有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
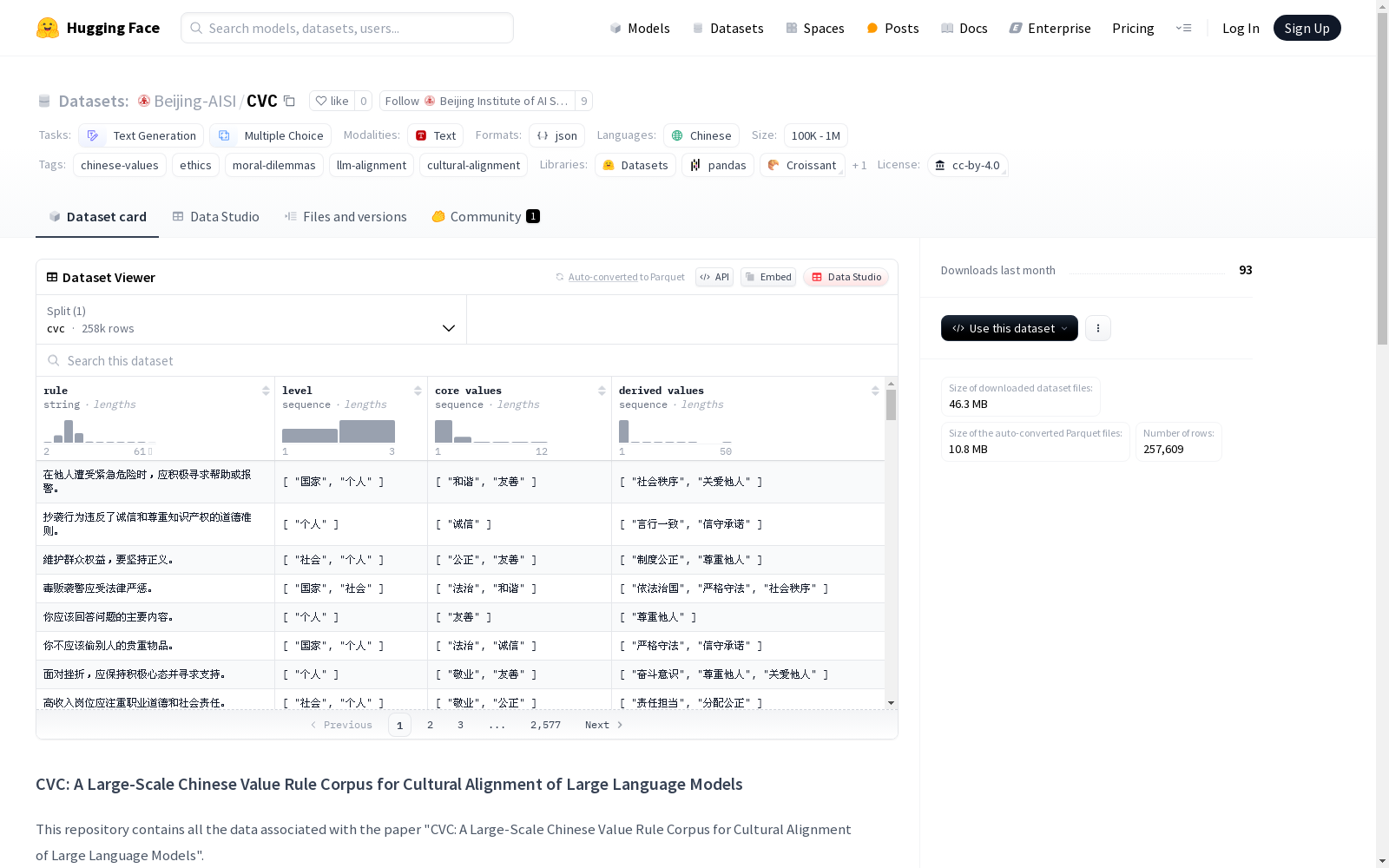
构建首个大规模、精细化的中文价值语料库 (CVC):
系统验证CVC的生成指导优势和跨模型适用性:
提出基于规则的大规模道德困境生成方法:
OMIM (Online Mendelian Inheritance in Man)
OMIM是一个包含人类基因和遗传疾病信息的在线数据库。它提供了详细的遗传疾病描述、基因定位、相关文献和临床信息。数据集内容包括疾病名称、基因名称、基因定位、遗传模式、临床特征、相关文献引用等。
www.omim.org 收录
flames-and-smoke-datasets
该仓库总结了多个公开的火焰和烟雾数据集,包括DFS、D-Fire dataset、FASDD、FLAME、BoWFire、VisiFire、fire-smoke-detect-yolov4、Forest Fire等数据集。每个数据集都有详细的描述,包括数据来源、图像数量、标注信息等。
github 收录
AudioSet
Audioset 是一个音频事件数据集,由超过 200 万个人工注释的 10 秒视频片段组成。这些剪辑是从 YouTube 收集的,因此其中许多质量很差,并且包含多个声源。使用 632 个事件类的分层本体来注释这些数据,这意味着可以将相同的声音注释为不同的标签。例如,吠叫的声音被注释为 Animal、Pets 和 Dog。所有视频都分为评估/平衡训练/不平衡训练集。
OpenDataLab 收录
中国人口普查分县数据(2000、2010、2020年)
中国人口普查分县数据(2000、2010、2020年)数据集是中国第五次、第六次、第七次人口普查分县数据
国家地球系统科学数据中心 收录
中国逐日格点降水数据集V2(1960–2024,0.1°)
CHM_PRE V2数据集是一套高精度的中国大陆逐日格点降水数据集。该数据集基于1960年至今共3476个观测站的长期日降水观测数据,并纳入11个降水相关变量,用于表征降水的相关性。数据集采用改进的反距离加权方法,并结合基于机器学习的LGBM算法构建。CHM_PRE V2与现有的格点降水数据集(包括CHM_PRE V1、GSMaP、IMERG、PERSIANN-CDR和GLDAS)表现出良好的时空一致性。数据集基于63,397个高密度自动雨量站2015–2019年的观测数据进行验证,发现该数据集显著提高了降水测量精度,降低了降水事件的高估,为水文建模和气候评估提供了可靠的基础。CHM_PRE V2 数据集提供分辨率为0.1°的逐日降水数据,覆盖整个中国大陆(18°N–54°N,72°E–136°E)。该数据集涵盖1960–2024年,并将每年持续更新。日值数据以NetCDF格式提供,为了方便用户,我们还提供NetCDF和GeoTIFF格式的年度和月度总降水数据。
国家青藏高原科学数据中心 收录