Enkokilish Bench
收藏github2025-12-07 更新2025-12-08 收录
下载链接:
https://github.com/ScholarXIV/enkokilish_bench
下载链接
链接失效反馈官方服务:
资源简介:
这是一个新的基准测试,专注于评估LLMs理解、推理和解决阿姆哈拉语谜语的能力。所有谜语及其答案都列在datasets/enkokilsh.ts文件中,并将持续更新。
This is a novel benchmark dedicated to evaluating the capabilities of Large Language Models (LLMs) to understand, reason, and solve Amharic riddles. All riddles and their corresponding answers are listed in the datasets/enkokilsh.ts file, and this resource will be continuously updated.
创建时间:
2025-11-29
原始信息汇总
Enkokilish Bench 数据集概述
数据集简介
Enkokilish Bench 是一个专注于评估大型语言模型理解、推理和解决阿姆哈拉语谜语能力的新基准。
核心用途
- 用于评估大型语言模型在阿姆哈拉语谜语上的理解、推理和解决能力。
数据内容
- 所有谜语及其答案均列在
datasets/enkokilsh.ts文件中。 - 数据将持续更新。
技术框架
使用与贡献
- 用户可通过克隆仓库、在
.env文件中设置 AI Gateway API 密钥,并运行pnpm eval:dev来快速设置和探索。 - 鼓励贡献者通过 GitHub 提交已知的 Enkokilish 谜语以丰富数据集。
搜集汇总
数据集介绍
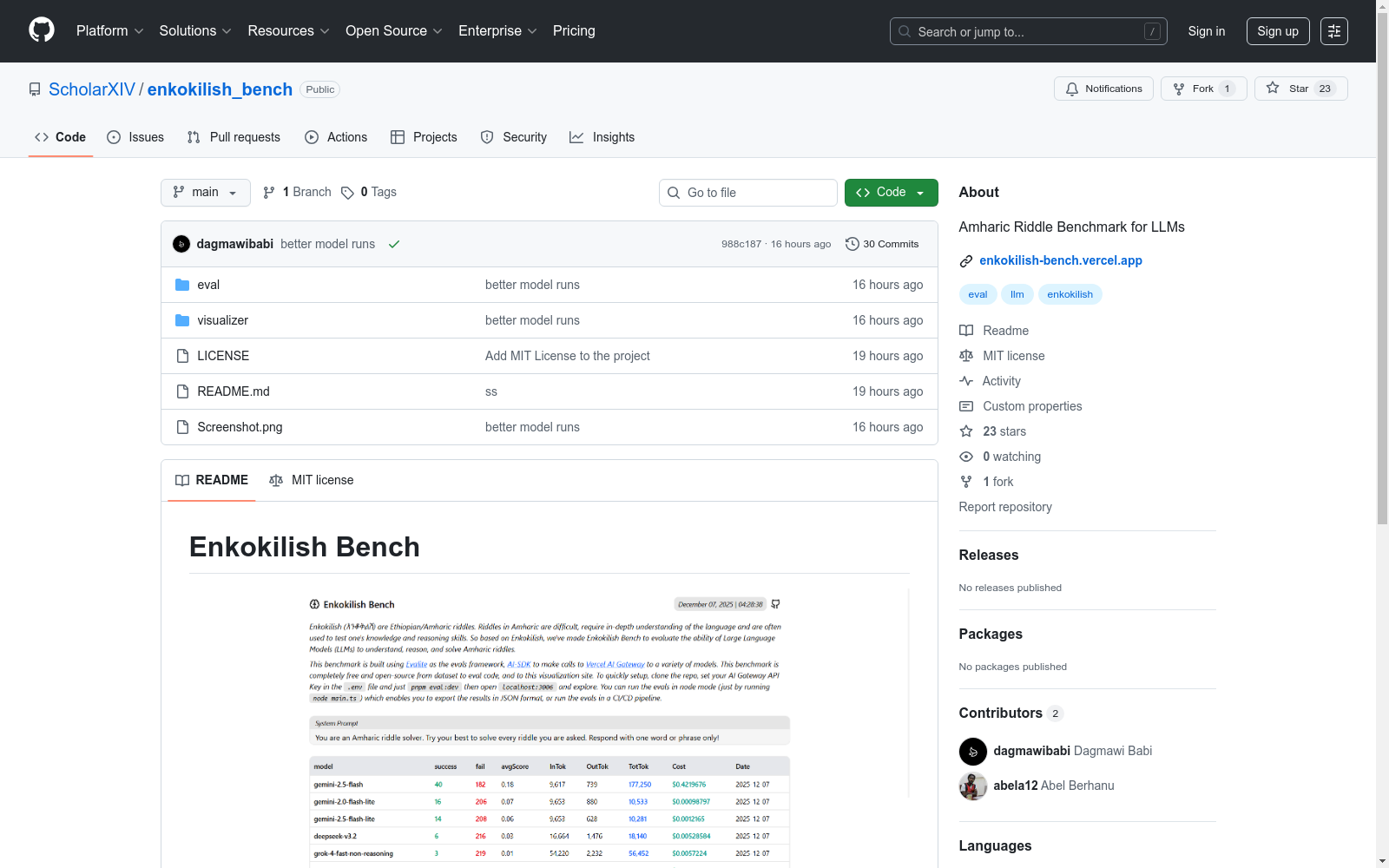
构建方式
在自然语言处理领域,评估模型对低资源语言的理解能力至关重要。Enkokilish Bench的构建依托于Evalite这一类型安全且开源的评价框架,该框架能够高效处理大规模评估任务,并与AI-SDK无缝集成以实现对大型语言模型的调用。数据集的基石来源于精心收集的阿姆哈拉语谜语及其对应答案,这些内容以结构化形式存储于datasets/enkokilsh.ts文件中,并持续通过社区贡献进行动态更新,确保了数据的多样性与时效性。
特点
该数据集专注于阿姆哈拉语这一低资源语言,通过谜语形式考察模型的理解、推理与问题解决能力,填补了现有基准在非洲语言评估方面的空白。其设计具有高度可扩展性,用户可通过简单修改数据集与评估标题,快速适配其他语言或任务类型的基准测试。同时,数据集以开源方式维护,鼓励全球研究者共同丰富内容,促进了跨文化语言资源的共建共享。
