linkanjarad/baize-chat-data
收藏Hugging Face2023-07-20 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/linkanjarad/baize-chat-data
下载链接
链接失效反馈资源简介:
---
language:
- en
tags:
- instruction-finetuning
pretty_name: Baize Chat Data
task_categories:
- text-generation
---
## Dataset Description
**Original Repository:** https://github.com/project-baize/baize-chatbot/tree/main/data
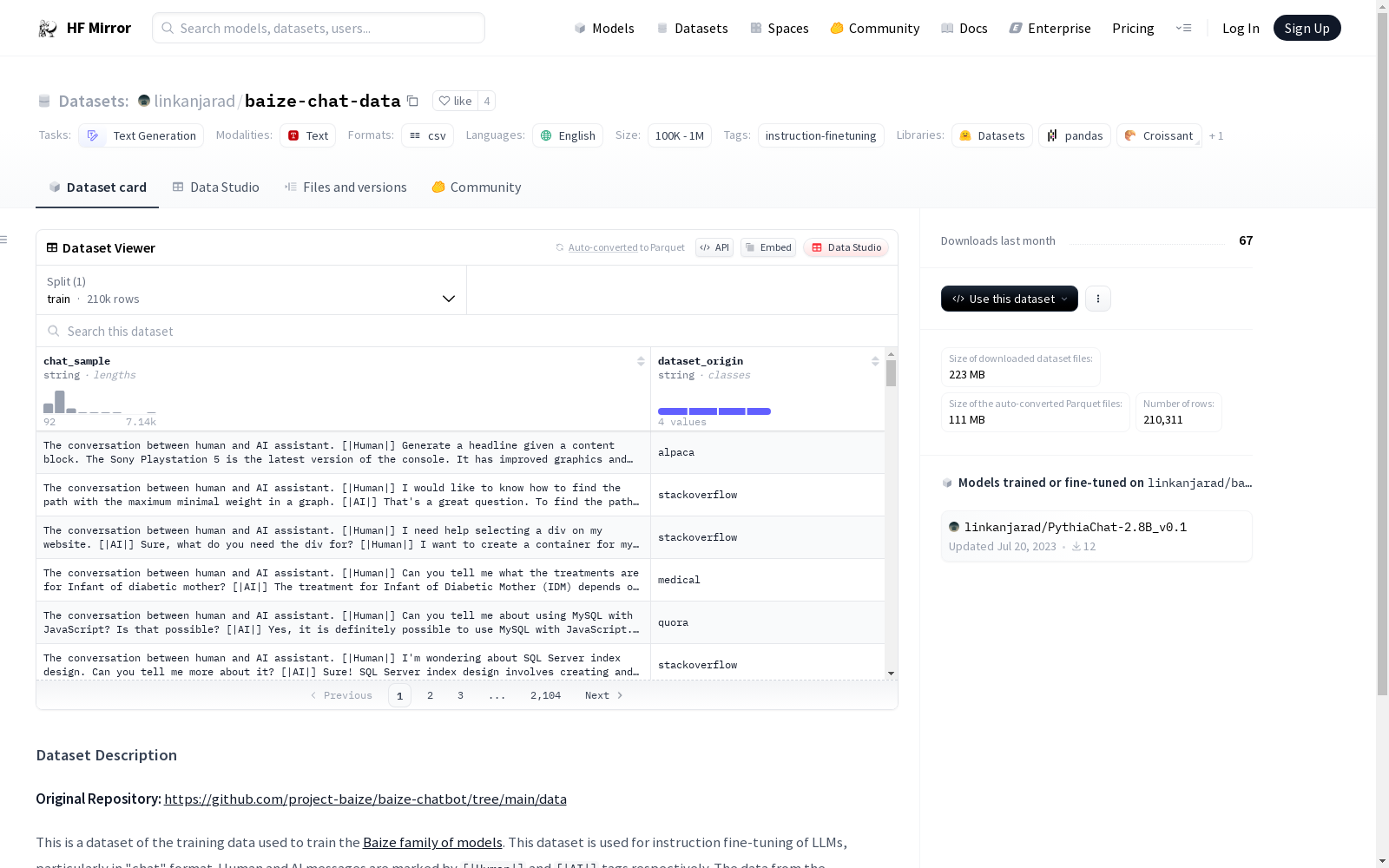
This is a dataset of the training data used to train the [Baize family of models](https://huggingface.co/project-baize/baize-v2-13b). This dataset is used for instruction fine-tuning of LLMs, particularly in "chat" format. Human and AI messages are marked by `[|Human|]` and `[|AI|]` tags respectively. The data from the orignial repo consists of 4 datasets (alpaca, medical, quora, stackoverflow), and this dataset combines all four into one dataset, all in all consisting of about 210K rows.
