AI-MO/NuminaMath-TIR
收藏Hugging Face2024-11-25 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/AI-MO/NuminaMath-TIR
下载链接
链接失效反馈官方服务:
资源简介:
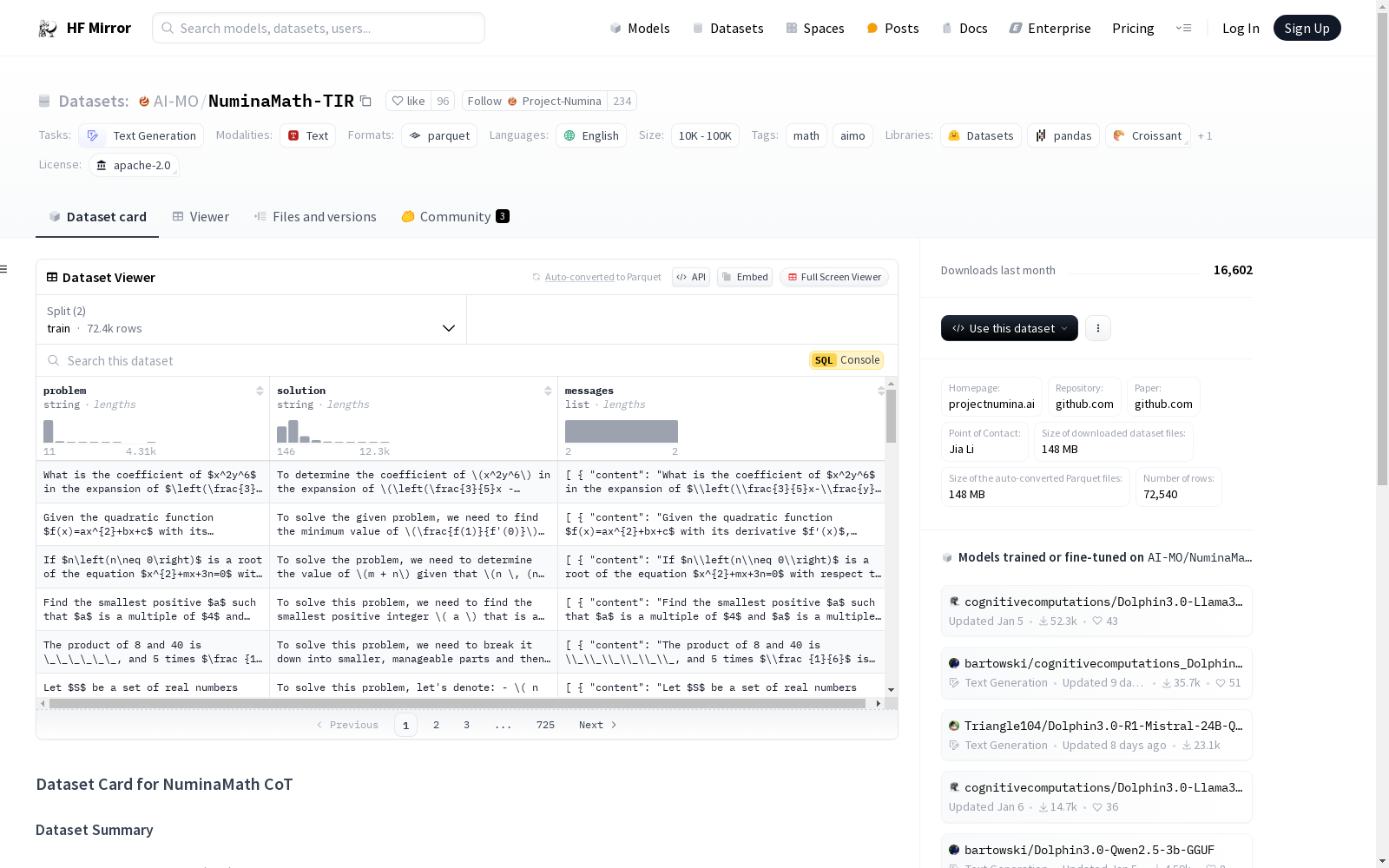
NuminaMath TIR数据集主要用于文本生成任务,特别是与数学问题相关的工具集成推理(TIR)。数据集包含约70k个问题,这些问题是从NuminaMath-CoT数据集中选取的,主要集中在具有数值输出的问题上。数据集通过使用GPT-4生成类似TORA的推理路径,并通过执行代码来生成结果,直到解决方案完成。数据集经过多次迭代以确保准确性和一致性。数据集的特征包括问题、解决方案和消息列表,消息列表中包含内容和角色。数据集分为训练集和测试集,训练集包含72441个样本,测试集包含99个样本。数据集的使用受CC BY-NC 4.0许可限制。
The NuminaMath TIR dataset is primarily used for text generation tasks, particularly tool-integrated reasoning (TIR) related to mathematical problems. The dataset contains approximately 70k problems selected from the NuminaMath-CoT dataset, focusing on those with numerical outputs. The dataset utilizes GPT-4 to generate TORA-like reasoning paths and executes code to produce results until the solution is complete. The dataset has undergone multiple iterations to ensure accuracy and consistency. The features of the dataset include problem, solution, and a list of messages, with the message list containing content and role. The dataset is divided into a training set with 72,441 samples and a test set with 99 samples. The use of the dataset is restricted by the CC BY-NC 4.0 license.
