1337xyz1337xyz/leandojo-benchmark4-v10
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/1337xyz1337xyz/leandojo-benchmark4-v10
下载链接
链接失效反馈官方服务:
资源简介:
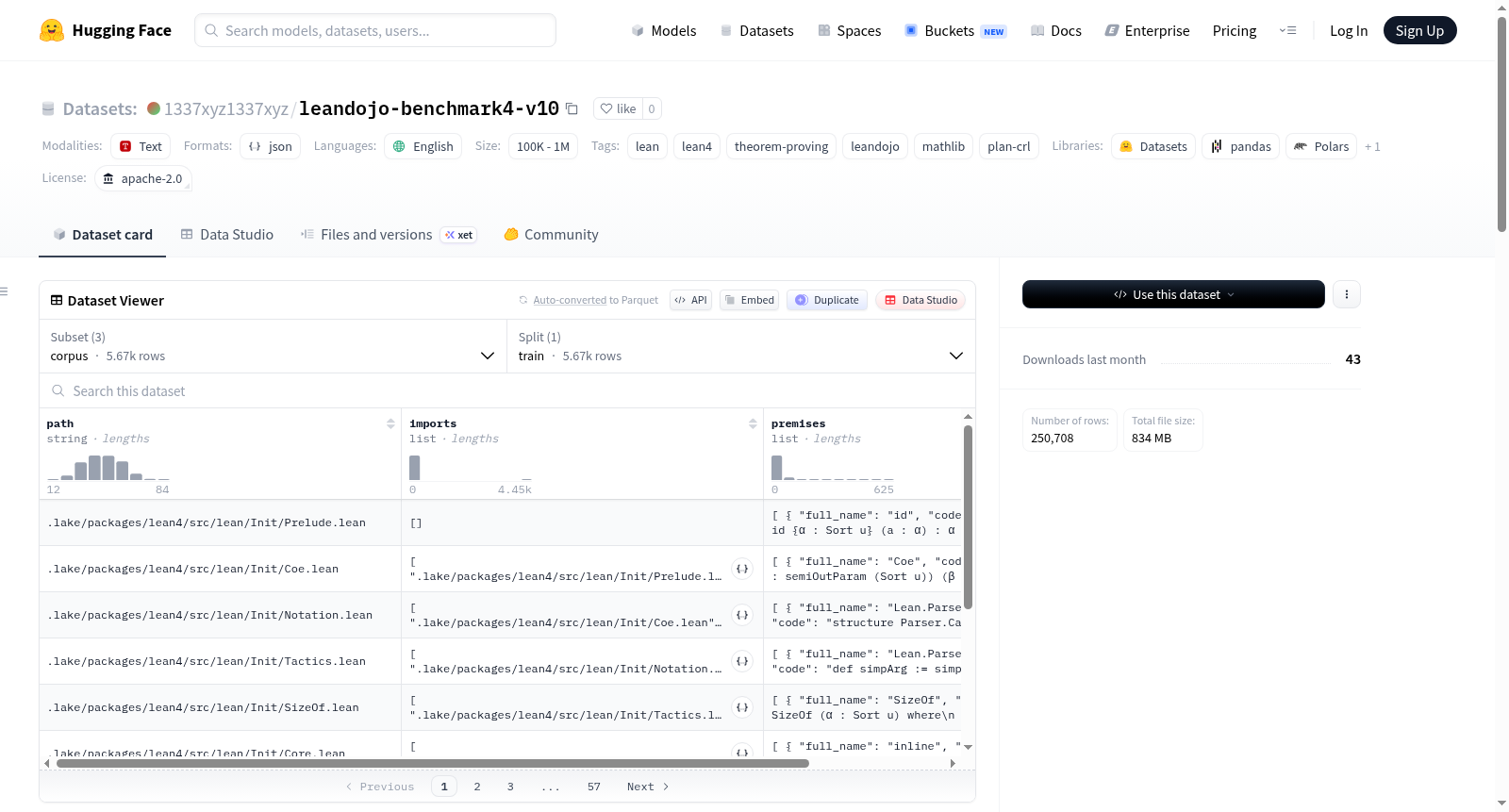
LeanDojo Benchmark 4 v10是一个用于定理证明的数据集,包含两种主要配置:random和novel_premises,每种配置都有训练、验证和测试集。此外,还有一个corpus配置,包含原始corpus.jsonl文件。数据集基于LeanDojo项目,来源于mathlib4仓库的特定提交,创建时间为2024年7月2日。数据集可用于LeanDojo实验,支持通过Hugging Face的datasets库直接加载。
LeanDojo Benchmark 4 v10 is a dataset for theorem proving, containing two main configurations: random and novel_premises, each with training, validation, and test sets. Additionally, there is a corpus configuration that includes the original corpus.jsonl file. The dataset is based on the LeanDojo project, sourced from a specific commit of the mathlib4 repository, and was created on July 2, 2024. The dataset can be used for LeanDojo experiments and supports direct loading via the Hugging Face datasets library.
