AniGamePersonaCaps
收藏Hugging Face2024-12-16 更新2024-12-17 收录
下载链接:
https://huggingface.co/datasets/mrzjy/AniGamePersonaCaps
下载链接
链接失效反馈官方服务:
资源简介:
AniGamePersonaCap是一个多模态数据集,收集了633,565个来自3,860个Fandom wiki站点的动漫、漫画和游戏角色。数据集包括图像和文本两种模态。图像模态包含角色的视觉图像,文本模态包含从HTML内容中提取的角色元信息和由视觉语言模型生成的描述。每个样本包含角色的图像、标题、站点名称、URL、描述、图像URL和字幕。字幕部分包括由人类编写和模型生成的外观和性格描述。数据集的收集过程涉及从Fandom wiki站点中提取角色页面,并进行数据清洗和处理。
创建时间:
2024-12-16
原始信息汇总
AniGamePersonaCap 数据集概述
数据集简介
AniGamePersonaCap 是一个多模态数据集,包含了 633,565 个来自 3,860 个 Fandom wiki 站点的动漫、漫画和游戏角色。数据集主要由以下两个模态组成:
-
图像模态
- 角色形象的视觉图像。
-
文本模态
- Fandom Wiki 元数据:从 HTML 内容中提取的角色元信息。
- 描述:
- VLM 生成的描述:由视觉语言模型(如 Qwen-VL-72B-Instruct)生成的角色外貌和性格描述。
- 人工编写的描述(部分):由人类编写的角色外貌和性格描述。
- 匿名化描述(部分):由 GPT-4o-mini 生成的匿名化描述。
数据结构
每个数据样本包含以下字段:
-
元数据:从
<meta>HTML 标签中提取的信息:title:角色名称site_name:Fandom wiki 站点名称url:角色页面的 URLdescription:角色的简要描述(可能被截断)image_url:角色图像的 URL(通常是页面上的第一个图像)
-
描述:从 HTML 解析或由 Qwen-VL 或 GPT-4o-mini 模型生成/改编:
appearance:human:人类编写的描述(仅 18% 的样本有非空值)anonymized:由 GPT-4o-mini 生成的匿名化描述(仅在存在human描述时非空)Qwen2-VL-7B-Instruct:由 Qwen2-VL-7B-Instruct 生成的描述Qwen2-VL-72B-Instruct-GPTQ-Int8:由 Qwen2-VL-72B-Instruct-GPTQ-Int8 生成的描述
