structured_images
收藏Hugging Face2024-12-16 更新2024-12-17 收录
下载链接:
https://huggingface.co/datasets/JoyboyBrian/structured_images
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含多个配置,涵盖不同类型的文档图像及其对应的json数据。主要配置包括名片、电子邮件文档、发票和收据、电影海报等。每个配置的训练集提供了详细的数据量、下载大小和数据集大小信息。
创建时间:
2024-12-15
原始信息汇总
数据集概述
该数据集包含多个配置,每个配置对应不同类型的图像数据及其相关元数据。以下是各配置的详细信息:
配置列表
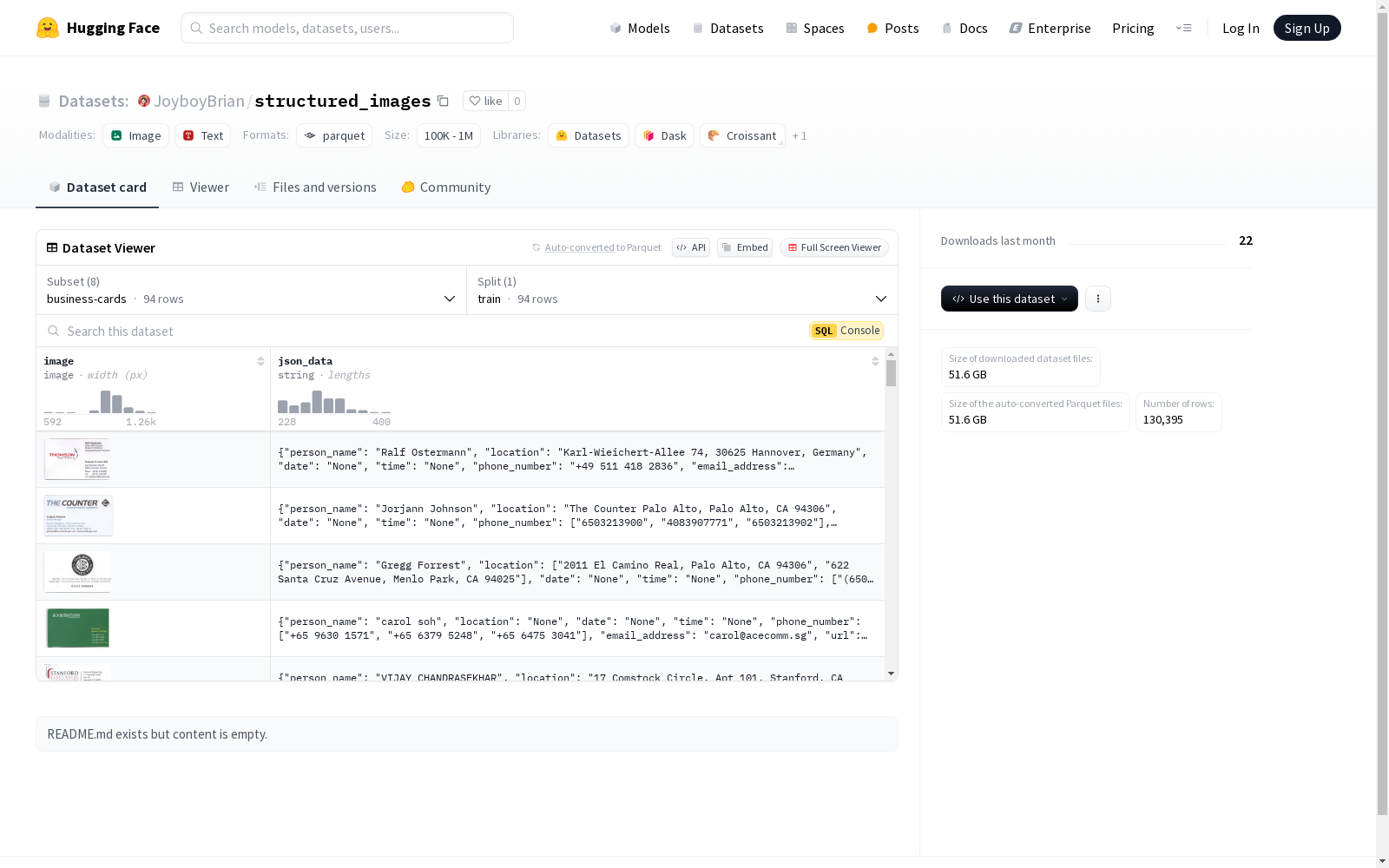
1. business-cards
- 特征:
image: 图像数据,类型为image。json_data: 元数据,类型为string。
- 数据分割:
train: 包含 94 个样本,占用 8778365.0 字节。
- 下载大小: 8756102 字节。
- 数据集大小: 8778365.0 字节。
2. documents-email
- 特征:
image: 图像数据,类型为image。json_data: 元数据,类型为string。
- 数据分割:
train: 包含 2516 个样本,占用 250029932.468 字节。
- 下载大小: 246890798 字节。
- 数据集大小: 250029932.468 字节。
3. invoices-and-receipts
- 特征:
image: 图像数据,类型为image。json_data: 元数据,类型为string。
- 数据分割:
train: 包含 1618 个样本,占用 1291753321.334 字节。
- 下载大小: 1285335853 字节。
- 数据集大小: 1291753321.334 字节。
4. invoices-google-ocr
- 特征:
image: 图像数据,类型为image。json_data: 元数据,类型为string。
- 数据分割:
train: 包含 16829 个样本,占用 3049319114.546 字节。
- 下载大小: 3037783991 字节。
- 数据集大小: 3049319114.546 字节。
5. poster-movie-festival
- 特征:
image: 图像数据,类型为image。json_data: 元数据,类型为string。
- 数据分割:
train: 包含 3668 个样本,占用 180963219.16 字节。
- 下载大小: 180286819 字节。
- 数据集大小: 180963219.16 字节。
6. synthetic-movies-poster
- 特征:
image: 图像数据,类型为image。json_data: 元数据,类型为string。
- 数据分割:
train: 包含 95297 个样本,占用 44201134217.875 字节。
- 下载大小: 43982841227 字节。
- 数据集大小: 44201134217.875 字节。
7. ui_screenshot
- 特征:
image: 图像数据,类型为image。json_data: 元数据,类型为string。
- 数据分割:
train: 包含 8308 个样本,占用 1126779267.884 字节。
- 下载大小: 956455104 字节。
- 数据集大小: 1126779267.884 字节。
8. wild-receipts
- 特征:
image: 图像数据,类型为image。json_data: 元数据,类型为string。
- 数据分割:
train: 包含 2065 个样本,占用 1942241746.965 字节。
- 下载大小: 1941974854 字节。
- 数据集大小: 1942241746.965 字节。
数据文件路径
