IndoorVG-coco-format
收藏Hugging Face2026-03-09 更新2026-03-10 收录
下载链接:
https://huggingface.co/datasets/maelic/IndoorVG-coco-format
下载链接
链接失效反馈官方服务:
资源简介:
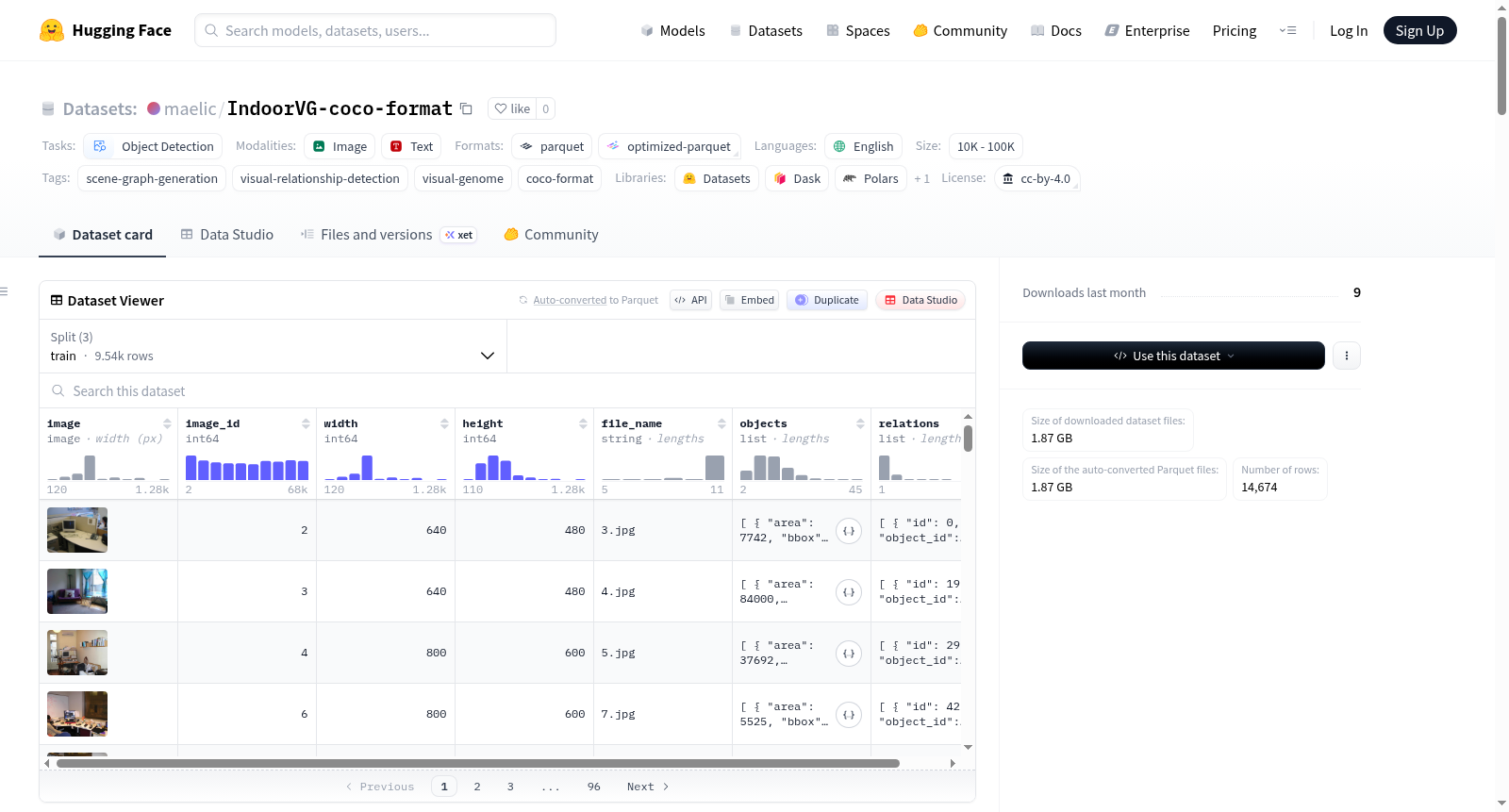
IndoorVG 是一个专注于室内场景(如厨房、办公室、客厅等)的 Visual Genome 数据集精选子集,以标准的 COCO-JSON 格式重新组织。该数据集由 Neau 等人(2024)提出,旨在减少原始 VG150 数据集中的标签噪声和歧义,特别关注室内相关概念。数据集包含 84 个室内物体类别和 37 个谓词类别,经过人工选择和半自动合并。数据集分为训练集(9,538 张图像,125,411 个物体标注,72,291 个关系)、验证集(733 张图像,10,246 个物体标注,4,866 个关系)和测试集(4,403 张图像,61,278 个物体标注,29,367 个关系)。每张图像包含物体边界框和场景图关系(即主体、谓词、客体的有向三元组)。数据集适用于物体检测和场景图生成任务,并可与 pycocotools API 兼容使用。
创建时间:
2026-03-08
原始信息汇总
IndoorVG — Indoor Visual Genome (COCO format) 数据集概述
数据集简介
IndoorVG 是 Visual Genome 数据集的精选子集,专注于真实世界的室内场景(如厨房、办公室、客厅等)。该数据集由 Neau 等人(2024)提出,并在此重新格式化为标准的 COCO-JSON 格式。它是 SGG-Benchmark 框架的一部分,并用于训练 REACT 论文中描述的模型。
核心特征
- 任务类别:目标检测。
- 标签:场景图生成、视觉关系检测、Visual Genome、COCO 格式。
- 语言:英语。
- 数据规模:10K < n < 100K。
- 许可证:CC BY 4.0。
标注内容
每张图像包含:
- 目标边界框:涵盖 84 个室内焦点目标类别。
- 场景图关系:包含 37 个谓词类别,以有向的
(主体, 谓词, 客体)三元组形式连接目标对。
数据集统计
| 数据分割 | 图像数量 | 目标标注数量 | 关系数量 |
|---|---|---|---|
| 训练集 | 9,538 | 125,411 | 72,291 |
| 验证集 | 733 | 10,246 | 4,866 |
| 测试集 | 4,403 | 61,278 | 29,367 |
类别信息
- 目标类别 (84个):经过人工整理的室内词汇,例如包、篮子、垃圾桶、百叶窗、书、瓶子、碗、橱柜、天花板、椅子等。完整列表内嵌于
