Akseltinfat/Tifinagh-OCR-39K
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/Akseltinfat/Tifinagh-OCR-39K
下载链接
链接失效反馈官方服务:
资源简介:
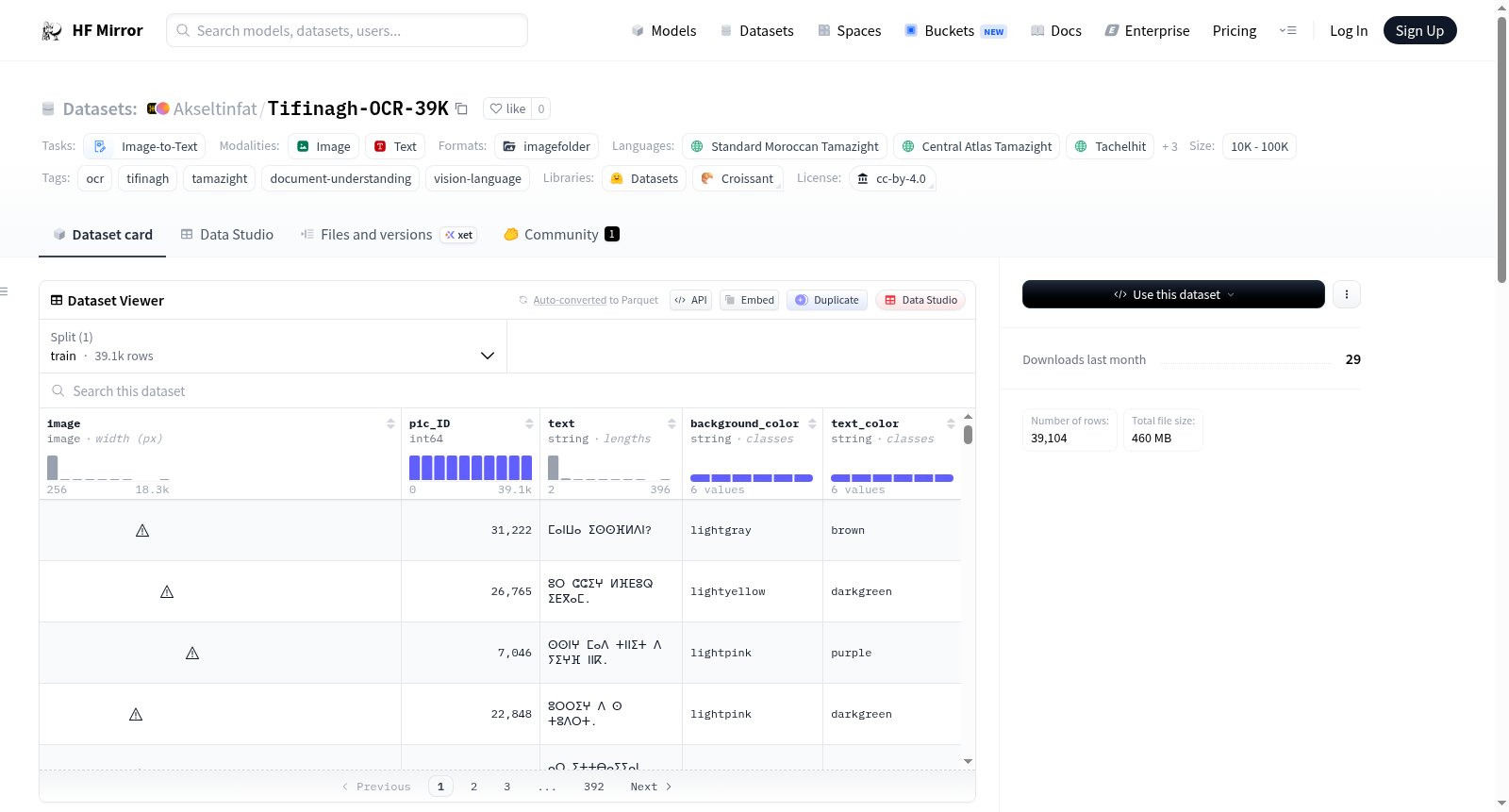
该数据集是一个包含39,101个合成图像的全面集合,专为训练和评估Tifinagh脚本的OCR和视觉语言模型而设计。它包含了多种字体、背景颜色和文本样式的矩形格式图像。数据集中的每个样本都包含图像文件路径、真实的Tifinagh转录文本、背景颜色、文本颜色和唯一的图像标识符。该数据集适用于Tifinagh OCR训练、Amazigh语言文档理解、视觉语言模型验证以及跨不同排版样式的鲁棒性测试。
This dataset is a comprehensive collection of 39,101 synthetic images designed for training and evaluating OCR and vision-language models for the Tifinagh script. It features a wide variety of fonts, background colors, and text styles in a rectangular format. Each sample in the dataset contains the image file path, ground-truth Tifinagh transcription, background color, text color, and a unique image identifier. The dataset is suitable for Tifinagh OCR training, document understanding for Amazigh languages, vision-language model validation, and robustness testing across different typographic styles.
