zzliang/GRIT
收藏Hugging Face2023-07-04 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/zzliang/GRIT
下载链接
链接失效反馈官方服务:
资源简介:
---
license: ms-pl
language:
- en
multilinguality:
- monolingual
pretty_name: GRIT
size_categories:
- 100M<n<1B
source_datasets:
- COYO-700M
tags:
- image-text-bounding-box pairs
- image-text pairs
task_categories:
- text-to-image
- image-to-text
- object-detection
- zero-shot-classification
task_ids:
- image-captioning
- visual-question-answering
---
# GRIT: Large-Scale Training Corpus of Grounded Image-Text Pairs
### Dataset Description
- **Repository:** [Microsoft unilm](https://github.com/microsoft/unilm/tree/master/kosmos-2)
- **Paper:** [Kosmos-2](https://arxiv.org/abs/2306.14824)
### Dataset Summary
We introduce GRIT, a large-scale dataset of Grounded Image-Text pairs, which is created based on image-text pairs from [COYO-700M](https://github.com/kakaobrain/coyo-dataset) and LAION-2B. We construct a pipeline to extract and link text spans (i.e., noun phrases, and referring expressions) in the caption to their corresponding image regions. More details can be found in the [paper](https://arxiv.org/abs/2306.14824).
### Supported Tasks
During the construction, we excluded the image-caption pairs if no bounding boxes are retained. This procedure resulted in a high-quality image-caption subset of COYO-700M, which we will validate in the future.
Furthermore, this dataset contains text-span-bounding-box pairs. Thus, it can be used in many location-aware mono/multimodal tasks, such as phrase grounding, referring expression comprehension, referring expression generation, and open-world object detection.
### Data Instance
One instance is
```python
{
'key': '000373938',
'clip_similarity_vitb32': 0.353271484375,
'clip_similarity_vitl14': 0.2958984375,
'id': 1795296605919,
'url': "https://www.thestrapsaver.com/wp-content/uploads/customerservice-1.jpg",
'caption': 'a wire hanger with a paper cover that reads we heart our customers',
'width': 1024,
'height': 693,
'noun_chunks': [[19, 32, 0.019644069503434333, 0.31054004033406574, 0.9622142865754519, 0.9603442351023356, 0.79298526], [0, 13, 0.019422357885505368, 0.027634161214033764, 0.9593302408854166, 0.969467560450236, 0.67520964]],
'ref_exps': [[19, 66, 0.019644069503434333, 0.31054004033406574, 0.9622142865754519, 0.9603442351023356, 0.79298526], [0, 66, 0.019422357885505368, 0.027634161214033764, 0.9593302408854166, 0.969467560450236, 0.67520964]]
}
```
- `key`: The generated file name when using img2dataset to download COYO-700M (omit it).
- `clip_similarity_vitb32`: The cosine similarity between text and image(ViT-B/32) embeddings by [OpenAI CLIP](https://github.com/openai/CLIP), provided by COYO-700M.
- `clip_similarity_vitl14`: The cosine similarity between text and image(ViT-L/14) embeddings by [OpenAI CLIP](https://github.com/openai/CLIP), provided by COYO-700M.
- `id`: Unique 64-bit integer ID in COYO-700M.
- `url`: The image URL.
- `caption`: The corresponding caption.
- `width`: The width of the image.
- `height`: The height of the image.
- `noun_chunks`: The noun chunks (extracted by [spaCy](https://spacy.io/)) that have associated bounding boxes (predicted by [GLIP](https://github.com/microsoft/GLIP)). The items in the children list respectively represent 'Start of the noun chunk in caption', 'End of the noun chunk in caption', 'normalized x_min', 'normalized y_min', 'normalized x_max', 'normalized y_max', 'confidence score'.
- `ref_exps`: The corresponding referring expressions. If a noun chunk has no expansion, we just copy it.
### Download image
We recommend to use [img2dataset](https://github.com/rom1504/img2dataset) tool to download the images.