使用方法
使用Enkokilish Bench时,用户需克隆项目仓库并在.env文件中配置AI网关API密钥,随后通过pnpm eval:dev命令启动本地评估服务,在浏览器中访问localhost:3000即可交互式探索结果。评估流程完全自动化,系统将依据预设的谜语数据集对目标模型进行测试,并生成直观的性能报告。这种设计降低了技术门槛,使研究者能够专注于模型能力的分析与比较,无需复杂部署即可开展实验。
背景与挑战
背景概述
在自然语言处理领域,大型语言模型(LLMs)的多语言理解能力评估日益成为研究焦点。Enkokilish Bench数据集由ScholarXIV团队于近期创建,专注于评估LLMs对阿姆哈拉语谜语的理解、推理与解答能力。该数据集通过整合Evalite评估框架与AI-SDK工具,旨在填补低资源语言文化背景下语言模型评测的空白,为跨语言人工智能研究提供关键基准,推动模型在非主流语言环境中的认知与逻辑能力发展。
当前挑战
该数据集致力于解决低资源语言环境下LLMs的复杂语义理解与推理挑战,特别是针对阿姆哈拉语这类形态丰富、文化语境独特的语言,模型需克服语言结构差异与文化隐喻解析的困难。在构建过程中,挑战主要集中于高质量阿姆哈拉语谜语数据的收集与标注,需确保谜语的文化准确性与逻辑完整性,同时依赖社区贡献以持续扩展数据集规模,这增加了数据一致性与质量控制难度。
常用场景
经典使用场景
在自然语言处理领域,特别是针对低资源语言的模型评估中,Enkokilish Bench数据集被广泛应用于测试大型语言模型对阿姆哈拉语谜语的理解与推理能力。该数据集通过精心设计的谜语任务,模拟了人类语言认知中的隐喻思维和逻辑推断过程,为模型在复杂语境下的表现提供了标准化评估框架。研究者通常利用这一基准来量化模型在跨语言文化背景下的语义解析和创造性问题解决能力,从而推动多语言人工智能技术的发展。
解决学术问题
该数据集有效解决了自然语言处理研究中低资源语言评估工具匮乏的学术难题。传统评估基准往往集中于英语等主流语言,难以反映模型在语言多样性场景下的真实性能。Enkokilish Bench通过构建阿姆哈拉语谜语评估体系,为研究者提供了衡量模型跨语言迁移能力和文化语境理解的重要标尺,其意义在于打破了语言技术评估中的资源不平衡现象,促进了语言人工智能领域的包容性发展。
衍生相关工作
围绕该数据集已衍生出多项经典研究工作,包括基于Evalite框架的可扩展评估系统构建,以及结合AI-SDK工具链的自动化评测流程设计。部分研究进一步扩展了基准的语言覆盖范围,将谜语评估范式迁移至其他非洲语言,形成了跨语言认知评估的方法论体系。这些工作共同推动了低资源语言评估技术的标准化进程,为后续的语料构建和模型优化研究奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