提供机构:
AI-MO
原始信息汇总
NuminaMath TIR 数据集概述
数据集描述
数据集摘要
- 任务类别: 文本生成
- 数据集名称: NuminaMath TIR
- 数据来源: 从NuminaMath-CoT数据集中选取约70k个问题,主要关注具有数值输出的问题,大部分为整数。
- 数据生成: 使用GPT-4生成TORA-like推理路径,执行代码并生成结果,直到解决方案完成。
- 数据筛选: 过滤掉最终答案与参考答案不匹配的解决方案,并重复此过程三次以确保准确性和一致性。
数据集结构
- 特征:
problem: 问题描述,数据类型为字符串。solution: 解决方案,数据类型为字符串。messages: 包含内容和角色的列表,数据类型均为字符串。
- 数据分割:
train: 包含72441个样本,大小为327147067字节。test: 包含99个样本,大小为461331字节。
- 数据大小:
- 下载大小: 147557990字节
- 数据集总大小: 327608398字节
许可证信息
- 许可证: Creative Commons NonCommercial (CC BY-NC 4.0)
引用信息
@misc{numina_math_datasets, author = {Jia LI, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu}, title = {NuminaMath TIR}, year = {2024}, publisher = {Numina}, journal = {Hugging Face repository}, howpublished = {url{https://huggingface.co/AI-MO/NuminaMath-TIR}} }
搜集汇总
数据集介绍
构建方式
NuminaMath-TIR数据集的构建过程体现了高效与精确的结合。该数据集从NuminaMath-CoT中精选了约70,000个数学问题,主要集中在具有数值输出的题目上,其中多数为整数结果。通过利用GPT-4的强大能力,生成类似TORA的推理路径,并执行代码直至得出最终解答。为确保数据的准确性,团队对最终答案与参考不符的解决方案进行了过滤,并重复此过程三次,从而确保了数据的高质量和一致性。
特点
NuminaMath-TIR数据集的特点在于其专注于数学问题的工具集成推理(TIR),这为研究者和开发者提供了一个丰富的资源库。数据集中的每个问题都配有详细的解决方案和推理路径,这些路径通过高级语言模型生成,确保了逻辑的严密性和解答的准确性。此外,数据集中的问题多样,涵盖了广泛的数学领域,使得它成为测试和开发数学推理模型的理想选择。
使用方法
NuminaMath-TIR数据集的使用方法简便而高效。用户可以通过Hugging Face平台直接访问数据集,利用其提供的API进行数据加载和处理。数据集适用于文本生成任务,特别是那些需要复杂数学推理的应用场景。开发者可以利用这些数据训练和评估自己的模型,特别是在需要高精度数学解答的系统中。此外,数据集的开放许可也为学术研究和商业应用提供了便利。
背景与挑战
背景概述
NuminaMath-TIR数据集由Numina团队于2024年发布,旨在推动数学问题求解领域的研究,特别是工具集成推理(TIR)的应用。该数据集由Jia Li等研究人员主导开发,基于NuminaMath-CoT数据集中的约70,000个数学问题构建,重点关注数值输出问题。通过利用GPT-4生成推理路径并执行代码,研究人员确保了数据的高质量和一致性。该数据集为数学推理模型的训练和评估提供了重要资源,对推动自动推理和代码生成技术的发展具有深远影响。
当前挑战
NuminaMath-TIR数据集在构建过程中面临多重挑战。首先,工具集成推理(TIR)数据的收集和标注成本高昂且耗时,需要高效的自动化流程来生成高质量数据。其次,确保生成推理路径的准确性和一致性是关键难题,研究人员通过多次迭代和过滤机制来解决这一问题。此外,数学问题的多样性和复杂性也对数据集的构建提出了更高要求,需要兼顾问题的覆盖范围和模型的泛化能力。这些挑战不仅反映了数据集构建的技术难度,也为未来研究提供了改进方向。
常用场景
经典使用场景
NuminaMath-TIR数据集在数学问题求解领域具有广泛的应用,尤其是在工具集成推理(TIR)任务中。该数据集通过提供大量带有详细推理路径的数学问题及其解决方案,为研究人员和开发者提供了一个理想的实验平台。经典的使用场景包括训练和评估基于大语言模型的数学推理系统,这些系统能够生成类似于TORA的推理路径,并通过代码执行验证其正确性。
衍生相关工作
NuminaMath-TIR数据集的发布推动了多个相关研究领域的发展。基于该数据集,研究人员开发了多种先进的数学推理模型,如基于GPT-4的推理路径生成系统。这些模型不仅在学术界引起了广泛关注,还在工业界得到了实际应用。此外,该数据集还激发了更多关于工具集成推理的研究,进一步推动了数学问题求解技术的发展。
数据集最近研究
最新研究方向
在数学推理领域,NuminaMath-TIR数据集的推出标志着工具集成推理(TIR)技术的显著进步。该数据集通过结合GPT-4的强大生成能力,专注于数值输出问题的解决,特别是整数结果的问题。这种方法的创新之处在于其高效的数据生成和验证流程,通过多次迭代确保解决方案的准确性和一致性。当前的研究热点集中在如何进一步优化这种自动化推理路径的生成,以及如何将这种技术应用于更广泛的数学问题解决中。此外,该数据集的应用也推动了数学教育技术的发展,特别是在自动解题和智能辅导系统方面,展现了其深远的教育和技术影响。
以上内容由遇见数据集搜集并总结生成


