jonathanli/eurlex
收藏Hugging Face2022-10-24 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/jonathanli/eurlex
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- found
language_creators:
- found
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-label-classification
paperswithcode_id: eurlex57k
pretty_name: the EUR-Lex dataset
tags:
- legal-topic-classification
---
# Dataset Card for the EUR-Lex dataset
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** http://nlp.cs.aueb.gr/software_and_datasets/EURLEX57K/
- **Repository:** http://nlp.cs.aueb.gr/software_and_datasets/EURLEX57K/
- **Paper:** https://www.aclweb.org/anthology/P19-1636/
- **Leaderboard:** N/A
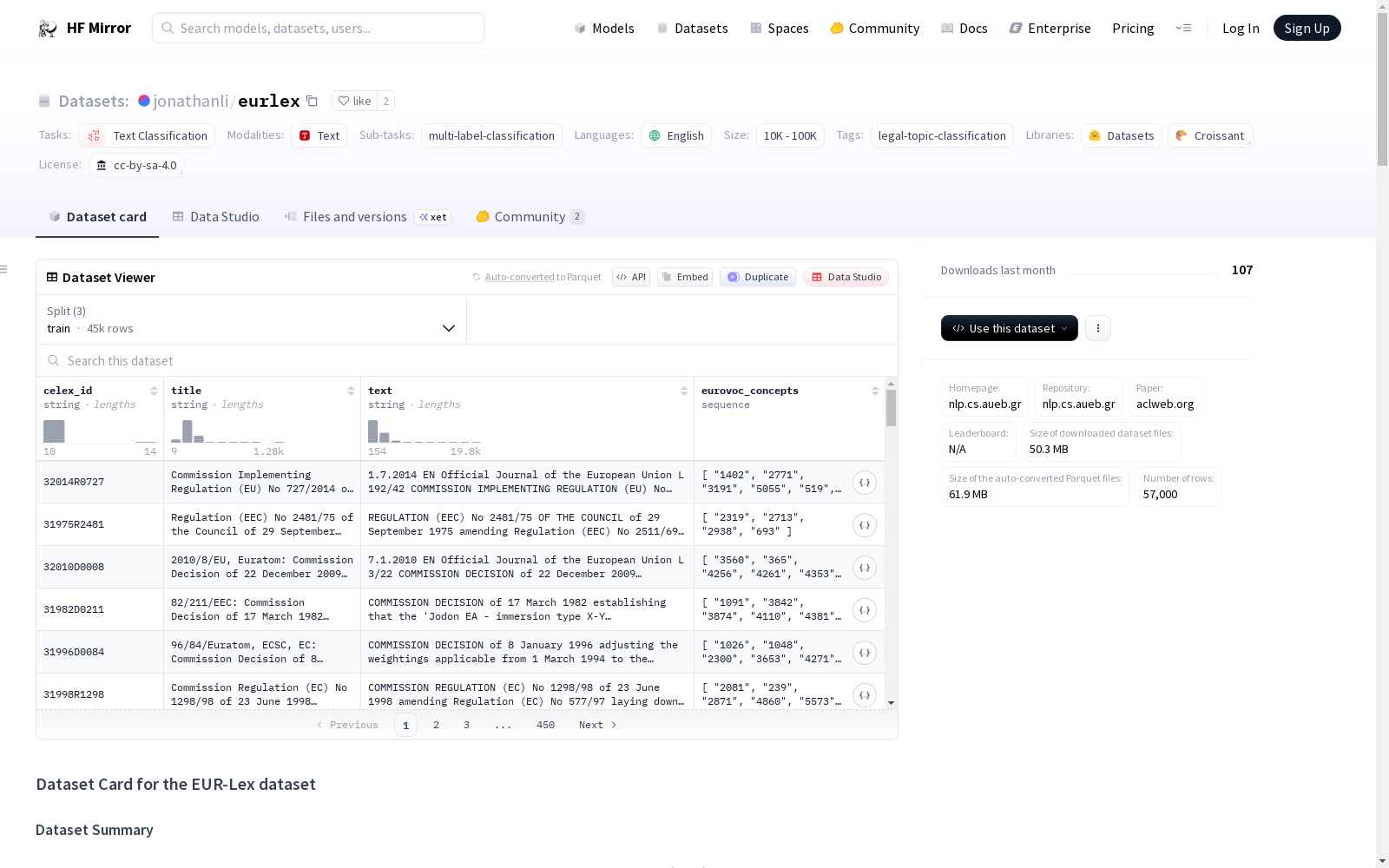
### Dataset Summary
EURLEX57K can be viewed as an improved version of the dataset released by Mencia and Furnkranzand (2007), which has been widely used in Large-scale Multi-label Text Classification (LMTC) research, but is less than half the size of EURLEX57K (19.6k documents, 4k EUROVOC labels) and more than ten years old.
