SWHL/table_rec_test_dataset
收藏Hugging Face2024-04-12 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/SWHL/table_rec_test_dataset
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- translation
language:
- zh
- en
tags:
- code
size_categories:
- n<1K
---
## 表格识别测试集
### 数据集简介
- 数据集包括18张表格的图像,包括拍照类型、截图类型的有线和无线表格。
- 该数据集可以结合[表格指标评测库-TableRecognitionMetric](https://github.com/SWHL/TableRecognitionMetric)使用,快速评测各种表格还原算法。
- **关于该数据集,欢迎小伙伴贡献更多数据呦!有任何想法,可以前往[issue](https://github.com/SWHL/TableRecognitionMetric/issues)讨论。**
### 数据集支持的任务
可用于自定义数据集下的模型验证和性能评估等。
### 数据集的格式和结构
#### 数据格式
数据集只有测试集,仅用于客观评估算法表现。
```text
data
└── test
├── 000cce9ca593055d4618466e823e6d7c.jpg
├── 0aNtiNtRRLqEZ9y6PuShtAAAACMAAQED.jpg
├── 116d6b07ecfdae7721bd6bbf31031c1a.jpg
├── 18bc90cb646c109d22ba44565b9a58bc3095e6d3.jpg
├── 1e7d7fed671a9f9043edd57874ef1b13587afa8d.jpg
├── 20200211182342519549-0.jpg
├── 6a8f24150a396470ab29a5ff29aa959dfe7f1c57.jpg
├── Snipaste_2023-07-05_14-54-25.jpg
├── Snipaste_2023-07-05_14-54-58.jpg
├── Snipaste_2023-07-05_14-58-59.jpg
├── Snipaste_2023-07-05_15-00-55.jpg
├── metadata.jsonl
├── row_span.jpg
├── table2.jpg
├── table3.jpg
├── table4.jpg
├── table6.jpg
├── table7.jpg
└── table_recognition.jpg
```
#### 数据集加载方式
```python
from datasets import load_dataset
dataset = load_dataset("SWHL/table_rec_test_dataset")
test_data = dataset['test']
print(test_data)
```
### 数据集生成的相关信息
#### 原始数据
数据来源于网络,如侵删。
#### 数据集标注
数据集标注为html格式,示例如下:
```text
<html><body><table><tr><td