shibing624/nli_zh
收藏Hugging Face2022-10-30 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/shibing624/nli_zh
下载链接
链接失效反馈资源简介:
---
annotations_creators:
- shibing624
language_creators:
- shibing624
language:
- zh
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<20M
source_datasets:
- https://github.com/shibing624/text2vec
- https://github.com/IceFlameWorm/NLP_Datasets/tree/master/ATEC
- http://icrc.hitsz.edu.cn/info/1037/1162.htm
- http://icrc.hitsz.edu.cn/Article/show/171.html
- https://arxiv.org/abs/1908.11828
- https://github.com/pluto-junzeng/CNSD
task_categories:
- text-classification
task_ids:
- natural-language-inference
- semantic-similarity-scoring
- text-scoring
paperswithcode_id: snli
pretty_name: Stanford Natural Language Inference
---
# Dataset Card for NLI_zh
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** [Chinese NLI dataset](https://github.com/shibing624/text2vec)
- **Leaderboard:** [NLI_zh leaderboard](https://github.com/shibing624/text2vec) (located on the homepage)
- **Size of downloaded dataset files:** 16 MB
- **Total amount of disk used:** 42 MB
### Dataset Summary
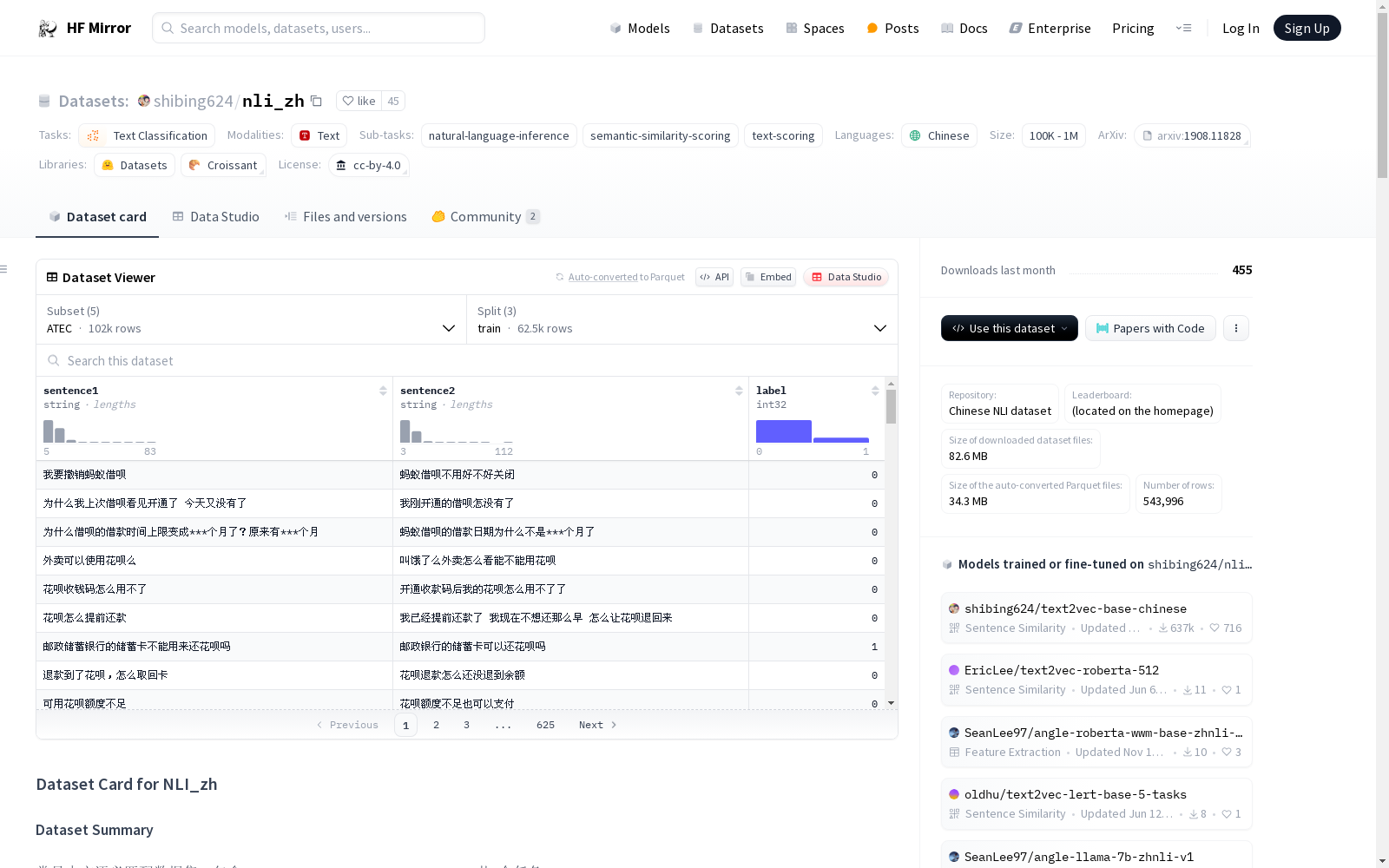
常见中文语义匹配数据集,包含[ATEC](https://github.com/IceFlameWorm/NLP_Datasets/tree/master/ATEC)、[BQ](http://icrc.hitsz.edu.cn/info/1037/1162.htm)、[LCQMC](http://icrc.hitsz.edu.cn/Article/show/171.html)、[PAWSX](https://arxiv.org/abs/1908.11828)、[STS-B](https://github.com/pluto-junzeng/CNSD)共5个任务。
数据源:
- ATEC: https://github.com/IceFlameWorm/NLP_Datasets/tree/master/ATEC
- BQ: http://icrc.hitsz.edu.cn/info/1037/1162.htm
- LCQMC: http://icrc.hitsz.edu.cn/Article/show/171.html
- PAWSX: https://arxiv.org/abs/1908.11828
- STS-B: https://github.com/pluto-junzeng/CNSD
