---
annotations_creators:
- expert-generated
language: []
language_creators:
- expert-generated
license:
- cc-by-4.0
multilinguality: []
pretty_name: YALTAi Tabular Dataset
size_categories:
- n<1K
source_datasets: []
tags:
- manuscripts
- LAM
task_categories:
- object-detection
task_ids: []
---
# YALTAi Segmonto Manuscript and Early Printed Book Dataset
## Table of Contents
- [YALTAi Segmonto Manuscript and Early Printed Book Dataset](#Segmonto Manuscript and Early Printed Book Dataset)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://doi.org/10.5281/zenodo.6814770](https://doi.org/10.5281/zenodo.6814770)
- **Paper:** [https://arxiv.org/abs/2207.11230](https://arxiv.org/abs/2207.11230)
### Dataset Summary
This dataset contains a subset of data used in the paper [You Actually Look Twice At it (YALTAi): using an object detection approach instead of region segmentation within the Kraken engine](https://arxiv.org/abs/2207.11230). This paper proposes treating page layout recognition on historical documents as an object detection task (compared to the usual pixel segmentation approach). This dataset contains images from digitised manuscripts and early printed books with the following labels:
- DamageZone
- DigitizationArtefactZone
- DropCapitalZone
- GraphicZone
- MainZone
- MarginTextZone
- MusicZone
- NumberingZone
- QuireMarksZone
- RunningTitleZone
- SealZone
- StampZone
- TableZone
- TitlePageZone
### Supported Tasks and Leaderboards
- `object-detection`: This dataset can be used to train a model for object-detection on historic document images.
## Dataset Structure
This dataset has two configurations. These configurations both cover the same data and annotations but provide these annotations in different forms to make it easier to integrate the data with existing processing pipelines.
- The first configuration, `YOLO`, uses the data's original format.
- The second configuration converts the YOLO format into a format closer to the `COCO` annotation format. This is done to make it easier to work with the `feature_extractor` from the `Transformers` models for object detection, which expect data to be in a COCO style format.
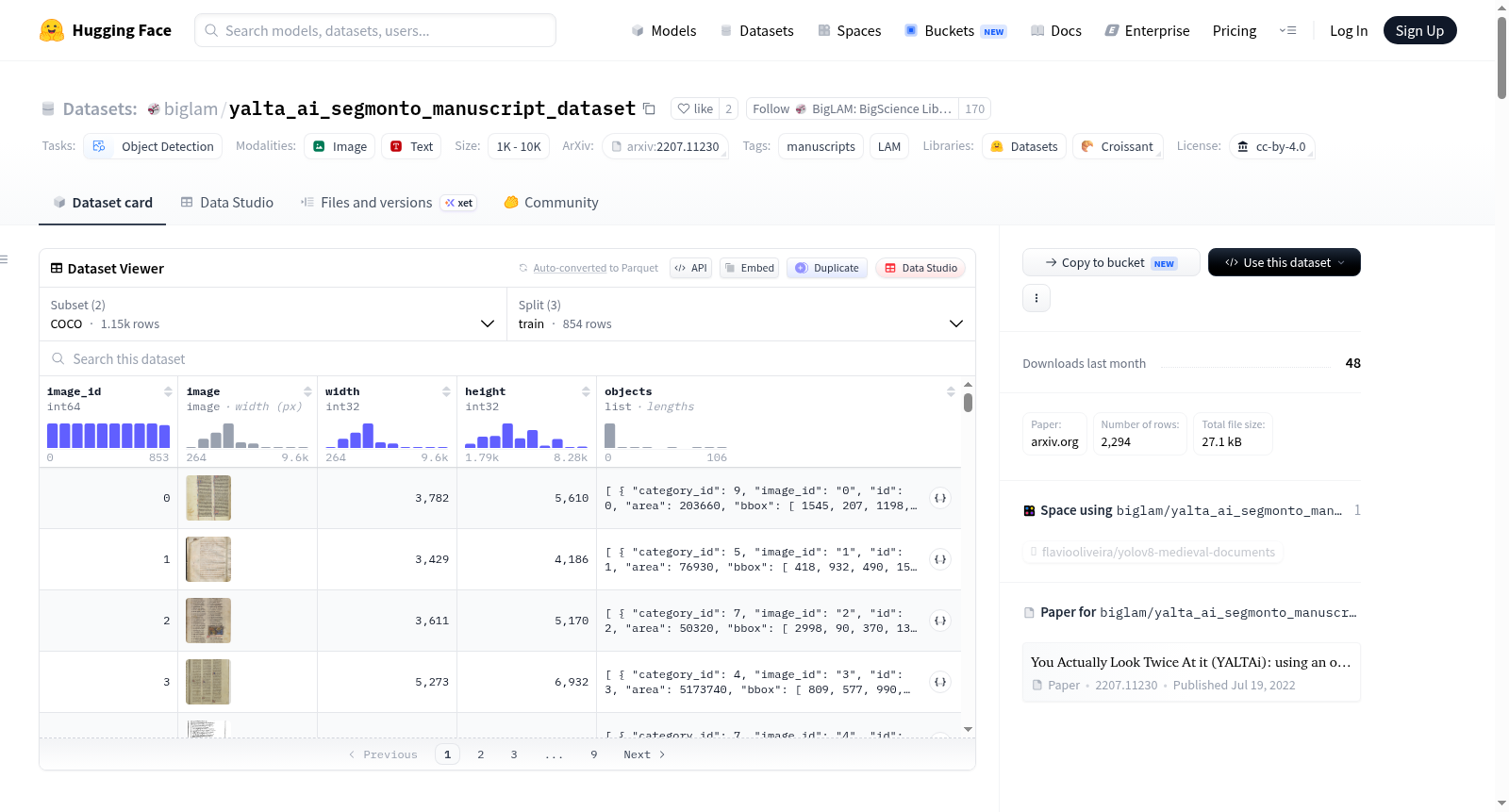
### Data Instances
An example instance from the COCO config:
```python
{'height': 5610,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=3782x5610 at 0x7F3B785609D0>,
'image_id': 0,
'objects': [{'area': 203660,
'bbox': [1545.0, 207.0, 1198.0, 170.0],
'category_id': 9,
'id': 0,
'image_id': '0',
'iscrowd': False,
'segmentation': []},
{'area': 137034,
'bbox': [912.0, 1296.0, 414.0, 331.0],
'category_id': 2,
'id': 0,
'image_id': '0',
'iscrowd': False,
'segmentation': []},
{'area': 110865,
'bbox': [2324.0, 908.0, 389.0, 285.0],
'category_id': 2,
'id': 0,
'image_id': '0',
'iscrowd': False,
'segmentation': []},
{'area': 281634,
'bbox': [2308.0, 3507.0, 438.0, 643.0],
'category_id': 2,
'id': 0,