EURLEX57K contains 57k legislative documents in English from EUR-Lex (https://eur-lex.europa.eu) with an average length of 727 words. Each document contains four major zones:
- the header, which includes the title and name of the legal body enforcing the legal act;
- the recitals, which are legal background references; and
- the main body, usually organized in articles.
**Labeling / Annotation**
All the documents of the dataset have been annotated by the Publications Office of EU (https://publications.europa.eu/en) with multiple concepts from EUROVOC (http://eurovoc.europa.eu/).
While EUROVOC includes approx. 7k concepts (labels), only 4,271 (59.31%) are present in EURLEX57K, from which only 2,049 (47.97%) have been assigned to more than 10 documents. The 4,271 labels are also divided into frequent (746 labels), few-shot (3,362), and zero- shot (163), depending on whether they were assigned to more than 50, fewer than 50 but at least one, or no training documents, respectively.
### Supported Tasks and Leaderboards
The dataset supports:
**Multi-label Text Classification:** Given the text of a document, a model predicts the relevant EUROVOC concepts.
**Few-shot and Zero-shot learning:** As already noted, the labels can be divided into three groups: frequent (746 labels), few-shot (3,362), and zero- shot (163), depending on whether they were assigned to more than 50, fewer than 50 but at least one, or no training documents, respectively.
### Languages
All documents are written in English.
## Dataset Structure
### Data Instances
```json
{
"celex_id": "31979D0509",
"title": "79/509/EEC: Council Decision of 24 May 1979 on financial aid from the Community for the eradication of African swine fever in Spain",
"text": "COUNCIL DECISION of 24 May 1979 on financial aid from the Community for the eradication of African swine fever in Spain (79/509/EEC)\nTHE COUNCIL OF THE EUROPEAN COMMUNITIES\nHaving regard to the Treaty establishing the European Economic Community, and in particular Article 43 thereof,\nHaving regard to the proposal from the Commission (1),\nHaving regard to the opinion of the European Parliament (2),\nWhereas the Community should take all appropriate measures to protect itself against the appearance of African swine fever on its territory;\nWhereas to this end the Community has undertaken, and continues to undertake, action designed to contain outbreaks of this type of disease far from its frontiers by helping countries affected to reinforce their preventive measures ; whereas for this purpose Community subsidies have already been granted to Spain;\nWhereas these measures have unquestionably made an effective contribution to the protection of Community livestock, especially through the creation and maintenance of a buffer zone north of the river Ebro;\nWhereas, however, in the opinion of the Spanish authorities themselves, the measures so far implemented must be reinforced if the fundamental objective of eradicating the disease from the entire country is to be achieved;\nWhereas the Spanish authorities have asked the Community to contribute to the expenses necessary for the efficient implementation of a total eradication programme;\nWhereas a favourable response should be given to this request by granting aid to Spain, having regard to the undertaking given by that country to protect the Community against African swine fever and to eliminate completely this disease by the end of a five-year eradication plan;\nWhereas this eradication plan must include certain measures which guarantee the effectiveness of the action taken, and it must be possible to adapt these measures to developments in the situation by means of a procedure establishing close cooperation between the Member States and the Commission;\nWhereas it is necessary to keep the Member States regularly informed as to the progress of the action undertaken,",
"eurovoc_concepts": ["192", "2356", "2560", "862", "863"]
}
```
### Data Fields
The following data fields are provided for documents (`train`, `dev`, `test`):
`celex_id`: (**str**) The official ID of the document. The CELEX number is the unique identifier for all publications in both Eur-Lex and CELLAR.\
`title`: (**str**) The title of the document.\
`text`: (**str**) The full content of each document, which is represented by its `header`, `recitals` and `main_body`.\
`eurovoc_concepts`: (**List[str]**) The relevant EUROVOC concepts (labels).