dataset_info.description中。 - 谓词类别 (37个):包括 above、against、at、attached to、behind、between、carrying、covering、cutting、drinking、eating、filled with、for、hanging from、has、holding、in、in front of、laying on、looking at、lying on、mounted on、near、of、on、playing with、reading、sitting at、sitting on、standing on、taking、talking on、under、using、watching、wearing、with。
数据结构
数据集为 DatasetDict 格式,包含 train、val、test 三个分割。每个数据项包含以下字段:
| 字段名 | 类型 | 描述 |
|---|---|---|
image |
Image |
PIL 图像 |
image_id |
int |
原始 Visual Genome 图像 ID |
width / height |
int |
图像尺寸 |
file_name |
str |
原始文件名 |
objects |
List[dict] |
目标标注列表,字典键包括 id、category_id、bbox (xywh)、area、iscrowd、segmentation |
relations |
List[dict] |
关系标注列表,字典键包括 id、subject_id、object_id、predicate_id(ID 指向 objects[*].id) |
使用方式
可通过 Hugging Face datasets 库加载数据集。标签映射信息内嵌于数据集的 description 元数据中。该数据集可与经过修改的 pycocotools API 配合使用,用于场景图生成任务。
引用
若使用本数据集,请引用:
- IndoorVG 相关论文。
- Visual Genome 原始论文。
- 若使用 SGG-Benchmark 模型,请引用 REACT 论文。
许可证
Visual Genome 图像及标注依据知识共享署名 4.0 国际许可协议发布。
搜集汇总
数据集介绍
构建方式
在视觉关系检测领域,IndoorVG数据集源于对大规模视觉知识库Visual Genome的精细化重构。该数据集通过人工筛选与半自动合并策略,从原始数据中提炼出84个室内场景相关的物体类别与37个谓词类别,有效降低了标签噪声与语义模糊性。构建过程聚焦于厨房、办公室、客厅等真实室内环境,将图像与标注转换为标准COCO-JSON格式,确保了与主流检测框架的兼容性,为室内场景理解提供了结构化的数据基础。
特点
IndoorVG数据集的核心特征在于其针对室内场景的深度标注体系。每张图像不仅包含物体边界框,还标注了以主谓宾三元组形式呈现的场景图关系,如“椅子在桌子旁”或“人拿着杯子”。数据集中涵盖的物体与谓词类别均经过室内场景相关性筛选,形成了紧凑而富有表现力的语义空间。其标注规模包含近1.5万张图像、约20万物体标注与10万余条关系,为模型学习复杂室内视觉关系提供了丰富且高质量的监督信号。
使用方法