语言:
- en(英语)
标签:
- instruction-finetuning(指令微调)
展示名称:Baize 聊天数据集
任务类别:
- text-generation(文本生成)
---
**数据集描述**
**原始代码仓库**:https://github.com/project-baize/baize-chatbot/tree/main/data
本数据集为训练[Baize系列模型(Baize family of models)](https://huggingface.co/project-baize/baize-v2-13b)所使用的训练数据集合。该数据集可用于大语言模型(Large Language Model, LLM)的指令微调,尤其适配「聊天」格式的微调场景。人类与AI生成的对话消息分别通过`[|Human|]`与`[|AI|]`标签进行标识。原始仓库中的数据包含4个子数据集(alpaca、medical、quora、stackoverflow),本数据集将这四个子数据集合并为一个整体,总计约21万条数据样本。
提供机构:
linkanjarad
原始信息汇总
数据集概述
数据集名称: Baize Chat Data
语言: 英语(en)
标签: 指令微调(instruction-finetuning)
任务类别: 文本生成(text-generation)
原始仓库链接: Baize Chat Data原始仓库
数据集用途: 用于训练Baize系列模型的训练数据,特别是用于大型语言模型(LLMs)的指令微调,以“聊天”格式进行。
数据结构: 数据集包含人类和AI的消息,分别通过[|Human|]和[|AI|]标签标记。
数据组成: 原始数据来自四个不同的数据集(alpaca, medical, quora, stackoverflow),合并后总共有约210,000行数据。
搜集汇总
数据集介绍
构建方式
针对语言模型在指令微调领域的应用需求,该数据集linkanjarad/baize-chat-data应运而生。数据集的构建者从原始仓库中精心挑选了四个子数据集,分别是alpaca、medical、quora和stackoverflow,将它们融合为一,形成了约210K行的综合数据集。在此过程中,人类与AI的对话内容分别以[|Human|]和[|AI|]标签进行标识,以便模型能够明确区分交流双方,进而进行有效的指令微调训练。
特点
该数据集的特点在于其多样性及适用性。它不仅涵盖了日常对话,还包括了专业领域的交流,如医疗咨询和专业技术问答。这种多样化的数据构成,使得数据集能够适应多种场景下的对话生成任务,为语言模型提供了丰富的学习素材。此外,数据集的规模适中,便于研究者进行高效的模型训练与评估。
使用方法
使用该数据集时,用户首先需要从指定的原始仓库中获取数据。数据集以JSON格式存储,方便用户进行读取和处理。用户可以根据具体的任务需求,对数据集进行相应的预处理,如清洗、格式化等,然后将其应用于指令微调任务,以提升模型在对话生成方面的性能。同时,该数据集也支持跨领域的模型训练,进一步扩展了其应用范围。
背景与挑战
背景概述
Baize Chat Data数据集,源自Baize项目组之手,旨在为大型语言模型(LLM)的指令微调提供训练资源,特别是针对聊天格式。该数据集的创建,汇聚了自2010年代以来自然语言处理领域的进展,特别是对话系统的精细化和个性化需求。该数据集的构建,不仅体现了Baize家族模型对于高质量对话数据的需求,也映射出自然语言处理领域对于真实、多样化对话数据的迫切需要。其约210,000条记录,融合了alpaca、medical、quora、stackoverflow四个子数据集,为研究者在指令微调、对话生成等领域的探索提供了宝贵资源。
当前挑战
尽管Baize Chat Data数据集为对话系统的研究与开发提供了强有力的数据支撑,但其构建过程亦面临着诸多挑战。首先,如何确保从不同来源整合的数据保持一致性和质量,是一大难题。其次,数据标注的一致性和准确性对于后续模型的训练至关重要,而多来源数据的标注难度无疑增加了这一挑战。此外,数据集在解决领域问题如指令微调的同时,还需兼顾隐私保护、避免偏见等伦理问题,这些问题的妥善处理对于数据集的实用性和影响力具有决定性作用。
常用场景
经典使用场景
在自然语言处理领域,Baize Chat Data数据集被广泛用于指令微调大型语言模型,尤其是那些设计用于对话系统的模型。该数据集以其独特的聊天格式,将人类与AI的消息分别标记,为研究者和工程师提供了一个理想的训练环境,以优化LLMs的交互性和响应能力。
实际应用
在实际应用中,Baize Chat Data数据集的应用场景广泛,从智能客服到虚拟助手,它为构建更加智能、互动的人工智能对话系统提供了强有力的数据支持,极大提升了用户体验和服务效率。
衍生相关工作
基于Baize Chat Data数据集,学术界和产业界衍生出了一系列相关研究工作,包括但不限于对话系统的性能评估、多模态交互、以及跨语言对话系统的构建,这些研究进一步推动了自然语言处理技术的发展和应用。
以上内容由遇见数据集搜集并总结生成