If you want to use the descriptors of EUROVOC concepts, similar to Chalkidis et al. (2020), please load: https://archive.org/download/EURLEX57K/eurovoc_concepts.jsonl
```python
import json
with open('./eurovoc_concepts.jsonl') as jsonl_file:
eurovoc_concepts = {json.loads(concept) for concept in jsonl_file.readlines()}
```
### Data Splits
| Split | No of Documents | Avg. words | Avg. labels |
| ------------------- | ------------------------------------ | --- | --- |
| Train | 45,000 | 729 | 5 |
|Development | 6,000 | 714 | 5 |
|Test | 6,000 | 725 | 5 |
## Dataset Creation
### Curation Rationale
The dataset was curated by Chalkidis et al. (2019).\
The documents have been annotated by the Publications Office of EU (https://publications.europa.eu/en).
### Source Data
#### Initial Data Collection and Normalization
The original data are available at EUR-Lex portal (https://eur-lex.europa.eu) in an unprocessed format.
The documents were downloaded from EUR-Lex portal in HTML format.
The relevant metadata and EUROVOC concepts were downloaded from the SPARQL endpoint of the Publications Office of EU (http://publications.europa.eu/webapi/rdf/sparql).
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
* The original documents are available at EUR-Lex portal (https://eur-lex.europa.eu) in an unprocessed HTML format. The HTML code was striped and the documents split into sections.
* The documents have been annotated by the Publications Office of EU (https://publications.europa.eu/en).
#### Who are the annotators?
Publications Office of EU (https://publications.europa.eu/en)
### Personal and Sensitive Information
The dataset does not include personal or sensitive information.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Chalkidis et al. (2019)
### Licensing Information
© European Union, 1998-2021
The Commission’s document reuse policy is based on Decision 2011/833/EU. Unless otherwise specified, you can re-use the legal documents published in EUR-Lex for commercial or non-commercial purposes.
The copyright for the editorial content of this website, the summaries of EU legislation and the consolidated texts, which is owned by the EU, is licensed under the Creative Commons Attribution 4.0 International licence. This means that you can re-use the content provided you acknowledge the source and indicate any changes you have made.
Source: https://eur-lex.europa.eu/content/legal-notice/legal-notice.html \
Read more: https://eur-lex.europa.eu/content/help/faq/reuse-contents-eurlex.html
### Citation Information
*Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis and Ion Androutsopoulos.*
*Large-Scale Multi-Label Text Classification on EU Legislation.*
*Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019). Florence, Italy. 2019*
```
@inproceedings{chalkidis-etal-2019-large,
title = "Large-Scale Multi-Label Text Classification on {EU} Legislation",
author = "Chalkidis, Ilias and Fergadiotis, Manos and Malakasiotis, Prodromos and Androutsopoulos, Ion",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1636",
doi = "10.18653/v1/P19-1636",
pages = "6314--6322"
}
```
### Contributions
Thanks to [@iliaschalkidis](https://github.com/iliaschalkidis) for adding this dataset.