1. Download the metadata. You can download it by cloning current repository:
```bash
git lfs install
git clone https://huggingface.co/datasets/zzliang/GRIT
```
2. Install [img2dataset](https://github.com/rom1504/img2dataset).
```bash
pip install img2dataset
```
3. Download images
You need to replace `/path/to/GRIT_dataset/grit-20m` with the local path to this repository.
```bash
img2dataset --url_list /path/to/GRIT_dataset/grit-20m --input_format "parquet"\
--url_col "url" --caption_col "caption" --output_format webdataset \
--output_folder /tmp/grit --processes_count 4 --thread_count 64 --image_size 256 \
--resize_only_if_bigger=True --resize_mode="keep_ratio" --skip_reencode=True \
--save_additional_columns '["id","noun_chunks","ref_exps","clip_similarity_vitb32","clip_similarity_vitl14"]' \
--enable_wandb False
```
You can adjust some parameters according to your actual needs (e.g., `processes_count`, `thread_count`, `image_size`, `save_additional_columns`).
More img2dataset hyper-parameters can be found in [here](https://github.com/rom1504/img2dataset#api).
### Citation Information
If you apply this dataset to any project and research, please cite our paper and coyo-700m:
```
@article{Kosmos2,
title={Kosmos-2: Grounding Multimodal Large Language Models to the World},
author={Zhiliang Peng and Wenhui Wang and Li Dong and Yaru Hao and Shaohan Huang and Shuming Ma and Furu Wei},
journal={ArXiv},
year={2023},
volume={abs/2306.14824}
}
@misc{kakaobrain2022coyo-700m,
title = {COYO-700M: Image-Text Pair Dataset},
author = {Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, Saehoon Kim},
year = {2022},
howpublished = {\url{https://github.com/kakaobrain/coyo-dataset}},
}
```
---
许可证:MS-PL
语言:
- 英语
多语言属性:
- 单语言
数据集名称:GRIT
规模类别:
- 1亿 < 样本数 < 10亿
源数据集:
- COYO-700M
标签:
- 图像-文本边界框配对
- 图像-文本配对
任务类别:
- 文本到图像
- 图像到文本
- 目标检测
- 零样本分类
任务子项:
- 图像字幕
- 视觉问答
---