提供机构:
1337xyz1337xyz
搜集汇总
数据集介绍
构建方式
LeanDojo Benchmark 4 v10 是基于数学定理证明库 mathlib4 构建的标准化评测数据集,其数据源自 GitHub 上 mathlib4 仓库的特定提交版本(commit: 29dcec074de168ac2bf835a77ef68bbe069194c5),经由 LeanDojo 2.0.0 版本工具自动化提取与整理而成。数据集包含两大配置:‘random’ 和 ‘novel_premises’,两者共享相同的训练集(118,517 条)和等量的验证及测试集(各 2,000 条),区别在于测试集的前提条件是否在训练集中出现,以此评估模型对新颖前提的泛化能力。此外,还提供‘corpus’配置,以 JSONL 格式存储完整语料库。原始档案的许可证文件也一并保留。
特点
该数据集的核心特点在于其精细化的拆分设计,能够全面衡量定理证明模型在不同场景下的性能。‘random’ 配置采用随机划分方式,反映模型在常见前提分布下的表现;而 ‘novel_premises’ 配置则刻意选用训练集中未出现过的新颖前提作为测试,专门考察模型对未见知识的推理与迁移能力。这种对比设计使得数据集既可用于标准化性能评估,也可用于研究模型的泛化极限。此外,数据集严格对齐 mathlib4 的官方版本与 LeanDojo 的接口规范,确保了实验的可复现性。
使用方法
研究者可通过 Hugging Face 的 datasets 库直接加载使用,例如通过 load_dataset('1337xyz1337xyz/leandojo-benchmark4-v10', 'random', split='test') 获取随机划分的测试集,或使用同样接口调用 ‘novel_premises’ 配置进行对比实验。若需与 plan-crl 框架整合,则可借助 snapshot_download 下载仓库快照,并将解压后的目录路径作为参数传入 lean_dojo_args.benchmark_data_dir,配合任务标识如 benchmark4_random_test 和指定拆分文件(如 random/test)来运行。数据集以 JSON 格式存储样本,便于解析与扩展。
背景与挑战
背景概述
LeanDojo Benchmark 4 v10 是由加州理工学院等机构的研究团队于2024年7月创建的定理证明基准数据集,隶属于LeanDojo项目,基于Lean 4证明助手和mathlib4数学库开发。该数据集旨在为强化学习驱动的自动定理证明(ATP)系统提供标准化的训练与评估平台,核心研究问题聚焦于如何利用大规模证明脚本(包括前提和策略)训练模型,以提升其在数学定理自动证明中的泛化能力。其影响力体现在推动了利用深度学习和交互式定理证明器相结合的研究范式,为后续如Plan-CRL等方法提供了可复现的实验基础。
当前挑战
该数据集直接服务于自动定理证明这一长期挑战,即如何使机器学习模型能够理解并构造数学证明,面对证明搜索空间巨大、逻辑依赖关系复杂等根本性困难。在构建过程中,挑战包括从mathlib4仓库中高效提取结构化证明数据,处理定理间的细粒度前提依赖关系,以及设计不同难度的数据划分(如随机划分与新颖前提划分),以准确评估模型在未见前提上的推理能力,同时保证数据集规模与覆盖率的平衡。
常用场景
经典使用场景
在形式化定理证明的前沿研究中,LeanDojo Benchmark 4 v10 作为核心基准数据集,被广泛应用于评估和提升基于深度学习的自动定理证明系统的性能。该数据集基于数学库 mathlib4,包含超过十二万条训练样本,并精心设计了随机划分和新奇前提两种测试场景,使得研究者能够系统地衡量模型在已知知识泛化以及面对全新前提时的推理能力。典型的使用方式是将数据集与 Lean 证明环境深度集成,通过策略学习或图神经网络等方法,让智能体在具体定理的证明步骤中不断探索与优化。
解决学术问题
学术界长期面临的一个核心挑战是如何让机器像人类数学家一样进行严谨的符号推理,而 LeanDojo Benchmark 4 v10 精准地回应了这一难题。它提供了大规模、高质量的交互式证明轨迹,使得研究者可以系统性地训练神经定理证明器,从而将机器学习与形式化验证无缝衔接。借助该基准,学者得以深入探究前提选择策略、证明搜索空间缩减以及多步推理中的回溯机制等关键问题。该数据集的发布极大推动了自动定理证明领域的标准化评估,并为后续在数学推理、程序验证方向的理论突破奠定了坚实的数据基础。
衍生相关工作
围绕 LeanDojo Benchmark 4 v10 衍生了许多具有影响力的经典工作,其中最突出的是 Plan-CRL 研究,它通过将高层次的计划策略融入强化学习框架,显著提升了定理证明的搜索效率。此外,基于该数据集的一系列后续工作如 TacticZero 和 COPRA 等,分别探索了在线策略学习和基于上下文的证明预测方法。这些研究不仅验证了基准的有效性,还开创了将结构化规划与深度神经网络相结合的范式,为形式化数学与人工智能的交叉领域贡献了新的理论视角与技术路径。
以上内容由遇见数据集搜集并总结生成