annotations_creators:
- 外部获取
language_creators:
- 外部获取
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- 单语言
size_categories:
- 10000 < 样本数 < 100000
source_datasets:
- 原始数据集
task_categories:
- 文本分类(text-classification)
task_ids:
- 多标签分类(multi-label-classification)
paperswithcode_id: eurlex57k
pretty_name: EUR-Lex数据集
tags:
- 法律主题分类(legal-topic-classification)
# EUR-Lex数据集卡片
## 目录
- [数据集概述](#数据集概述)
- [数据集摘要](#数据集摘要)
- [支持任务与排行榜](#支持任务与排行榜)
- [语言](#语言)
- [数据集结构](#数据集结构)
- [数据实例](#数据实例)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集构建](#数据集构建)
- [构建初衷](#构建初衷)
- [源数据](#源数据)
- [注释](#注释)
- [个人与敏感信息](#个人与敏感信息)
- [数据集使用注意事项](#数据集使用注意事项)
- [数据集的社会影响](#数据集的社会影响)
- [偏差讨论](#偏差讨论)
- [其他已知局限](#其他已知局限)
- [附加信息](#附加信息)
- [数据集维护者](#数据集维护者)
- [许可证信息](#许可证信息)
- [引用信息](#引用信息)
- [贡献者](#贡献者)
## 数据集概述
- **主页**:http://nlp.cs.aueb.gr/software_and_datasets/EURLEX57K/
- **代码仓库**:http://nlp.cs.aueb.gr/software_and_datasets/EURLEX57K/
- **论文**:https://www.aclweb.org/anthology/P19-1636/
- **排行榜**:无
### 数据集摘要
EURLEX57K可被视为Mencia与Furnkranzand(2007)发布的数据集的改进版本,该数据集曾广泛应用于大规模多标签文本分类(Large-scale Multi-label Text Classification, LMTC)研究,但原始数据集仅包含19.6k份文档、4k个EUROVOC标签,且已发布超过十年,规模仅为EURLEX57K的一半不到。
EURLEX57K包含来自EUR-Lex(https://eur-lex.europa.eu)的57k份英语立法文档,平均长度为727词。每份文档包含四个主要部分:
- 首部(header):包含法律法案的标题与执行该法案的法律机构名称;
- 陈述部分(recitals):即法律背景引用;
- 主体部分(main_body):通常以条款形式组织。
**标注/注释**
本数据集所有文档均由欧盟出版物办公室(Publications Office of EU, https://publications.europa.eu/en)基于EUROVOC(http://eurovoc.europa.eu/)的多个概念进行标注。
EUROVOC共包含约7k个概念(标签),其中仅4271个(占比59.31%)出现在EURLEX57K中,而这4271个标签里又仅有2049个(占比47.97%)被分配给了超过10份文档。根据标签被分配至训练文档的数量,4271个标签可被分为三类:高频标签(746个,被分配至超过50份训练文档)、少样本(Few-shot)标签(3362个,被分配至1至49份训练文档)以及零样本(Zero-shot)标签(163个,未被分配至任何训练文档)。
### 支持任务与排行榜
本数据集支持以下任务:
**多标签文本分类(Multi-label Text Classification)**:给定文档文本,模型预测其对应的EUROVOC相关概念。
**少样本(Few-shot)与零样本(Zero-shot)学习**:如前所述,根据标签被分配至训练文档的数量,标签可被分为三类:高频标签(746个)、少样本标签(3362个)以及零样本标签(163个),分别对应被分配至超过50份、1至49份、0份训练文档的标签。
### 语言
所有文档均为英语。
## 数据集结构
### 数据实例
json
{
"celex_id": "31979D0509",
"title": "79/509/EEC: Council Decision of 24 May 1979 on financial aid from the Community for the eradication of African swine fever in Spain",
"text": "COUNCIL DECISION of 24 May 1979 on financial aid from the Community for the eradication of African swine fever in Spain (79/509/EEC)
THE COUNCIL OF THE EUROPEAN COMMUNITIES
Having regard to the Treaty establishing the European Economic Community, and in particular Article 43 thereof,
Having regard to the proposal from the Commission (1),
Having regard to the opinion of the European Parliament (2),
Whereas the Community should take all appropriate measures to protect itself against the appearance of African swine fever on its territory;