### Supported Tasks and Leaderboards
Supported Tasks: 支持中文文本匹配任务,文本相似度计算等相关任务。
中文匹配任务的结果目前在顶会paper上出现较少,我罗列一个我自己训练的结果:
**Leaderboard:** [NLI_zh leaderboard](https://github.com/shibing624/text2vec)
### Languages
数据集均是简体中文文本。
## Dataset Structure
### Data Instances
An example of 'train' looks as follows.
```
{
"sentence1": "刘诗诗杨幂谁漂亮",
"sentence2": "刘诗诗和杨幂谁漂亮",
"label": 1,
}
{
"sentence1": "汇理财怎么样",
"sentence2": "怎么样去理财",
"label": 0,
}
```
### Data Fields
The data fields are the same among all splits.
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `label`: a classification label, with possible values including `similarity` (1), `dissimilarity` (0).
### Data Splits
#### ATEC
```shell
$ wc -l ATEC/*
20000 ATEC/ATEC.test.data
62477 ATEC/ATEC.train.data
20000 ATEC/ATEC.valid.data
102477 total
```
#### BQ
```shell
$ wc -l BQ/*
10000 BQ/BQ.test.data
100000 BQ/BQ.train.data
10000 BQ/BQ.valid.data
120000 total
```
#### LCQMC
```shell
$ wc -l LCQMC/*
12500 LCQMC/LCQMC.test.data
238766 LCQMC/LCQMC.train.data
8802 LCQMC/LCQMC.valid.data
260068 total
```
#### PAWSX
```shell
$ wc -l PAWSX/*
2000 PAWSX/PAWSX.test.data
49401 PAWSX/PAWSX.train.data
2000 PAWSX/PAWSX.valid.data
53401 total
```
#### STS-B
```shell
$ wc -l STS-B/*
1361 STS-B/STS-B.test.data
5231 STS-B/STS-B.train.data
1458 STS-B/STS-B.valid.data
8050 total
```
## Dataset Creation
### Curation Rationale
作为中文NLI(natural langauge inference)数据集,这里把这个数据集上传到huggingface的datasets,方便大家使用。
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
数据集的版权归原作者所有,使用各数据集时请尊重原数据集的版权。
BQ: Jing Chen, Qingcai Chen, Xin Liu, Haijun Yang, Daohe Lu, Buzhou Tang, The BQ Corpus: A Large-scale Domain-specific Chinese Corpus For Sentence Semantic Equivalence Identification EMNLP2018.