'image_id': '0',
'iscrowd': False,
'segmentation': []},
{'area': 5064268,
'bbox': [949.0, 471.0, 1286.0, 3938.0],
'category_id': 4,
'id': 0,
'image_id': '0',
'iscrowd': False,
'segmentation': []},
{'area': 5095104,
'bbox': [2303.0, 539.0, 1338.0, 3808.0],
'category_id': 4,
'id': 0,
'image_id': '0',
'iscrowd': False,
'segmentation': []}],
'width': 3782}
```
An example instance from the YOLO config:
```python
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=3782x5610 at 0x7F3B785EFA90>,
'objects': {'bbox': [[2144, 292, 1198, 170],
[1120, 1462, 414, 331],
[2519, 1050, 389, 285],
[2527, 3828, 438, 643],
[1593, 2441, 1286, 3938],
[2972, 2444, 1338, 3808]],
'label': [9, 2, 2, 2, 4, 4]}}
```
### Data Fields
The fields for the YOLO config:
- `image`: the image
- `objects`: the annotations which consist of:
- `bbox`: a list of bounding boxes for the image
- `label`: a list of labels for this image
The fields for the COCO config:
- `height`: height of the image
- `width`: width of the image
- `image`: image
- `image_id`: id for the image
- `objects`: annotations in COCO format, consisting of a list containing dictionaries with the following keys:
- `bbox`: bounding boxes for the images
- `category_id`: a label for the image
- `image_id`: id for the image
- `iscrowd`: COCO is a crowd flag
- `segmentation`: COCO segmentation annotations (empty in this case but kept for compatibility with other processing scripts)
### Data Splits
The dataset contains a train, validation and test split with the following numbers per split:
| Dataset | Number of images |
|---------|------------------|
| Train | 854 |
| Dev | 154 |
| Test | 139 |
A more detailed summary of the dataset (copied from the paper):
| | Train | Dev | Test | Total | Average area | Median area |
|--------------------------|------:|----:|-----:|------:|-------------:|------------:|
| DropCapitalZone | 1537 | 180 | 222 | 1939 | 0.45 | 0.26 |
| MainZone | 1408 | 253 | 258 | 1919 | 28.86 | 26.43 |
| NumberingZone | 421 | 57 | 76 | 554 | 0.18 | 0.14 |
| MarginTextZone | 396 | 59 | 49 | 504 | 1.19 | 0.52 |
| GraphicZone | 289 | 54 | 50 | 393 | 8.56 | 4.31 |
| MusicZone | 237 | 71 | 0 | 308 | 1.22 | 1.09 |
| RunningTitleZone | 137 | 25 | 18 | 180 | 0.95 | 0.84 |
| QuireMarksZone | 65 | 18 | 9 | 92 | 0.25 | 0.21 |
| StampZone | 85 | 5 | 1 | 91 | 1.69 | 1.14 |
| DigitizationArtefactZone | 1 | 0 | 32 | 33 | 2.89 | 2.79 |
| DamageZone | 6 | 1 | 14 | 21 | 1.50 | 0.02 |
| TitlePageZone | 4 | 0 | 1 | 5 | 48.27 | 63.39 |
## Dataset Creation
This dataset is derived from:
- CREMMA Medieval ( Pinche, A. (2022). Cremma Medieval (Version Bicerin 1.1.0) [Data set](https://github.com/HTR-United/cremma-medieval)
- CREMMA Medieval Lat (Clérice, T. and Vlachou-Efstathiou, M. (2022). Cremma Medieval Latin [Data set](https://github.com/HTR-United/cremma-medieval-lat)
- Eutyches. (Vlachou-Efstathiou, M. Voss.Lat.O.41 - Eutyches "de uerbo" glossed [Data set](https://github.com/malamatenia/Eutyches)