personality:human:人类编写的描述(仅 19% 的样本有非空值)anonymized:由 GPT-4o-mini 生成的匿名化描述(仅在存在human描述时非空)Qwen2-VL-7B-Instruct:由 Qwen2-VL-7B-Instruct 生成的推理Qwen2-VL-72B-Instruct-GPTQ-Int8:由 Qwen2-VL-72B-Instruct-GPTQ-Int8 生成的推理
数据收集
数据集从超过 100 万个 Fandom 角色 wiki 页面中收集,这些页面可能与动漫、漫画或游戏相关。收集过程包括:
- 从游戏网站编译游戏实体列表,并使用 DuckDuckGo API 搜索其对应的 Fandom 站点。
- 参考 List of Anime and Manga Wikia 获取动漫和漫画的 Fandom 站点。
- 遍历每个 Fandom 站点的 "Category:Characters" 类别(包括嵌套类别),并检索所有成员页面。
数据处理
数据处理包括以下步骤:
- 去重 wiki 页面 URL 和图像 URL。
- 使用 Qwen2-VL-7B-Instruct 对非动漫/漫画/游戏风格的图像进行分类和过滤。
- 使用 BeautifulSoup 进行 HTML 解析,提取元信息和所需字段。
数据集应用
- 比较 7B 和 72B 模型的性能
- 分析 Qwen VLMs 在 AniGamePersonaCap 上的幻觉问题
- 使用 AniGamePersonaCap 蒸馏 Qwen2-VL-72B-Instruct
- 使用 VLM 描述和角色图像微调文本到图像模型
- 分析视觉线索与性格之间的关系
搜集汇总
数据集介绍
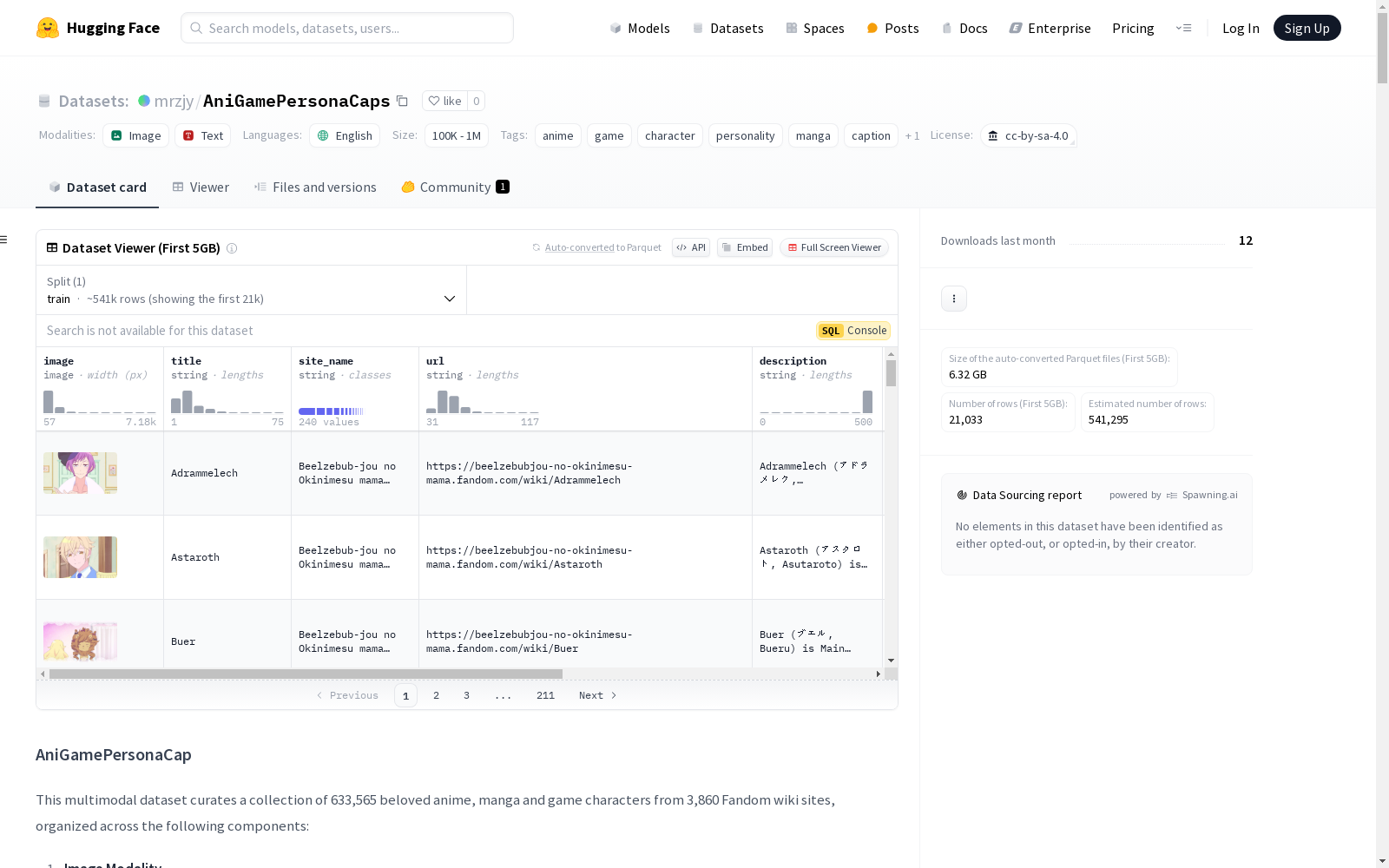
构建方式
AniGamePersonaCaps数据集通过精心策划,从3,860个Fandom wiki站点中收集了633,565个动漫、漫画和游戏角色的多模态数据。数据集的构建过程包括从Fandom wiki页面中提取元数据,如角色名称、站点名称、URL和描述信息,并下载每个角色页面的首张图像。此外,通过Vision-Language Models(如Qwen-VL-72B-Instruct)生成角色外观和性格的描述,部分数据还包含了人工编写的描述和匿名化处理的内容。数据处理阶段包括去重、分类和过滤非动漫/漫画/游戏风格的图像,以及使用BeautifulSoup进行HTML解析,确保数据的准确性和一致性。
特点
AniGamePersonaCaps数据集的显著特点在于其多模态性质,结合了图像和文本两种模态。图像模态包含角色形象的视觉信息,而文本模态则包括从Fandom wiki中提取的元数据和通过VLM生成的描述。数据集中的描述分为人工编写和模型生成两种,部分描述还进行了匿名化处理,以确保数据的多样性和适用性。此外,数据集涵盖了广泛的角色类型和风格,适用于多种研究场景,如角色外观描述生成、性格推理和多模态模型训练。