business-cards:business-cards/train-*documents-email:documents-email/train-*invoices-and-receipts:invoices-and-receipts/train-*invoices-google-ocr:invoices-google-ocr/train-*poster-movie-festival:poster-movie-festival/train-*synthetic-movies-poster:synthetic-movies-poster/train-*ui_screenshot:ui_screenshot/train-*wild-receipts:wild-receipts/train-*
搜集汇总
数据集介绍
构建方式
structured_images数据集通过整合多种类型的结构化图像及其对应的元数据构建而成。该数据集涵盖了从商业名片、电子邮件文档到电影海报等多种图像类型,每种图像类型均配有详细的JSON格式元数据。数据集的构建过程中,图像与元数据被精心配对,确保每张图像都有相应的结构化信息,从而为图像处理和信息提取任务提供了丰富的资源。
使用方法
structured_images数据集适用于多种图像处理和信息提取任务。用户可以通过加载数据集中的图像和对应的JSON元数据,进行图像分类、文本识别、布局分析等任务。数据集的多样性使得它能够支持多种应用场景,如商业文档处理、电影海报分析等。使用时,用户可以根据具体需求选择不同的配置(如business-cards、invoices-and-receipts等),并利用数据集提供的图像和元数据进行模型训练和评估。
背景与挑战
背景概述
structured_images数据集由多个子集组成,涵盖了从商业名片到电影海报等多种图像类型,旨在为结构化图像处理提供丰富的数据资源。该数据集的核心研究问题在于如何从复杂的图像中提取结构化信息,并将其应用于诸如文档分析、图像识别等任务。通过整合不同领域的图像数据,structured_images为研究人员提供了一个多样的实验平台,推动了图像处理技术在实际应用中的发展。
当前挑战
structured_images数据集在构建过程中面临多项挑战。首先,不同类型的图像具有显著的多样性,如何确保数据集的广泛性和代表性是一个重要问题。其次,图像中的结构化信息提取需要高精度的算法支持,这对数据标注和处理提出了高要求。此外,数据集的规模庞大,如何高效地存储和处理这些数据也是一个技术难题。这些挑战不仅影响了数据集的质量,也对后续的研究和应用提出了更高的技术要求。
常用场景
经典使用场景
structured_images数据集在图像与结构化数据结合的领域中展现了其独特的应用价值。该数据集通过将图像与对应的结构化数据(如JSON格式)相结合,广泛应用于光学字符识别(OCR)、文档解析以及图像内容理解等任务。例如,在商业名片、发票和收据的自动识别与信息提取中,structured_images数据集为模型提供了丰富的训练样本,使得模型能够准确地从图像中提取关键信息并进行结构化输出。
解决学术问题
structured_images数据集在解决图像与文本信息融合的学术问题上具有重要意义。传统的图像识别任务往往仅关注图像本身的特征,而该数据集通过引入结构化数据,使得研究者能够探索如何将图像与文本信息进行有效结合,从而提升模型的理解能力。这一研究方向不仅推动了OCR技术的进步,还为文档智能处理、信息提取等领域提供了新的研究思路和实验平台。
实际应用
在实际应用中,structured_images数据集被广泛应用于自动化办公、金融票据处理、零售业收据管理等场景。例如,在企业财务管理中,该数据集支持自动识别和解析发票、收据等文档,极大地提高了财务处理的效率和准确性。此外,在电影海报和商业广告的分析中,structured_images数据集也为图像内容的自动标注和分类提供了强大的支持,进一步推动了相关行业的智能化进程。
数据集最近研究
最新研究方向
在图像处理与结构化数据提取领域,structured_images数据集的最新研究方向主要集中在多模态信息融合与自动化文档解析。随着深度学习技术的进步,研究者们致力于开发能够同时处理图像与结构化文本数据的模型,以提升文档识别与信息提取的准确性。特别是在商业票据、发票和电影海报等复杂场景中,如何有效结合图像特征与文本信息,成为当前研究的热点。此外,合成数据的应用也为模型训练提供了更为丰富的资源,推动了模型在实际应用中的泛化能力。这些研究不仅在学术界引发了广泛关注,也在工业界推动了自动化办公和智能文档处理的实际应用。
以上内容由遇见数据集搜集并总结生成