Whereas to this end the Community has undertaken, and continues to undertake, action designed to contain outbreaks of this type of disease far from its frontiers by helping countries affected to reinforce their preventive measures ; whereas for this purpose Community subsidies have already been granted to Spain;
Whereas these measures have unquestionably made an effective contribution to the protection of Community livestock, especially through the creation and maintenance of a buffer zone north of the river Ebro;
Whereas, however, in the opinion of the Spanish authorities themselves, the measures so far implemented must be reinforced if the fundamental objective of eradicating the disease from the entire country is to be achieved;
Whereas the Spanish authorities have asked the Community to contribute to the expenses necessary for the efficient implementation of a total eradication programme;
Whereas a favourable response should be given to this request by granting aid to Spain, having regard to the undertaking given by that country to protect the Community against African swine fever and to eliminate completely this disease by the end of a five-year eradication plan;
Whereas this eradication plan must include certain measures which guarantee the effectiveness of the action taken, and it must be possible to adapt these measures to developments in the situation by means of a procedure establishing close cooperation between the Member States and the Commission;
Whereas it is necessary to keep the Member States regularly informed as to the progress of the action undertaken,",
"eurovoc_concepts": ["192", "2356", "2560", "862", "863"]
}
### 数据字段
针对训练集(train)、开发集(dev)与测试集(test)中的文档,提供以下数据字段:
`celex_id`:(字符串类型)文档的官方唯一标识符。CELEX编号是EUR-Lex与CELLAR平台所有出版物的唯一标识。
`title`:(字符串类型)文档标题。
`text`:(字符串类型)文档的完整内容,由首部(header)、陈述部分(recitals)与主体部分(main_body)组成。
`eurovoc_concepts`:(字符串列表类型)文档对应的相关EUROVOC概念(标签)。
如果需要获取EUROVOC概念的描述词(参考Chalkidis等人2020年的研究),请加载:https://archive.org/download/EURLEX57K/eurovoc_concepts.jsonl
python
import json
with open('./eurovoc_concepts.jsonl') as jsonl_file:
eurovoc_concepts = {json.loads(concept) for concept in jsonl_file.readlines()}
### 数据划分
| 划分 | 文档数量 | 平均词数 | 平均标签数 |
| ------------------- | ------------------------------------ | --- | --- |
| 训练集 | 45,000 | 729 | 5 |
| 开发集 | 6,000 | 714 | 5 |
| 测试集 | 6,000 | 725 | 5 |
## 数据集构建
### 构建初衷
本数据集由Chalkidis等人(2019)构建。所有文档均由欧盟出版物办公室(https://publications.europa.eu/en)完成标注。
### 源数据
#### 初始数据收集与标准化
原始数据可在EUR-Lex门户(https://eur-lex.europa.eu)获取,格式为未处理的HTML。文档从EUR-Lex门户以HTML格式下载,相关元数据与EUROVOC概念则从欧盟出版物办公室的SPARQL端点(http://publications.europa.eu/webapi/rdf/sparql)下载。
#### 源语言生产者是谁?
[More Information Needed]
