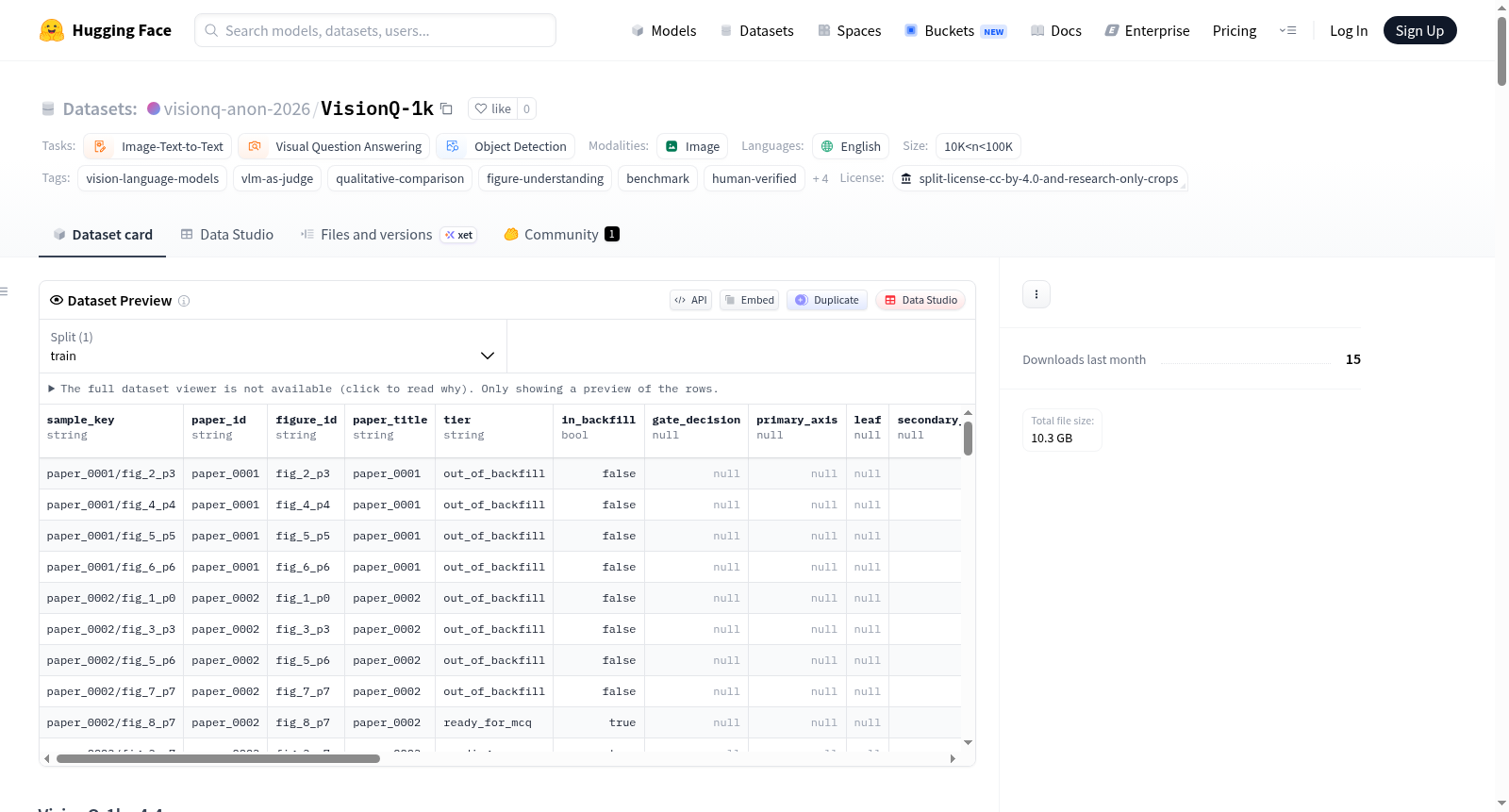
VisionQ-1k
收藏VisionQ-1k 数据集概述
基本信息
- 数据集名称: VisionQ-1k v4.4
- 许可证: 分裂许可证(CC BY 4.0 用于元数据/代码;图像裁剪仅限研究用途)
- 语言: 英语
- 任务类型: 图像-文本到文本、视觉问答、目标检测
- 数据集规模: 10K-100K 样本
核心统计
| 统计指标 | v4.4版本数据 |
|---|---|
| 源论文数量 | 1,399篇 |
| 定性比较图像 | 3,354张 |
| Schema v2边界框标注 | 48,167个 |
| 人工审核图像 | 2,771张(82.6%) |
| — 已批准 | 1,492张 |
| — 已拒绝 | 1,279张 |
| — 待处理 | 583张 |
| 已批准论文 | 908篇 |
| 组级别定性声明记录 | 4,365条 |
| 含胜出方法记录 | 4,160条 |
| 不同提出方法 | 857种 |
数据集构成
边界框类型分布
| 类型 | 占比 |
|---|---|
| 主体(main) | 83.1% |
| 放大(zoom) | 15.3% |
| 辅助(auxiliary) | 1.2% |
| 插图(inset) | 0.4% |
可视化类型分布
| 模态 | 占比 |
|---|---|
| RGB | 67.5% |
| 网格(mesh) | 11.8% |
| 激光雷达(lidar) | 5.7% |
| 深度(depth) | 4.5% |
| 分割(segmentation) | 4.1% |
| 法线(normal) | 2.7% |
| 热力图(heatmap) | 2.7% |
| 误差图(error_map) | 1.0% |
高频方法(按组声明频率排名前5)
- SNB(29次)
- RichDreamer(25次)
- PaletteNeRF(22次)
- SINE(22次)
- ViVid-1-to-3(20次)
Schema v2标注结构
每个边界框包含10个字段,分为四类:
| 关注方面 | 字段 |
|---|---|
| 几何信息 | bbox(xyxy像素坐标)、bbox_id(图像内索引) |
| 方法身份 | method(标准化)、method_raw(图中原文) |
| 场景/行身份 | row(标准化)、row_raw、col_idx(列位置) |
| 语义角色 | bbox_type、viz_type、parent_bbox_id(放大/插图链接) |
数据来源
