难度级别(如forget_level1至level3)的样本,并确保‘邻居’样本能有效测试知识的特异性遗忘而非普遍性遗忘。此外,生成高质量、语义一致的释义变体(paraphrases)以增强评估的鲁棒性,也对数据构建的严谨性提出了较高要求。
常用场景
经典使用场景
在机器遗忘与知识编辑领域,RWKU数据集通过结构化的问题-答案对,为评估模型在特定知识上的遗忘与保留能力提供了基准。该数据集以不同遗忘级别和邻近知识层级划分样本,经典使用场景涉及训练大型语言模型执行选择性遗忘任务,研究者利用其量化模型在移除特定信息后对相关或无关知识的保持程度,从而验证遗忘算法的有效性与泛化性。
实际应用
在实际应用中,RWKU数据集被用于开发适应数据合规要求的智能系统,例如在医疗或金融领域,模型需定期删除涉及个人隐私的历史数据。它帮助工程师测试模型在更新或移除特定知识后的稳定性,确保系统在迭代中保持准确与安全,从而满足动态监管环境下的部署需求。
衍生相关工作
围绕RWKU数据集,衍生了一系列经典研究工作,包括基于梯度下降的遗忘算法优化、知识编辑的对抗性评估框架,以及针对多层级遗忘的神经网络架构调整。这些工作不仅深化了对模型记忆机制的理解,还催生了新的评估指标与工具链,促进了机器遗忘领域从理论到实践的跨越。
以上内容由遇见数据集搜集并总结生成