# GRIT:带锚定信息的大规模图像-文本对训练语料库
### 数据集描述
- **仓库地址:** [Microsoft unilm](https://github.com/microsoft/unilm/tree/master/kosmos-2)
- **论文链接:** [Kosmos-2](https://arxiv.org/abs/2306.14824)
### 数据集概述
我们推出了GRIT,一个带锚定信息的大规模图像-文本对数据集,其构建基础源自[COYO-700M](https://github.com/kakaobrain/coyo-dataset)与LAION-2B中的图像-文本对。我们搭建了一套流水线,用于提取字幕中的文本片段(即名词短语与指代表达),并将其与对应的图像区域进行关联。更多细节可查阅[相关论文](https://arxiv.org/abs/2306.14824)。
### 支持任务
在数据集构建过程中,我们剔除了未保留边界框的图像-字幕对。该流程得到了COYO-700M的高质量图像-字幕子集,我们将在后续对其进行验证。
此外,本数据集包含文本片段-边界框配对数据,因此可应用于多种位置感知的单模态与多模态任务,例如短语锚定、指代表达理解、指代表达生成以及开放世界目标检测。
### 数据实例
单个数据实例如下:
python
{
'key': '000373938',
'clip_similarity_vitb32': 0.353271484375,
'clip_similarity_vitl14': 0.2958984375,
'id': 1795296605919,
'url': "https://www.thestrapsaver.com/wp-content/uploads/customerservice-1.jpg",
'caption': 'a wire hanger with a paper cover that reads we heart our customers',
'width': 1024,
'height': 693,
'noun_chunks': [[19, 32, 0.019644069503434333, 0.31054004033406574, 0.9622142865754519, 0.9603442351023356, 0.79298526], [0, 13, 0.019422357885505368, 0.027634161214033764, 0.9593302408854166, 0.969467560450236, 0.67520964]],
'ref_exps': [[19, 66, 0.019644069503434333, 0.31054004033406574, 0.9622142865754519, 0.9603442351023356, 0.79298526], [0, 66, 0.019422357885505368, 0.027634161214033764, 0.9593302408854166, 0.969467560450236, 0.67520964]]
}
- `key`:使用img2dataset下载COYO-700M时生成的文件名(可省略)。
- `clip_similarity_vitb32`:由COYO-700M提供的、基于[OpenAI CLIP](https://github.com/openai/CLIP)计算的文本与图像(ViT-B/32)嵌入的余弦相似度。
- `clip_similarity_vitl14`:由COYO-700M提供的、基于[OpenAI CLIP](https://github.com/openai/CLIP)计算的文本与图像(ViT-L/14)嵌入的余弦相似度。
- `id`:COYO-700M中的唯一64位整数标识符。
- `url`:图像的下载链接。
- `caption`:对应的图像字幕。
- `width`:图像的宽度。
- `height`:图像的高度。
- `noun_chunks`:由[spaCy](https://spacy.io/)提取的名词短语,其关联了由[GLIP](https://github.com/microsoft/GLIP)预测的边界框。子列表中的元素依次代表「字幕中名词短语的起始位置」、「字幕中名词短语的结束位置」、「归一化后的x_min」、「归一化后的y_min」、「归一化后的x_max」、「归一化后的y_max」以及「置信度得分」。