使用方法
AniGamePersonaCaps数据集可用于多种应用场景,包括但不限于角色外观描述生成、性格推理和多模态模型训练。用户可以通过访问数据集中的图像和文本信息,进行视觉语言模型的微调或性能比较。例如,可以利用数据集中的VLM生成的描述进行文本到图像生成模型的训练,或通过分析角色外观与性格描述之间的关系,探索视觉线索与性格特征的关联。此外,数据集的匿名化描述部分可用于需要排除特定标识符的任务,如专注于视觉和性格推理的研究。
背景与挑战
背景概述
AniGamePersonaCaps数据集由一支专注于动漫、漫画和游戏角色分析的研究团队精心构建,旨在通过多模态数据探索角色外观与性格的关联。该数据集汇集了来自3,860个Fandom wiki站点的633,565个角色,涵盖图像和文本两种模态。图像模态包括角色形象,而文本模态则包括从HTML内容中提取的元信息以及由Vision-Language Models生成的外观和性格描述。该数据集的创建不仅为动漫、游戏和漫画领域的研究提供了丰富的资源,还为多模态数据分析和生成模型提供了宝贵的训练数据。
当前挑战
AniGamePersonaCaps数据集在构建过程中面临多项挑战。首先,数据来源多样且复杂,涉及大量Fandom wiki站点,需进行有效的去重和分类。其次,图像和文本数据的匹配与清洗是关键,尤其是过滤非动漫/漫画/游戏风格的图像。此外,生成模型的应用带来了幻觉问题,可能导致描述与实际图像不符。最后,匿名化处理虽然保护了隐私,但也增加了数据处理的复杂性,尤其是在保持描述准确性的同时去除特定标识。这些挑战使得数据集的质量和可用性成为研究的重点。
常用场景
经典使用场景
AniGamePersonaCaps数据集的经典使用场景主要集中在多模态学习和人物角色描述的生成任务中。通过结合图像和文本数据,研究者可以训练模型以生成详细的动漫、漫画和游戏角色描述,包括外观和性格特征。这种多模态数据集特别适用于视觉语言模型(VLM)的训练和评估,尤其是在生成与图像相关的文本描述时,能够提供丰富的视觉和文本信息。
解决学术问题
该数据集解决了多模态学习中的关键问题,特别是在视觉和文本信息的融合方面。通过提供详细的图像描述和人物性格分析,AniGamePersonaCaps数据集为研究者提供了一个强大的工具,用于探索如何从图像中提取信息并生成相应的文本描述。这不仅推动了视觉语言模型的研究,还为多模态数据集的标准化和评估提供了新的视角。
衍生相关工作
基于AniGamePersonaCaps数据集,研究者已经开展了一系列相关工作,包括视觉语言模型的性能比较、幻觉问题的分析以及模型的蒸馏技术。此外,该数据集还被用于微调文本到图像生成模型,以提高生成图像的质量和准确性。这些衍生工作不仅扩展了数据集的应用范围,还为多模态学习领域提供了新的研究方向。
以上内容由遇见数据集搜集并总结生成