### Annotations
#### Annotation process
#### Who are the annotators?
原作者。
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
This dataset was developed as a benchmark for evaluating representational systems for text, especially including those induced by representation learning methods, in the task of predicting truth conditions in a given context.
Systems that are successful at such a task may be more successful in modeling semantic representations.
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
- 苏剑林对文件名称有整理
- 我上传到huggingface的datasets
### Licensing Information
用于学术研究。
The BQ corpus is free to the public for academic research.
### Contributions
Thanks to [@shibing624](https://github.com/shibing624) add this dataset.
---
注释创建者:
- shibing624
语言创建者:
- shibing624
语言:
- 简体中文(zh)
许可证:
- CC BY 4.0(知识共享署名4.0国际许可协议)
多语言属性:
- 单语言(monolingual)
规模类别:
- 10万 < 数据量 < 2000万
源数据集:
- https://github.com/shibing624/text2vec
- https://github.com/IceFlameWorm/NLP_Datasets/tree/master/ATEC
- http://icrc.hitsz.edu.cn/info/1037/1162.htm
- http://icrc.hitsz.edu.cn/Article/show/171.html
- https://arxiv.org/abs/1908.11828
- https://github.com/pluto-junzeng/CNSD
任务类别:
- 文本分类(text-classification)
任务子项:
- 自然语言推理(natural-language-inference)
- 语义相似度评分(semantic-similarity-scoring)
- 文本评分(text-scoring)
PapersWithCode 编号:snli
展示名称:斯坦福自然语言推理数据集(Stanford Natural Language Inference)
---
# NLI_zh 数据集卡片
## 目录
- [数据集概述](#数据集概述)
- [数据集摘要](#数据集摘要)
- [支持任务与排行榜](#支持任务与排行榜)
- [语言情况](#语言情况)
- [数据集结构](#数据集结构)
- [数据样例](#数据样例)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集构建](#数据集构建)
- [构建初衷](#构建初衷)
- [源数据](#源数据)
- [注释信息](#注释信息)
- [个人与敏感信息](#个人与敏感信息)
- [数据集使用注意事项](#数据集使用注意事项)
- [数据集的社会影响](#数据集的社会影响)
- [偏倚讨论](#偏倚讨论)
- [其他已知局限](#其他已知局限)
- [附加信息](#附加信息)
- [数据集维护者](#数据集维护者)
- [许可信息](#许可信息)
- [引用信息](#引用信息)
- [贡献](#贡献)
## 数据集概述
- **代码仓库**:[中文自然语言推理数据集](https://github.com/shibing624/text2vec)
- **排行榜**:[NLI_zh 排行榜](https://github.com/shibing624/text2vec)(位于项目主页)
- **下载数据集文件总大小**:16 MB
- **占用磁盘总空间**:42 MB
### 数据集摘要
本数据集为通用中文语义匹配数据集,整合了ATEC、BQ、LCQMC、PAWSX、STS-B共5个公开语义匹配任务数据集。各子数据集来源链接如下:
- ATEC: https://github.com/IceFlameWorm/NLP_Datasets/tree/master/ATEC