- `ref_exps`:对应的指代表达。若某名词短语无扩展形式,则直接复制该名词短语。
### 图像下载
我们推荐使用[img2dataset](https://github.com/rom1504/img2dataset)工具下载图像。
1. 下载元数据:可通过克隆当前仓库获取:
bash
git lfs install
git clone https://huggingface.co/datasets/zzliang/GRIT
2. 安装[img2dataset](https://github.com/rom1504/img2dataset):
bash
pip install img2dataset
3. 下载图像:
你需要将命令中的`/path/to/GRIT_dataset/grit-20m`替换为该仓库的本地路径。
bash
img2dataset --url_list /path/to/GRIT_dataset/grit-20m --input_format "parquet"
--url_col "url" --caption_col "caption" --output_format webdataset
--output_folder /tmp/grit --processes_count 4 --thread_count 64 --image_size 256
--resize_only_if_bigger=True --resize_mode="keep_ratio" --skip_reencode=True
--save_additional_columns '["id","noun_chunks","ref_exps","clip_similarity_vitb32","clip_similarity_vitl14"]'
--enable_wandb False
你可根据实际需求调整部分参数(例如`processes_count`、`thread_count`、`image_size`、`save_additional_columns`)。
更多img2dataset的超参数可查阅[官方文档](https://github.com/rom1504/img2dataset#api)。
### 引用信息
若你将本数据集应用于项目或研究中,请引用我们的论文与COYO-700M:
bibtex
@article{Kosmos2,
title={Kosmos-2: Grounding Multimodal Large Language Models to the World},
author={Zhiliang Peng and Wenhui Wang and Li Dong and Yaru Hao and Shaohan Huang and Shuming Ma and Furu Wei},
journal={ArXiv},
year={2023},
volume={abs/2306.14824}
}
@misc{kakaobrain2022coyo-700m,
title = {COYO-700M: Image-Text Pair Dataset},
author = {Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, Saehoon Kim},
year = {2022},
howpublished = {url{https://github.com/kakaobrain/coyo-dataset}},
}
提供机构:
zzliang
原始信息汇总
GRIT: Large-Scale Training Corpus of Grounded Image-Text Pairs
数据集描述
- 名称: GRIT
- 语言: 英语
- 多语言性: 单语
- 大小: 100M<n<1B
- 来源数据集: COYO-700M
- 许可证: MS-PL
- 标签:
- 图像-文本-边界框对
- 图像-文本对
- 任务类别:
- 文本到图像
- 图像到文本
- 目标检测
- 零样本分类
- 任务ID:
- 图像字幕生成
- 视觉问答
数据集概要