### 注释
#### 标注流程
* 原始文档以未处理的HTML格式存储于EUR-Lex门户(https://eur-lex.europa.eu),我们移除了HTML代码并将文档拆分为多个章节。
* 所有文档均由欧盟出版物办公室(https://publications.europa.eu/en)完成标注。
#### 标注者是谁?
欧盟出版物办公室(https://publications.europa.eu/en)
### 个人与敏感信息
本数据集不包含任何个人或敏感信息。
## 数据集使用注意事项
### 数据集的社会影响
[More Information Needed]
### 偏差讨论
[More Information Needed]
### 其他已知局限
[More Information Needed]
## 附加信息
### 数据集维护者
Chalkidis等人(2019)
### 许可证信息
© 欧盟,1998-2021
欧盟委员会的文档复用政策基于第2011/833/EU号决议。除非另有说明,您可将EUR-Lex中发布的法律文档用于商业或非商业用途。
本网站的编辑内容、欧盟立法摘要与整合文本的版权归欧盟所有,采用知识共享署名4.0国际许可协议(CC BY 4.0)进行授权。这意味着您可复用这些内容,但需注明来源并说明所做的修改。
来源:https://eur-lex.europa.eu/content/legal-notice/legal-notice.html
更多信息:https://eur-lex.europa.eu/content/help/faq/reuse-contents-eurlex.html
### 引用信息
*Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis and Ion Androutsopoulos.*
*大规模多标签文本分类:欧盟立法场景(Large-Scale Multi-Label Text Classification on EU Legislation)*
*第57届计算语言学协会(Association for Computational Linguistics, ACL)年会论文集,意大利佛罗伦萨,2019年*
@inproceedings{chalkidis-etal-2019-large,
title = "Large-Scale Multi-Label Text Classification on {EU} Legislation",
author = "Chalkidis, Ilias and Fergadiotis, Manos and Malakasiotis, Prodromos and Androutsopoulos, Ion",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1636",
doi = "10.18653/v1/P19-1636",
pages = "6314--6322"
}
### 贡献者
感谢[@iliaschalkidis](https://github.com/iliaschalkidis) 添加本数据集。
提供机构:
jonathanli
原始信息汇总
数据集概述
数据集名称
- 名称: EUR-Lex dataset
- 别名: EURLEX57K
数据集基本信息
- 语言: 英语
- 许可证: CC-BY-SA-4.0
- 多语言性: 单语
- 大小: 10K<n<100K
- 来源: 原始数据
- 任务类别: 文本分类
- 任务ID: 多标签分类
- 标签: 法律主题分类
数据集内容
- 文档数量: 57,000
- 平均文档长度: 727字
- 标签数量: 4,271(其中2,049标签被分配给超过10个文档)
- 标签分类: 频繁(746标签),少样本(3,362标签),零样本(163标签)
数据集结构
- 数据实例: 包含celex_id, title, text, eurovoc_concepts等字段
- 数据分割: 训练集45,000文档,开发集6,000文档,测试集6,000文档
数据集创建
- 创建者: Chalkidis et al. (2019)
- 注释者: 欧盟出版办公室
- 数据来源: EUR-Lex门户网站
使用许可
- 版权信息: 欧洲联盟,1998-2021
- 重用政策: 基于Decision 2011/833/EU,可用于商业或非商业目的
引用信息