- BQ: http://icrc.hitsz.edu.cn/info/1037/1162.htm
- LCQMC: http://icrc.hitsz.edu.cn/Article/show/171.html
- PAWSX: https://arxiv.org/abs/1908.11828
- STS-B: https://github.com/pluto-junzeng/CNSD
### 支持任务与排行榜
支持任务:涵盖中文文本匹配、文本相似度计算等相关自然语言处理任务。当前中文匹配任务的顶会公开研究成果较为稀缺,本项目提供了自主训练的模型性能排行榜:
**排行榜:[NLI_zh 排行榜](https://github.com/shibing624/text2vec)**
### 语言情况
本数据集全部采用简体中文文本。
## 数据集结构
### 数据样例
训练集的一条样例格式如下:
{
"sentence1": "刘诗诗杨幂谁漂亮",
"sentence2": "刘诗诗和杨幂谁漂亮",
"label": 1,
}
{
"sentence1": "汇理财怎么样",
"sentence2": "怎么样去理财",
"label": 0,
}
### 数据字段
所有数据划分的字段均保持一致:
- `sentence1`: 字符串类型特征,代表第一个输入句子
- `sentence2`: 字符串类型特征,代表第二个输入句子
- `label`: 分类标签,可选值包括`similarity`(1,代表句子语义相似)、`dissimilarity`(0,代表句子语义不相似)
### 数据划分
#### ATEC
shell
$ wc -l ATEC/*
20000 ATEC/ATEC.test.data
62477 ATEC/ATEC.train.data
20000 ATEC/ATEC.valid.data
102477 total
#### BQ
shell
$ wc -l BQ/*
10000 BQ/BQ.test.data
100000 BQ/BQ.train.data
10000 BQ/BQ.valid.data
120000 total
#### LCQMC
shell
$ wc -l LCQMC/*
12500 LCQMC/LCQMC.test.data
238766 LCQMC/LCQMC.train.data
8802 LCQMC/LCQMC.valid.data
260068 total
#### PAWSX
shell
$ wc -l PAWSX/*
2000 PAWSX/PAWSX.test.data
49401 PAWSX/PAWSX.train.data
2000 PAWSX/PAWSX.valid.data
53401 total
#### STS-B
shell
$ wc -l STS-B/*
1361 STS-B/STS-B.test.data
5231 STS-B/STS-B.train.data
1458 STS-B/STS-B.valid.data
8050 total
## 数据集构建
### 构建初衷
本数据集为中文自然语言推理(Natural Language Inference, NLI)专用数据集,已上传至Hugging Face Datasets平台以方便全球研究者便捷使用。
### 源数据
#### 初始数据收集与标准化
#### 源文本生产者是谁?
本数据集的版权归属各子数据集的原作者所有,使用各子数据集时请遵守其原版权协议。其中BQ数据集的相关学术引用为:Jing Chen, Qingcai Chen, Xin Liu, Haijun Yang, Daohe Lu, Buzhou Tang, *The BQ Corpus: A Large-scale Domain-specific Chinese Corpus For Sentence Semantic Equivalence Identification*, 发表于EMNLP 2018。
### 注释信息
#### 注释流程
#### 注释者是谁?
本数据集的注释工作由各子数据集的原作者完成。
### 个人与敏感信息
(本部分无相关内容)
## 数据集使用注意事项
### 数据集的社会影响
本数据集旨在构建用于评估文本表征学习系统的基准测试集,尤其适用于基于表征学习方法训练得到的模型,用于预测给定上下文下的语义真值条件。在该任务上表现优异的模型,通常在语义表征建模任务中也能取得更优的性能。
### 偏倚讨论
(本部分无相关内容)
### 其他已知局限
(本部分无相关内容)
## 附加信息
### 数据集维护者
- 苏剑林完成了数据集文件的命名整理工作
- 本数据集由贡献者上传至Hugging Face Datasets平台
### 许可信息
本数据集仅可用于学术研究用途。其中BQ数据集可免费开放用于学术研究。
### 引用信息
(本部分原文未提供详细内容)
