gsd-smith-Czech
收藏Hugging Face2026-05-11 更新2026-05-12 收录
下载链接:
https://huggingface.co/datasets/ljvmiranda921/gsd-smith-Czech
下载链接
链接失效反馈官方服务:
资源简介:
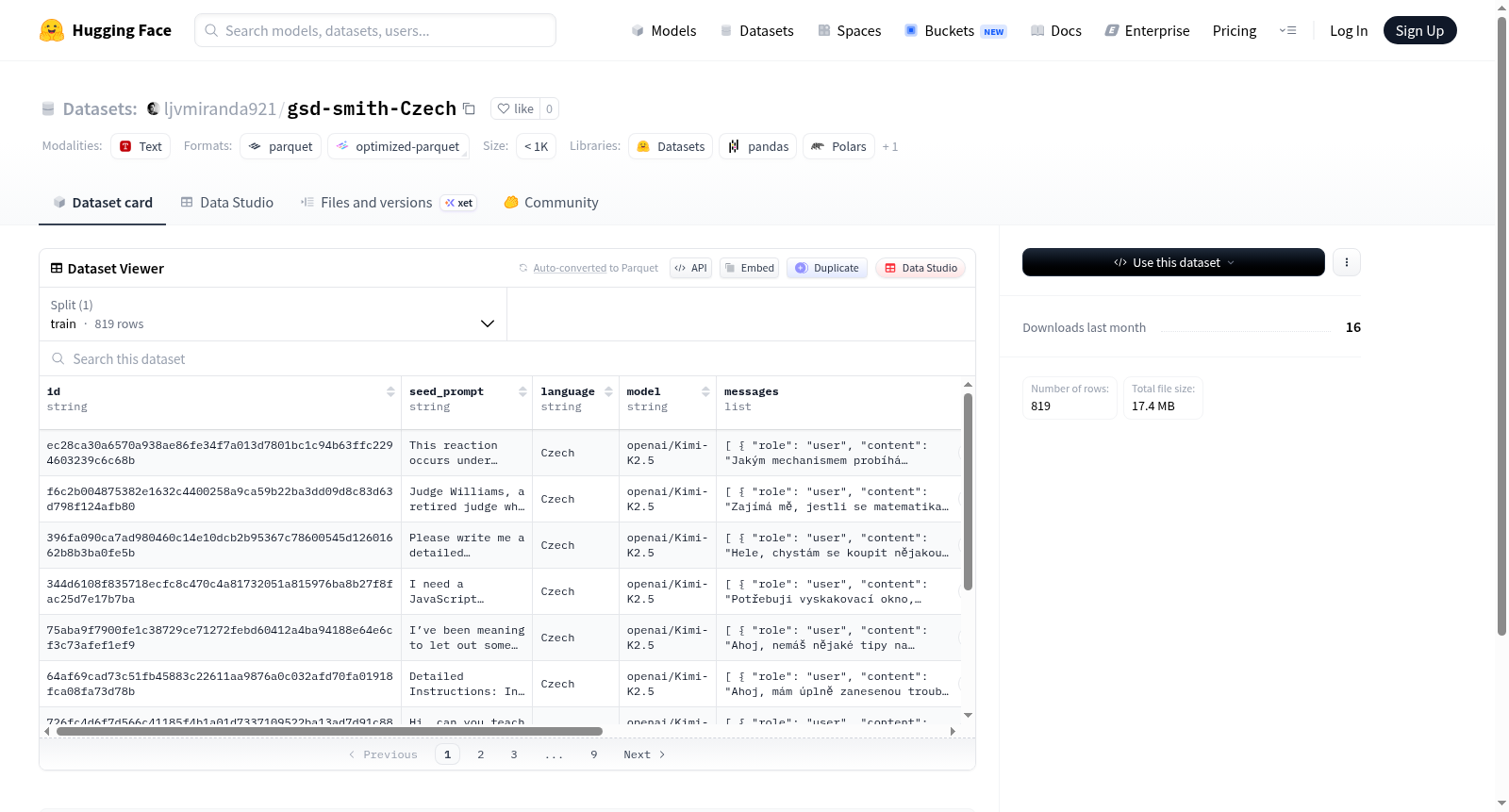
该数据集是一个专门用于训练或评估对话式人工智能模型的多轮对话数据集。每条数据记录通过唯一ID标识,并围绕一个初始的种子提示(seed_prompt)展开对话。对话内容以消息列表(messages)的形式组织,每条消息包含发言者角色(如用户或助手)及其内容(content)。数据集还记录了生成对话所使用的模型信息、对话的语言,以及一个JSON格式的代理轨迹(agent_trace),这可能用于追踪对话生成过程中的内部状态或决策步骤。此外,source_id字段可能指向数据的原始出处。数据集仅包含训练集(train split),共计543个对话样本。
This dataset is a multi-turn dialogue dataset specifically designed for training or evaluating conversational AI models. Each data record is identified by a unique ID and revolves around an initial seed_prompt to initiate the conversation. The dialogue content is organized as a list of messages, where each message includes the speakers role (such as user or assistant) and its content. The dataset also records the model used to generate the dialogue, the language of the conversation, and a JSON-formatted agent_trace, which may be used to track internal states or decision steps during dialogue generation. Additionally, the source_id field may point to the original source of the data. The dataset contains only the training set (train split), with a total of 543 dialogue samples.