- Gallicorpora HTR-Incunable-15e-Siecle ( Pinche, A., Gabay, S., Leroy, N., & Christensen, K. Données HTR incunable du 15e siècle [Computer software](https://github.com/Gallicorpora/HTR-incunable-15e-siecle)
- Gallicorpora HTR-MSS-15e-Siecle ( Pinche, A., Gabay, S., Leroy, N., & Christensen, K. Données HTR manuscrits du 15e siècle [Computer software](https://github.com/Gallicorpora/HTR-MSS-15e-Siecle)
- Gallicorpora HTR-imprime-gothique-16e-siecle ( Pinche, A., Gabay, S., Vlachou-Efstathiou, M., & Christensen, K. HTR-imprime-gothique-16e-siecle [Computer software](https://github.com/Gallicorpora/HTR-imprime-gothique-16e-siecle)
+ a few hundred newly annotated data, specifically the test set which is completely novel and based on early prints and manuscripts.
These additional annotations were created by correcting an early version of the model developed in the paper using the [roboflow](https://roboflow.com/) platform.
### Curation Rationale
[More information needed]
### Source Data
The sources of the data are described above.
#### Initial Data Collection and Normalization
[More information needed]
#### Who are the source language producers?
[More information needed]
### Annotations
#### Annotation process
Additional annotations produced for this dataset were created by correcting an early version of the model developed in the paper using the [roboflow](https://roboflow.com/) platform.
#### Who are the annotators?
[More information needed]
### Personal and Sensitive Information
This data does not contain information relating to living individuals.
## Considerations for Using the Data
### Social Impact of Dataset
A growing number of datasets are related to page layout for historical documents. This dataset offers a different approach to annotating these datasets (focusing on object detection rather than pixel-level annotations). Improving document layout recognition can have a positive impact on downstream tasks, in particular Optical Character Recognition.
### Discussion of Biases
Historical documents contain a wide variety of page layouts. This means that the ability of models trained on this dataset to transfer to documents with very different layouts is not guaranteed.
### Other Known Limitations
[More information needed]
## Additional Information
### Dataset Curators
### Licensing Information
[Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/legalcode)
### Citation Information
```
@dataset{clerice_thibault_2022_6814770,
author = {Clérice, Thibault},
title = {{YALTAi: Segmonto Manuscript and Early Printed Book
Dataset}},
month = jul,
year = 2022,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.6814770},
url = {https://doi.org/10.5281/zenodo.6814770}
}
```
[](https://doi.org/10.5281/zenodo.6814770)
### Contributions
Thanks to [@davanstrien](https://github.com/davanstrien) for adding this dataset.