- 论文来源: CVPR/ICCV/ECCV/NeurIPS/SIGGRAPH 2023-2024
- 领域偏向: 3D视觉任务(NeRF、3DGS、生成式3D、新视角合成、分割)
- 来源PDF不重新分发,仅发布提取的图像裁剪和派生元数据
文件结构
vqc14-release/ ├── paper_NNNN/ # 1,399个论文目录 │ ├── labels.json # 论文级元数据+方法标签 │ ├── paper_text.json # 摘要、正文摘录、标题文本 │ └── figures/ │ └── <fig_id>/ │ ├── figure.png # 高分辨率图像裁剪 │ └── annotations.json # Schema v2边界框记录 ├── master_index.csv # 平坦索引(每张图像一行) ├── data_points.csv # 平坦索引(每个边界框一行) ├── data_points.jsonl # 同上,JSON格式 ├── figures.jsonl # 图像级记录+文本信号 ├── group_qualitative_claims.json # 已验证的组级声明记录 ├── mcq_validations.json # MCQ格式人工验证记录 ├── paper_sources.csv # 论文来源信息 ├── csv_export/ # 扁平CSV导出 ├── eda/ # 描述性图表+EDA报告 ├── docs/ # 模式文档 ├── eval/ # 评估文件(332个测试问题、1,960个DPO对) ├── code/ # 流水线源代码 ├── gallery/ # 示例浏览器 ├── LICENSE └── README.md
评估资源
| 文件 | 记录数 | 用途 |
|---|---|---|
| eval/test_questions.jsonl | 332 | 保留评估集(四选一问题) |
| eval/dpo_pairs.jsonl | 1,960 | DPO偏好记录(训练+评估) |
| code/train_dpo_example.py | — | DPO训练参考脚本 |
已知限制
- 领域偏差: 偏向3D视觉任务(NeRF/3DGS等占约27%)
- 14.9%通用标签: 方法名称提取失败时使用
method_N占位符 - 583张图像待审核: 截至v4.4版本
- 仅英语: 未收集多语言论文
- 无定量-定性配对: 未链接定性图像与定量结果表
- 定性分类器脆弱: 基于9关键词的正则表达式过滤
- 无固定训练/验证/测试划分: 计划中但尚未锁定
- 标注者间一致性未计算: 计划进行100张图像重叠审核