提供机构:
Akseltinfat
搜集汇总
数据集介绍
构建方式
该数据集通过合成技术构建,共计生成39,101张提非纳文字符图像。图像以PNG格式存储,并采用动态缩放与居中对齐策略以优化矩形布局。构建过程中融合了多元化的字体类型(包括IRCAM、Tawalt及Madghis Madi)与丰富的背景、文字色彩组合,确保数据在视觉风格上的多样性。每一条样本均以JSONL元数据文件记录,包含图像文件名、真实提非纳文转录文本、背景颜色、文字颜色及唯一图像标识符,且元数据经过随机打乱处理,便于在数据集预览器中展示不同字体与风格的样本。
使用方法
该数据集以Hugging Face数据集格式发布,可通过`datasets`库直接加载。用户使用`load_dataset("Tamazight/Tifinagh-OCR-39K")`即可获取训练集,其中每条样本包含图像与文本字段,支持直接调用`sample["image"].show()`方法可视化图像,或通过`sample["text"]`读取真实标注。该数据集主要面向提非纳文OCR训练与评估、阿马齐格语言文档理解、视觉语言模型验证,以及跨不同字体风格的鲁棒性测试等应用场景。
背景与挑战
背景概述
Tifinagh-OCR-39K数据集由Aksel Tinfat于2024年创建,隶属于HuggingFace上的Tamazight项目,旨在推动提非纳文脚本的光学字符识别(OCR)与视觉-语言模型研究。提非纳文作为阿马齐格语(如标准摩洛哥塔马齐特语、沙维亚语等)的书写系统,长期缺乏大规模标注数据,严重制约了该语言在数字文档理解与多模态模型中的应用。该数据集提供了39,101张合成图像,涵盖IRCAM、Tawalt和Madghis Madi等多种字体以及丰富的背景与文本颜色组合,为训练鲁棒的OCR模型奠定了坚实基础。其对阿马齐格语社区和低资源文字OCR领域的贡献,彰显了数据驱动方法在濒危语言数字化保护中的关键作用。
当前挑战
该数据集所解决的领域挑战在于提非纳文OCR任务的特殊性:字形多变且与拉丁字母结构差异显著,现有模型难以直接迁移,加之真实标注数据稀缺,使模型泛化能力受限。构建过程中,合成数据虽能大幅扩充样本,但面临着字体风格、背景噪声与文本布局的多样性平衡难题,以避免模型过拟合于特定渲染参数。此外,确保合成数据与真实场景分布的一致性,以及高效生成39K规模图像时的质量控制(如文本居中性与色彩对比度),均是技术挑战。这些努力为后续在混杂光照与歪斜文本下的稳健识别奠定了数据处理与评估基准。
常用场景
经典使用场景
Tifinagh-OCR-39K数据集专为提非纳文字的图像到文本转换任务而构建,在光学字符识别(OCR)领域开辟了针对阿马齐格语系的全新研究路径。其典型应用场景包括训练和评估能够识别提非纳字符的深度学习模型,覆盖从单一字符到完整文本行的多样化图像样本。该数据集通过合成3.9万余张矩形图像,融合了IRCAM、Tawalt、Madghis Madi等多种字体样式以及丰富的背景与文字色彩组合,为OCR模型提供了极具挑战性的训练素材。研究者可以利用这一资源开发鲁棒的文字识别系统,尤其适用于形态学复杂的非拉丁文字体系,从而推动少数民族语言数字化进程。
解决学术问题
该数据集着力解决提非纳文字OCR研究中长期存在的训练数据匮乏问题,填补了阿马齐格语系数字资源在计算机视觉领域的空白。传统OCR方法主要聚焦于拉丁文字或常见非拉丁文字,而提非纳文字因其区域性限制和字体多样性,在公开数据集中几乎缺席。Tifinagh-OCR-39K通过系统性合成数据生成策略,提供了涵盖多种字体、颜色和噪声环境的标注样本,使研究者能够量化评估模型在不同印刷风格下的泛化能力。这一资源不仅支持OCR主干网络的性能基准测试,更催生了针对低资源文字的场景文本识别、文档版面分析及跨语言视觉语言模型的对比研究,为保护濒危书写系统提供了可复现的学术工具。
实际应用
在实际应用层面,Tifinagh-OCR-39K数据集为摩洛哥、阿尔及利亚等北非地区的阿马齐格语文化保护与行政信息化提供了关键技术支撑。基于该数据集训练的OCR模型可被部署于历史手抄本的数字化转录系统,帮助博物馆和档案馆将提非纳文古籍转化为可检索的电子文本。同时,在车牌识别、路标翻译、教育材料自动批改等垂直场景中,该数据集训练的模型能够适应提非纳文字与阿拉伯语或法语共存的混合文档环境。此外,通过适配边缘计算设备,该数据集衍生的轻量级识别方案正在推动智能手机端即时文字翻译应用的落地,从而弥合数字鸿沟,促进多语言信息无障碍传播。
数据集最近研究
最新研究方向
在低资源文字识别领域,Tifinagh-OCR-39K数据集的诞生恰逢全球对濒危语言数字化保护的高度关注。随着联合国教科文组织推动的“国际土著语言十年”计划进入关键阶段,北非柏柏尔语族(Amazigh)的文字数字化成为前沿热点。该数据集提供了近4万张涵盖多种字体与背景的合成图像,为突破传统OCR对阿拉伯字母、拉丁字母的依赖、验证视觉语言模型在非主流书写系统中的鲁棒性提供了标准化基准。其背后的“摩洛哥标准化Tifinagh”字体(IRCAM)与撒哈拉地区口传文化结合的研究路径,正推动着多语种文档理解向文化包容性方向演进,对保存和活化撒哈拉-萨赫勒地区的古老文字系统具有里程碑式意义。
以上内容由遇见数据集搜集并总结生成