colspan="2">Textln让机器像人类一样理解文字</td></tr><tr><td>Textln产品</td><td>产品描述</td></tr><tr><td>TextinServerAPI文字识别产品</td><td>通用文本识别、表格识别、卡证识别、票据识别、定制识别等识别产品</td></tr><tr><td>TextinMobileSDK图像处理与文字识别SDK</td><td>图像处理,文本、卡证、票据识别和信息提取移动端SDK</td></tr><tr><td>TextlnStudio文字识别训练平台</td><td>OCR自定义模版配置和机器学习训练平台</td></tr><tr><td>Textin企业A/管理平台</td><td>企业AI接入监控统计和渠道业务管理平台</td></tr><tr><td>Textin财报机器人</td><td>财务报表智能分类、识别、提取、匹配、试算产品</td></tr><tr><td>Textin合同比对机器人</td><td>合同多版本差异智能比对产品</td></tr><tr><td>Textin解决方案</td><td>结合客户业务场景和TextIn能力的场景解决方案</td></tr></table></body></html>
```
许可证:Apache-2.0
任务类别:翻译
语言:中文、英文
标签:代码
数据规模:样本量少于1000
## 表格识别测试集
### 数据集简介
- 本数据集包含18张表格图像,涵盖拍摄获取与截图获取的有线表格与无线表格。
- 本数据集可配合[表格指标评测库-TableRecognitionMetric](https://github.com/SWHL/TableRecognitionMetric)使用,用于快速评估各类表格还原算法的性能。
- **欢迎各位同仁为本数据集贡献更多数据!如有任何建议或想法,可前往[issue](https://github.com/SWHL/TableRecognitionMetric/issues)进行讨论。**
### 数据集支持的任务
可用于自定义数据集场景下的模型验证与性能评估等任务。
### 数据集的格式和结构
#### 数据格式
本数据集仅包含测试集,仅用于客观评估算法性能。
text
data
└── test
├── 000cce9ca593055d4618466e823e6d7c.jpg
├── 0aNtiNtRRLqEZ9y6PuShtAAAACMAAQED.jpg
├── 116d6b07ecfdae7721bd6bbf31031c1a.jpg
├── 18bc90cb646c109d22ba44565b9a58bc3095e6d7c.jpg
├── 1e7d7fed671a9f9043edd57874ef1b13587afa8d.jpg
├── 20200211182342519549-0.jpg
├── 6a8f24150a396470ab29a5ff29aa959dfe7f1c57.jpg
├── Snipaste_2023-07-05_14-54-25.jpg
├── Snipaste_2023-07-05_14-54-58.jpg
├── Snipaste_2023-07-05_14-58-59.jpg
├── Snipaste_2023-07-05_15-00-55.jpg
├── metadata.jsonl
├── row_span.jpg
├── table2.jpg
├── table3.jpg
├── table4.jpg
├── table6.jpg
├── table7.jpg
└── table_recognition.jpg
#### 数据集加载方式
python
from datasets import load_dataset
dataset = load_dataset("SWHL/table_rec_test_dataset")
test_data = dataset['test']
print(test_data)
### 数据集生成的相关信息
#### 原始数据
本数据集数据来源于网络,若涉及侵权请联系我们删除。
#### 数据集标注
本数据集的标注采用HTML格式,示例如下:
text