### 贡献
感谢[@shibing624](https://github.com/shibing624)贡献本数据集。
提供机构:
shibing624
原始信息汇总
数据集概述
数据集描述
- 名称: NLI_zh
- 语言: 中文(简体)
- 许可证: CC-BY-4.0
- 多语言性: 单语种
- 大小: 100K<n<20M
- 任务类别: 文本分类
- 任务ID: 自然语言推理, 语义相似度评分, 文本评分
- 论文代码ID: snli
- 美观名称: Stanford Natural Language Inference
数据集结构
数据实例
json { "sentence1": "刘诗诗杨幂谁漂亮", "sentence2": "刘诗诗和杨幂谁漂亮", "label": 1 } { "sentence1": "汇理财怎么样", "sentence2": "怎么样去理财", "label": 0 }
数据字段
sentence1: 字符串类型sentence2: 字符串类型label: 分类标签,可能的值为相似(1)和不相似(0)
数据集创建
源数据
- ATEC: https://github.com/IceFlameWorm/NLP_Datasets/tree/master/ATEC
- BQ: http://icrc.hitsz.edu.cn/info/1037/1162.htm
- LCQMC: http://icrc.hitsz.edu.cn/Article/show/171.html
- PAWSX: https://arxiv.org/abs/1908.11828
- STS-B: https://github.com/pluto-junzeng/CNSD
数据集分割
- ATEC: 训练集62477条,验证集20000条,测试集20000条
- BQ: 训练集100000条,验证集10000条,测试集10000条
- LCQMC: 训练集238766条,验证集8802条,测试集12500条
- PAWSX: 训练集49401条,验证集2000条,测试集2000条
- STS-B: 训练集5231条,验证集1458条,测试集1361条
许可证信息
- BQ corpus: 免费公开,供学术研究使用
贡献者
- shibing624: 添加此数据集
- 苏剑林: 整理文件名称
搜集汇总
数据集介绍
构建方式
该数据集的构建主要基于多个中文语义匹配任务的集成,包括ATEC、BQ、LCQMC、PAWSX和STS-B五个子任务的数据集。这些子任务数据集分别来源于不同的研究领域和学术资源,经过收集、整理和规范化处理后,形成了统一的NLI_zh数据集,旨在为自然语言处理研究提供丰富的中文文本匹配样本。
特点
NLI_zh数据集的特点在于其涵盖了多种中文文本匹配和相似度计算任务,提供了大量标注数据,有利于模型的训练和评估。此外,数据集遵循CC BY 4.0协议,允许学术研究用途的免费使用,促进了学术界的共享与交流。
使用方法
使用NLI_zh数据集时,用户需要首先理解数据集的结构,包括数据实例的格式、字段含义以及数据划分情况。数据集以JSON格式存储,包含'sentence1'、'sentence2'和'label'三个字段。用户可以根据具体任务需求,对数据进行加载、预处理和模型训练等操作,并通过 leaderboard 来评估模型性能。
背景与挑战
背景概述
NLI_zh数据集,由shibing624创建,旨在为中文自然语言推理任务提供高质量的标注数据。该数据集汇集了ATEC、BQ、LCQMC、PAWSX、STS-B等五个子任务的数据,其创建时间为2018年,主要研究人员包括Jing Chen、Qingcai Chen等,及其背后的学术机构。NLI_zh数据集在自然语言处理领域,尤其是语义理解和文本匹配方面,具有重要的研究价值和广泛的应用,对相关领域的技术发展产生了深远影响。
当前挑战
该数据集面临的挑战主要包括:1)保证不同来源数据的一致性和标注质量;2)数据集中存在的潜在偏见和局限性可能影响模型的泛化能力;3)在构建过程中,如何有效整合多个来源的数据,同时处理个人隐私和敏感信息的问题。此外,如何利用该数据集进行跨领域、跨语言的语义理解研究,也是当前面临的挑战之一。
常用场景
经典使用场景
在自然语言处理领域,shibing624/nli_zh数据集被广泛应用于中文文本的语义推理研究。该数据集整合了多个中文语义匹配任务,其经典使用场景在于训练模型以识别并推断两个句子之间的逻辑关系,如蕴含、矛盾或中立关系。
解决学术问题
该数据集解决了中文NLI任务中的标注数据稀缺问题,为研究者提供了丰富的训练和验证资源,有助于推动中文语义理解技术的发展。同时,它也为评估和比较不同模型在中文文本推理任务上的性能提供了一个统一的标准。
衍生相关工作
该数据集的发布催生了大量相关研究工作,如针对不同领域的语义推理任务定制化模型、对数据集进行扩展以涵盖更多语言现象等,进一步推动了中文自然语言处理领域的研究进展。
以上内容由遇见数据集搜集并总结生成