该数据集可通过Hugging Face的datasets库直接加载,其数据结构与COCO格式完全对齐,便于集成至现有物体检测与场景图生成流程。用户可利用内置元数据快速映射类别标识至语义名称,并借助专为场景图优化的pycocotools扩展进行关系查询与索引。数据集支持训练、验证与测试的标准划分,适用于端到端的关系检测模型训练、跨模态推理研究,以及服务机器人等室内交互系统的视觉理解模块开发。
背景与挑战
背景概述
IndoorVG数据集由Maëlic Neau等研究人员于2024年提出,作为视觉基因组(Visual Genome)的一个精细化子集,专注于室内场景的视觉理解。该数据集源自华盛顿大学等机构创建的Visual Genome项目,旨在解决室内环境下的场景图生成与视觉关系检测问题。通过精心筛选84个室内物体类别和37个谓词类别,IndoorVG显著减少了原始数据中的标签噪声与歧义,为服务机器人、人机交互等领域的开放世界推理提供了高质量基准。其采用标准COCO-JSON格式重构,进一步促进了与现有计算机视觉框架的兼容性,推动了室内场景语义理解研究的发展。
当前挑战
在视觉关系检测领域,室内场景的复杂性与物体交互的多样性构成了核心挑战。IndoorVG致力于精准刻画室内环境中物体间的空间、功能与语义关系,例如“椅子在桌子下”或“人拿着杯子”,这要求模型具备细粒度的视觉推理能力。数据构建过程中,研究人员面临原始Visual Genome数据标签嘈杂、类别冗余的问题,通过人工筛选与半自动合并策略,在保留室内相关概念的同时,减少了标注不一致性。此外,将异构的视觉基因组数据转换为结构化COCO格式,需确保边界框、关系三元组等注释的完整映射,以支撑场景图生成任务的模型训练与评估。
常用场景
经典使用场景
在计算机视觉领域,室内场景理解是推动智能系统环境感知能力的关键环节。IndoorVG数据集专注于室内环境,为场景图生成任务提供了经典的应用平台。研究者利用其标注的对象边界框与关系三元组,训练模型从图像中提取结构化语义表示,例如识别厨房中“人坐在椅子上”或“瓶子放在桌子上”等复杂视觉关系。这种结构化输出为高级视觉推理奠定了坚实基础,使得模型能够超越简单的物体检测,深入理解室内场景中对象间的交互与空间布局。
解决学术问题
视觉关系检测与场景图生成长期面临标注噪声大、类别模糊的挑战。IndoorVG通过精心筛选84个室内对象类别与37个谓词类别,显著降低了原始Visual Genome数据集的歧义性。该数据集有效解决了室内场景下细粒度关系建模的学术难题,为评估模型在真实、复杂环境中的语义理解能力提供了标准化基准。其意义在于促进了视觉与语言关联研究的发展,推动了面向开放世界交互的机器人视觉系统的算法进步。
衍生相关工作
围绕IndoorVG数据集,已衍生出一系列重要的研究工作。其本身源于SGG-Benchmark框架,并用于训练REACT模型,该工作专注于在场景图生成中权衡实时效率与预测精度。这些研究进一步探索了在计算资源受限的机器人平台上的部署可行性。同时,该数据集的COCO标准化格式也促进了与现有物体检测及关系检测管道的无缝集成,激励了更多针对室内场景的迁移学习、少样本学习及领域自适应方法的创新。
以上内容由遇见数据集搜集并总结生成