<html><body><table><tr><td colspan="2">Textln让机器像人类一样理解文字</td></tr><tr><td>Textln产品</td><td>产品描述</td></tr><tr><td>TextinServerAPI文字识别产品</td><td>通用文本识别、表格识别、卡证识别、票据识别、定制识别等识别产品</td></tr><tr><td>TextinMobileSDK图像处理与文字识别SDK</td><td>图像处理,文本、卡证、票据识别和信息提取移动端SDK</td></tr><tr><td>TextlnStudio文字识别训练平台</td><td>光学字符识别(Optical Character Recognition,简称OCR)自定义模板配置和机器学习训练平台</td></tr><tr><td>Textin企业A/管理平台</td><td>企业AI接入监控统计和渠道业务管理平台</td></tr><tr><td>Textin财报机器人</td><td>财务报表智能分类、识别、提取、匹配、试算产品</td></tr><tr><td>Textin合同比对机器人</td><td>合同多版本差异智能比对产品</td></tr><tr><td>Textin解决方案</td><td>结合客户业务场景和TextIn能力的场景解决方案</td></tr></table></body></html>
提供机构:
SWHL
原始信息汇总
数据集概述
数据集基本信息
- 许可证: Apache-2.0
- 任务类别: 翻译
- 语言: 中文、英文
- 标签: 代码
- 数据集大小: 小于1K
数据集简介
- 包含18张表格图像,涵盖拍照类型和截图类型的有线和无线表格。
- 可与表格指标评测库-TableRecognitionMetric结合使用,用于快速评测表格还原算法。
数据集支持的任务
- 用于自定义数据集下的模型验证和性能评估。
数据集的格式和结构
- 数据格式: 仅包含测试集,用于客观评估算法表现。
- 数据结构: 数据集目录结构如下: text data └── test ├── 000cce9ca593055d4618466e823e6d7c.jpg ├── 0aNtiNtRRLqEZ9y6PuShtAAAACMAAQED.jpg ├── 116d6b07ecfdae7721bd6bbf31031c1a.jpg ├── 18bc90cb646c109d22ba44565b9a58bc3095e6d3.jpg ├── 1e7d7fed671a9f9043edd57874ef1b13587afa8d.jpg ├── 20200211182342519549-0.jpg ├── 6a8f24150a396470ab29a5ff29aa959dfe7f1c57.jpg ├── Snipaste_2023-07-05_14-54-25.jpg ├── Snipaste_2023-07-05_14-54-58.jpg ├── Snipaste_2023-07-05_14-58-59.jpg ├── Snipaste_2023-07-05_15-00-55.jpg ├── metadata.jsonl ├── row_span.jpg ├── table2.jpg ├── table3.jpg ├── table4.jpg ├── table6.jpg ├── table7.jpg └── table_recognition.jpg
数据集加载方式
python from datasets import load_dataset
dataset = load_dataset("SWHL/table_rec_test_dataset")
test_data = dataset[test] print(test_data)
数据集生成的相关信息
- 原始数据: 来源于网络,如侵删。
- 数据集标注: 标注为HTML格式,用于描述表格内容。
搜集汇总
数据集介绍
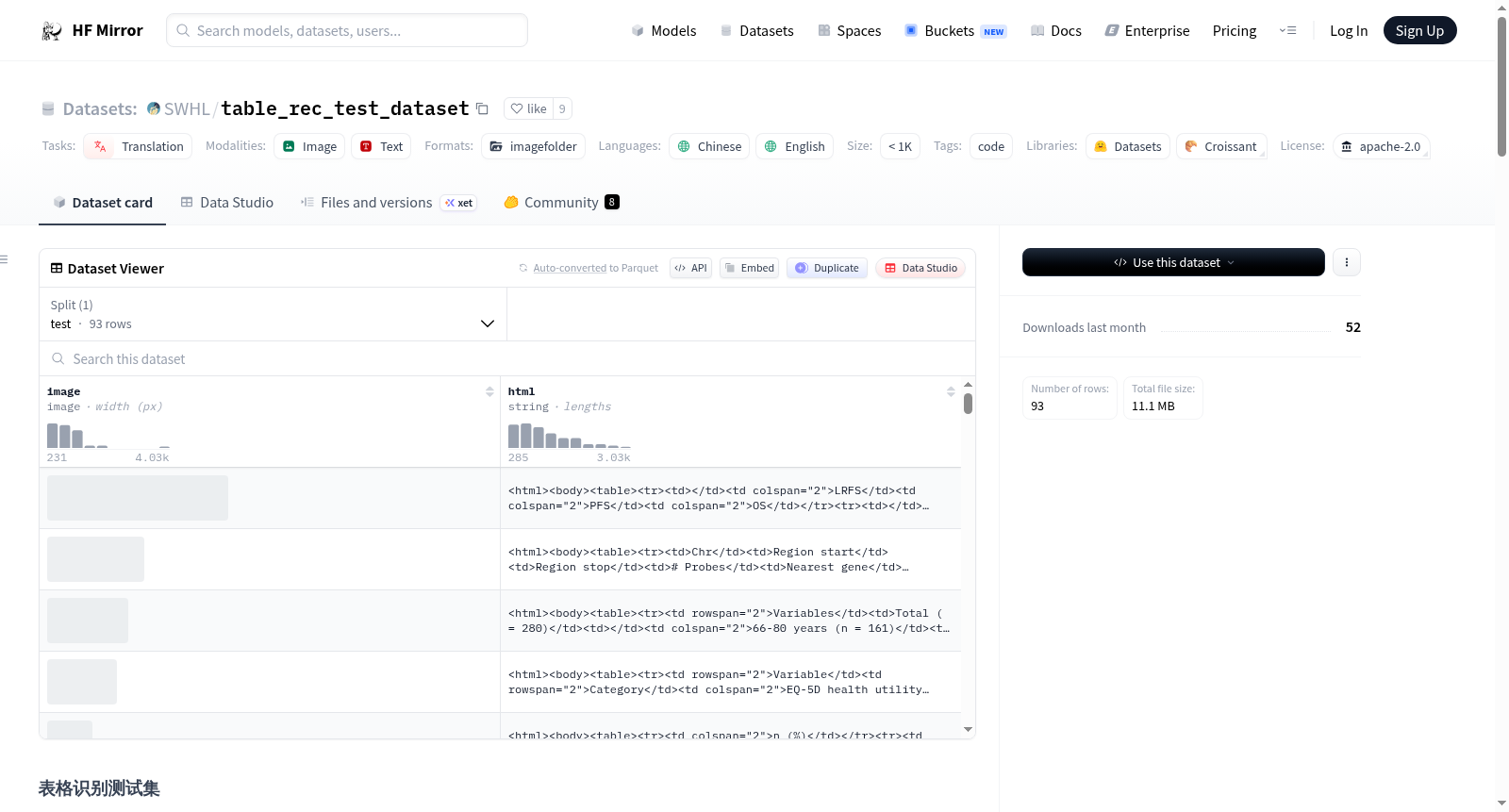
构建方式