GRIT是一个基于COYO-700M和LAION-2B构建的大规模图像-文本对数据集。该数据集通过提取和链接文本片段(如名词短语和指称表达)到相应的图像区域,支持多种位置感知单/多模态任务,如短语定位、指称表达理解、指称表达生成和开放世界目标检测。
数据实例
每个数据实例包含以下字段:
key: 文件名(忽略)clip_similarity_vitb32: 文本与图像(ViT-B/32)嵌入的余弦相似度clip_similarity_vitl14: 文本与图像(ViT-L/14)嵌入的余弦相似度id: 唯一IDurl: 图像URLcaption: 对应字幕width: 图像宽度height: 图像高度noun_chunks: 名词短语及其关联边界框ref_exps: 对应的指称表达
下载图像
推荐使用img2dataset工具下载图像,具体步骤包括下载元数据和安装img2dataset,然后根据提供的命令行参数下载图像。
引用信息
使用此数据集时,请引用相关论文和COYO-700M数据集。
搜集汇总
数据集介绍
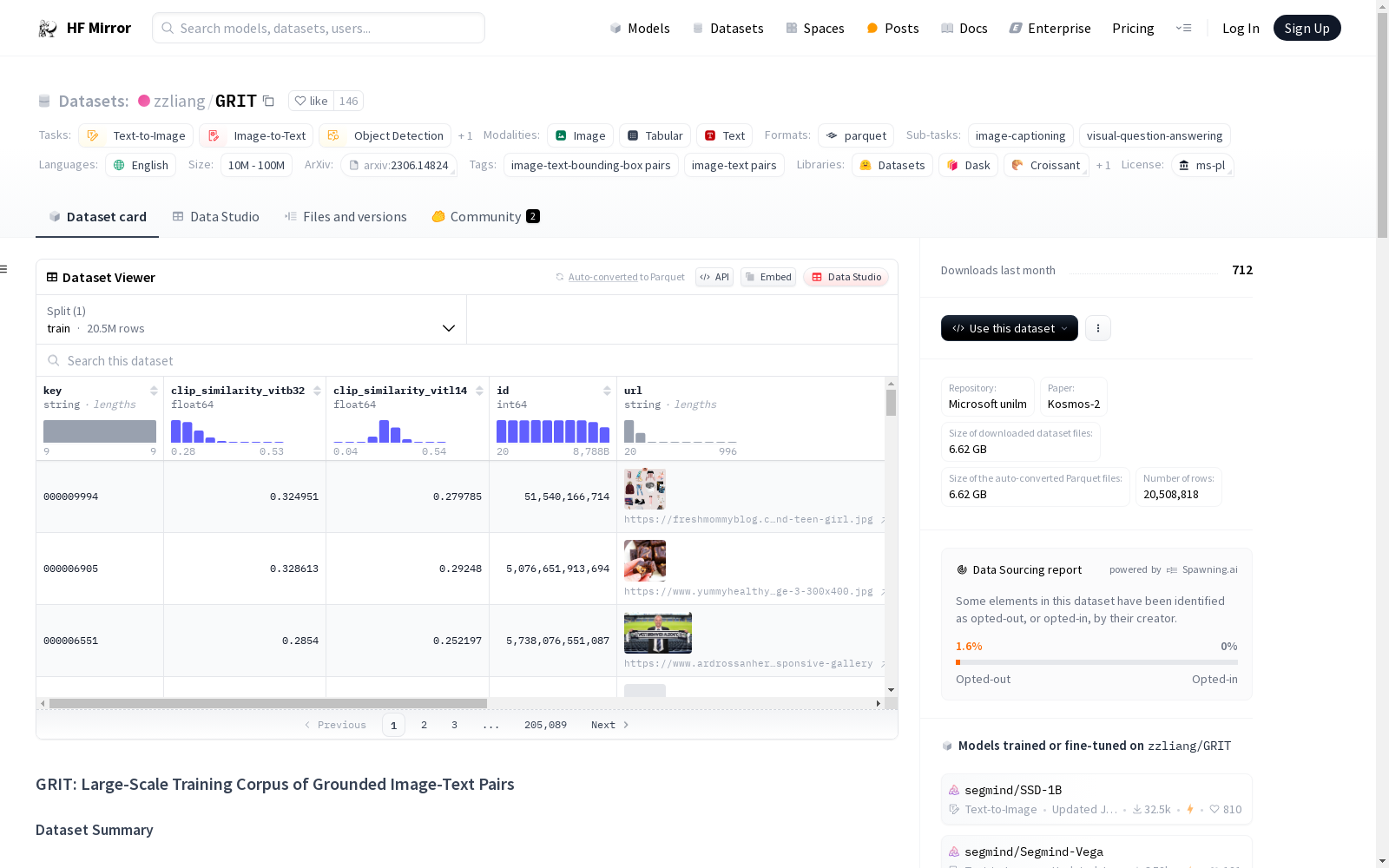
构建方式
GRIT数据集是基于COYO-700M和LAION-2B图像文本对构建的大规模地面图像文本对训练语料库。通过设计专门的管道,该数据集从图像字幕中提取并链接文本片段(例如名词短语和指代表达式)到相应的图像区域,旨在为多模态任务提供精确的定位信息。
使用方法
使用GRIT数据集时,推荐使用img2dataset工具下载图像。用户需先下载元数据,安装img2dataset,然后根据需要调整相关参数以下载图像。数据集的元数据包含图像URL、字幕、图像尺寸以及与图像相关的文本片段和边界框信息等,用户可根据具体任务需求进行选择和应用。
背景与挑战
背景概述
GRIT数据集,全称为Grounded Image-Text pairs,是由Microsoft unilm团队基于COYO-700M和LAION-2B图像文本对构建的大规模训练语料库。该数据集的创建旨在为图像与文本结合的多模态任务提供高质量的训练资源,其构建工作基于2023年的研究论文《Kosmos-2: Grounding Multimodal Large Language Models to the World》。GRIT数据集通过提取并链接图像描述中的文本跨度(如名词短语和参照表达式)与其对应的图像区域,为多模态任务提供了丰富的标注数据。该数据集的构建对于推动图像理解、视觉问答以及零样本分类等领域的学术研究和应用发展具有重要价值。
当前挑战
在构建GRIT数据集的过程中,研究团队面临了多项挑战。首先,如何精确地从图像描述中提取名词短语和参照表达式,并将其准确链接到图像中的对应区域,是构建过程中的一个关键挑战。其次,数据集在构建过程中需要保证图像与文本的高质量对应,因此对于没有保留的边界框的图像描述对被排除,这要求了高精度的自动标注技术。此外,GRIT数据集的构建和应用还面临如何有效支持多种位置感知的单模态及多模态任务的挑战,这需要不断优化数据集的结构和内容,以适应不同的研究需求。
常用场景
经典使用场景
在当前计算机视觉与自然语言处理交叉领域,GRIT数据集以其大规模的图像-文本配对和精确的文本跨度定位,成为了文本到图像生成、视觉问答、指代表达理解与生成等任务的重要资源。该数据集通过提供图像与文本的精准对应关系,使得研究者能够训练模型理解和生成图像中的具体内容。
解决学术问题
GRIT数据集解决了学术研究中如何将图像内容与文本描述有效结合的问题,特别是在细粒度定位和指代表达方面的挑战。它的构建为视觉定位任务提供了高质量的标注数据,极大地推动了图像理解与生成任务的进展,为相关领域的研究提供了新的视角和工具。
实际应用
在实际应用中,GRIT数据集的应用场景广泛,包括但不限于智能图像编辑、图像搜索、内容推荐系统等。它能够帮助改进机器学习模型对图像内容的理解和描述,进而提升用户体验和系统性能。
数据集最近研究
最新研究方向
在当前自然语言处理与计算机视觉的交叉领域,GRIT数据集以其大规模的图像-文本配对及精细的定位信息,正引领着研究的新潮流。该数据集不仅为图像字幕和视觉问答任务提供了高质量的子集,更为指代表达式理解和生成、开放世界对象检测等位置感知的多模态任务开辟了新的研究方向。GRIT的构建,使得研究者能够探索如何更精准地将文本描述与图像内容相关联,这对于提升多模态模型的性能和实用性具有重要的意义。
以上内容由遇见数据集搜集并总结生成