@inproceedings{chalkidis-etal-2019-large, title = "Large-Scale Multi-Label Text Classification on {EU} Legislation", author = "Chalkidis, Ilias and Fergadiotis, Manos and Malakasiotis, Prodromos and Androutsopoulos, Ion", booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics", year = "2019", address = "Florence, Italy", publisher = "Association for Computational Linguistics", url = "https://www.aclweb.org/anthology/P19-1636", doi = "10.18653/v1/P19-1636", pages = "6314--6322" }
搜集汇总
数据集介绍
构建方式
在法律文本挖掘领域,数据集的构建需兼顾权威性与规模性。EUR-Lex数据集源自欧盟法律门户,其构建过程严谨而系统:原始文档以HTML格式从EUR-Lex平台获取,经过代码剥离与章节划分处理,形成结构化文本。标注工作由欧盟出版办公室专业完成,依据EUROVOC词表为每份文档赋予多标签概念,确保了标注的官方性与一致性。数据集的划分遵循标准机器学习实践,包含训练集、开发集与测试集,为模型评估提供了可靠基础。
使用方法
该数据集适用于多标签文本分类任务的模型训练与评估。研究者可通过加载标准数据分割,直接获取文档标题、全文内容及对应的EUROVOC概念标签。对于需要概念描述的研究,可额外加载配套的元数据文件以获取标签语义信息。典型应用场景包括构建法律文档自动分类系统、探索少样本与零样本学习机制,以及评估模型对长文本与复杂标签体系的处理能力。使用时应遵循欧盟官方许可协议,并注意标签分布的高度不均衡特性。
背景与挑战
背景概述
EUR-Lex数据集由Chalkidis等人于2019年构建,旨在为大规模多标签文本分类研究提供高质量的法律文本资源。该数据集源自欧盟官方法律门户EUR-Lex,收录了约5.7万份英文立法文件,涵盖标题、引述和正文等结构化内容,并由欧盟出版局使用EUROVOC词表进行专业标注。作为对早期Mencia和Furnkranz所发布数据集的扩展与优化,EUR-Lex不仅规模显著扩大,还通过精细的标签体系支持少样本与零样本学习场景,推动了法律自然语言处理领域在复杂分类任务上的方法创新与应用探索。
当前挑战
EUR-Lex数据集所应对的核心挑战在于大规模多标签法律文本分类,其难点源于法律文档的冗长性、专业术语密集性以及标签体系的高度不平衡性——EUROVOC标签中仅少数频繁出现,多数属于少样本或零样本类别,对模型泛化能力构成严峻考验。在构建过程中,挑战主要集中于原始HTML格式法律文档的结构化解析与清洗,以及从欧盟SPARQL端点高效提取元数据与标注信息,需确保文本分段准确性与标注一致性,同时处理标签稀疏性带来的数据表征难题。
常用场景
经典使用场景
在法律文本分析领域,EUR-Lex数据集作为大规模多标签文本分类的基准资源,其经典应用场景在于评估和优化机器学习模型对复杂法律文档的自动归类能力。该数据集包含数万份欧盟立法文件,每份文档均标注了多个EUROVOC主题概念,为研究者提供了丰富的结构化法律语料。通过利用这些标注信息,模型能够学习法律文本的深层语义特征,实现对法律条文主题的精准识别与分类,从而推动法律智能处理技术的发展。
解决学术问题
EUR-Lex数据集有效解决了大规模多标签文本分类中的若干核心学术问题,特别是在处理高维度标签空间和长文本序列方面提供了实证基础。该数据集通过引入数千个EUROVOC概念标签,挑战了传统分类模型在标签稀疏性和类别不平衡情境下的性能极限。其标注体系涵盖了频繁标签、少样本标签和零样本标签的分布,为研究少样本学习与零样本学习机制提供了天然实验场,深化了学术界对法律领域迁移学习和领域自适应问题的理解。
实际应用
在法律科技与公共治理实践中,EUR-Lex数据集支撑了多项实际应用系统的开发。基于该数据集训练的模型可部署于欧盟法律信息平台,实现立法文档的智能检索与主题导航,提升法律工作者查阅效率。同时,该数据集为法律合规分析工具提供了核心标注数据,帮助机构自动监测法规变化对业务的影响。在司法辅助领域,此类技术还能协助法官和律师快速定位相关判例与法律依据,增强法律服务的智能化水平。
数据集最近研究
最新研究方向
在法律文本分类领域,EUR-Lex数据集作为大规模多标签分类的基准,其前沿研究聚焦于解决标签分布极度不均衡带来的挑战。鉴于数据集中存在大量少样本和零样本标签类别,学者们正探索利用元学习、提示学习等先进技术,以提升模型对罕见法律概念的泛化能力。同时,结合法律文本特有的结构化信息,如标题、序言和正文等区域特征,研究者致力于开发层次化或图神经网络模型,以更精准地捕捉法律条文间的语义关联。这些进展不仅推动了法律智能分析工具的实用化,也为跨语言、跨法系的法规比较研究提供了重要支撑。
以上内容由遇见数据集搜集并总结生成