创建时间:
2026-05-09
原始信息汇总
根据提供的README文件内容,以下是该数据集详情页的总结:
数据集概述
- 数据集名称:gsd-smith-Czech
- 发布平台:Hugging Face
- 数据集地址:https://huggingface.co/datasets/ljvmiranda921/gsd-smith-Czech
数据集特征
该数据集包含以下特征字段:
- id:字符串类型,用于唯一标识每条数据。
- seed_prompt:字符串类型,表示初始提示词。
- language:字符串类型,表示数据使用的语言(此处为捷克语)。
- model:字符串类型,表示生成数据所用的模型。
- messages:列表类型,每个元素包含两个子字段:
- role:字符串类型,表示消息角色(如用户、助手等)。
- content:字符串类型,表示消息内容。
- agent_trace:列表类型,以JSON格式存储智能体追踪信息。
- source_id:字符串类型,表示来源标识。
数据划分
- 训练集(train):包含543个样本,大小为11,747,363字节。
- 下载大小:11,061,851字节。
- 数据集总大小:11,747,363字节。
配置信息
- 配置名称:default
- 数据文件路径:
data/train-*(训练集文件)。
搜集汇总
数据集介绍
构建方式
该数据集以指令微调为核心构建理念,精心收集了543条捷克语训练样本。每条样本均包含唯一标识符、种子提示词、语言标签、模型来源、多轮对话结构、智能体追踪轨迹及原始数据源等信息,其中对话部分严格按照角色与内容字段进行组织,智能体轨迹则以JSON格式灵活记录交互过程中的复杂动态。数据集的构建旨在为低资源语言捷克语提供高质量的指令微调基础,填补了该语言在智能体交互数据领域的空白。
特点
数据集专注于捷克语场景,具备鲜明的多语言适配特性。其独特之处在于每条样本不仅包含标准的对话记录,还完整保留了智能体执行任务时的完整轨迹数据,为研究模型在捷克语环境中的推理与行动协同提供了珍贵素材。此外,数据集的字段设计兼顾了结构化与非结构化信息的存储,支持从简单指令到复杂多轮交互的多样化任务需求。
使用方法
用户可通过HuggingFace Datasets库直接加载该数据集,默认配置下仅包含训练集分割。建议研究者将其与多语言预训练模型结合使用,通过微调增强模型在捷克语指令遵循与工具调用场景中的表现。数据集中的智能体轨迹字段可被用于细粒度分析模型在特定任务中的决策路径,或用于构造更具挑战性的多轮对话评估基准。
背景与挑战
背景概述
gsd-smith-Czech数据集于近年来构建,旨在应对大语言模型在低资源语言场景下的指令遵循能力评估需求。由研究团队聚焦捷克语这一非英语语种,通过精心设计的种子提示(seed_prompt)生成多轮对话与智能体轨迹(agent_trace),核心研究问题在于探索模型在捷克语环境中的语义理解、指令执行与交互推理能力。该数据集的创建填补了中欧语言在指令微调与评估基准中的空白,为多语言大模型的可迁移性研究提供了关键资源,对推动捷克语自然语言处理应用及跨语言模型鲁棒性验证具有重要影响力。
当前挑战
该数据集所解决的领域问题在于大语言模型在捷克语等低资源语种上的指令遵循与对话协作能力评估。其核心挑战包括:1)捷克语形态复杂与语序灵活导致的语义解析困难,需确保种子提示与智能体轨迹的生成符合语言内在逻辑;2)构建过程中需从零收集高质量捷克语交互数据,克服标注资源匮乏与领域专家稀缺的瓶颈;3)模型生成的智能体轨迹须忠实反映多步骤推理与上下文依赖性,这对提示设计与验证流程提出严苛要求。这些挑战共同指向如何在数据有限前提下,保障数据集的代表性、一致性及评估结果的可靠性。
常用场景
经典使用场景
在自然语言处理与智能体系统研究的前沿领域,gsd-smith-Czech数据集为捷克语环境下的大语言模型微调与评估提供了重要资源。其经典使用场景聚焦于构建捷克语对话智能体,通过包含seed_prompt、messages和agent_trace的结构化数据,研究者能够训练模型在特定任务中遵循指令、进行多轮交互并记录推理轨迹。该数据集特别适用于少样本学习场景,543条精心设计的训练实例足以支撑对模型指令遵循能力和工具调用能力的初步验证,为捷克语低资源语言的研究开辟了新的可能性。
解决学术问题
该数据集的核心学术价值在于它直面了低资源语言中智能体系统开发的长期困境。传统大语言模型研究多集中于英语等高资源语言,捷克语等语言的指令微调数据极度匮乏,导致模型在非英语环境中的表现大打折扣。gsd-smith-Czech通过提供标准化的seed_prompt与agent_trace结构,使得研究者能够系统性地评估模型在捷克语环境下的推理链完整性、工具调用准确性及对多义性指令的理解能力,从而为多语言智能体的鲁棒性和泛化性研究提供了可重复的基准。
衍生相关工作
围绕gsd-smith-Czech数据集,衍生出多项开创性研究。一方面,研究者基于其结构设计开发了针对捷克语的指令微调方法,如引入对抗性seed_prompt以增强模型对无效请求的拒绝能力;另一方面,agent_trace的细粒度记录催生了推理链评估指标,用于量化模型规划步骤的合理性。此外,该数据集常与多语言智能体框架结合使用,如将其融入Smith Agent基准测试中,评估捷克语模型与工具编排引擎的兼容性,为构建跨语言通用智能体提供了关键实验依据。
以上内容由遇见数据集搜集并总结生成