在表格识别领域,构建高质量的测试集对于算法性能的客观评估至关重要。该数据集通过整合多源数据构建而成,涵盖了百度生成工具产生的有线与无线表格图像、WTW数据集样本、PubNet验证集图像以及自主零散标注的图像,总计93张表格图片。这些图像广泛覆盖了多种实际应用场景,包括不同的光照条件和图像分辨率,确保了数据集的多样性和代表性,为表格还原算法的稳健性测试提供了坚实基础。
使用方法
该数据集主要用于表格识别算法的性能评估与验证。研究人员或开发者可通过Hugging Face的`datasets`库直接加载数据集,便捷地访问测试集中的图像与对应的HTML标注。结合配套的TableRecognitionMetric评测库,用户可以系统性地量化算法在表格结构还原、内容识别等方面的准确率与效率。数据集提供的HTML标注可直接用于可视化或作为评估基准,支持快速迭代和比较不同算法的优劣,从而推动表格识别技术的进步。
背景与挑战
背景概述
表格识别作为文档智能领域的关键分支,旨在将图像中的表格结构及内容转化为机器可读的格式,如HTML或JSON,以支持信息检索与数据分析。SWHL/table_rec_test_dataset由开发者SWHL于近年构建,汇集了来自百度生成工具、WTW数据集、PubNet验证集及自主标注的93张表格图像,覆盖有线、无线及无边框等多种样式,并囊括了不同光照与分辨率条件。该数据集专为评估表格还原算法的性能而设计,与开源评测库TableRecognitionMetric协同使用,为研究社区提供了标准化的测试基准,推动了表格识别技术在实际场景中的鲁棒性提升与应用拓展。
当前挑战
表格识别领域面临的核心挑战在于准确解析复杂表格结构,如合并单元格、嵌套行列及不规则布局,同时需克服图像质量变异、光照不均及低分辨率带来的干扰。在数据集构建过程中,挑战主要体现在数据收集与标注的复杂性:需整合多源异构图像,确保场景多样性;标注工作依赖人工将视觉表格转换为精确的HTML格式,耗时费力且易出错;此外,数据规模较小,仅93张图像,可能限制模型泛化能力的全面评估,需持续扩充以覆盖更广泛的真实应用情形。
常用场景
经典使用场景
在文档智能与计算机视觉领域,表格识别测试集SWHL/table_rec_test_dataset为算法性能评估提供了标准化基准。该数据集汇集了93张涵盖有线、无线及不同光照与分辨率场景的表格图像,其经典应用在于结合TableRecognitionMetric评测库,系统性地验证表格还原算法的鲁棒性与准确性。通过模拟现实世界中表格结构的多样性,该数据集能够客观衡量算法在复杂布局、边界缺失等挑战下的表现,为研究者提供可靠的横向比较依据。
解决学术问题
该数据集针对表格识别研究中的关键学术问题提供了解决方案。传统表格识别算法常受限于有限的数据多样性,难以泛化至不同样式与质量的图像。SWHL/table_rec_test_dataset通过整合多源数据,解决了算法在跨场景适应性评估上的空白,助力研究者深入探究结构解析、文本检测与单元格关联等核心难题。其意义在于推动了文档理解领域评估范式的标准化,为算法优化与理论创新奠定了实证基础。
实际应用
在实际应用层面,该数据集支撑了办公自动化与数字化管理系统的开发。表格识别技术广泛应用于财务报表解析、合同信息提取与学术文献处理等场景,而本数据集通过提供贴近真实环境的测试样本,能够有效验证算法在业务系统中的稳定性。例如,在金融与法律行业,高精度的表格还原可提升数据录入效率并降低人工错误,该数据集的评估功能为技术落地提供了关键的质量保障。
数据集最近研究
最新研究方向
在文档智能领域,表格识别作为关键任务,正推动着信息提取技术的边界。SWHL/table_rec_test_dataset凭借其涵盖有线、无线及复杂边框的多样化表格图像,为算法鲁棒性评估提供了基准。当前前沿研究聚焦于跨场景泛化能力,尤其在低光照、高噪声及无边框表格的精确还原上,结合深度学习与结构感知模型,以提升实际业务文档的自动化处理效率。该数据集与TableRecognitionMetric评测库的联动,加速了开源社区对端到端表格理解系统的迭代,对金融、政务等领域的结构化数据挖掘具有深远影响。
以上内容由遇见数据集搜集并总结生成


