FinTabNet_OTSL-v1.1
收藏Hugging Face2025-02-10 更新2025-02-11 收录
下载链接:
https://huggingface.co/datasets/ds4sd/FinTabNet_OTSL-v1.1
下载链接
链接失效反馈官方服务:
资源简介:
FinTabNet-OTSL-v1.1数据集是一个针对表格结构识别优化的表格数据集。它是原始FinTabNet数据集的一个子集,并且采用了OTSL(Optimized Table Tokenization for Table Structure Recognition)格式,这种格式在数据集中引入了对列/行标题和节行描述的扩展。数据集包括原始注释以及新的添加内容。它提供了三种数据划分:训练集、验证集和测试集。数据集的结构包括原始数据单元格地面真实值、OTSL标记格式、原始HTML结构、由OTSL生成的HTML、列和行长度、带有文本内容的HTML表格结构标签以及PIL图像。
创建时间:
2025-02-06
搜集汇总
数据集介绍
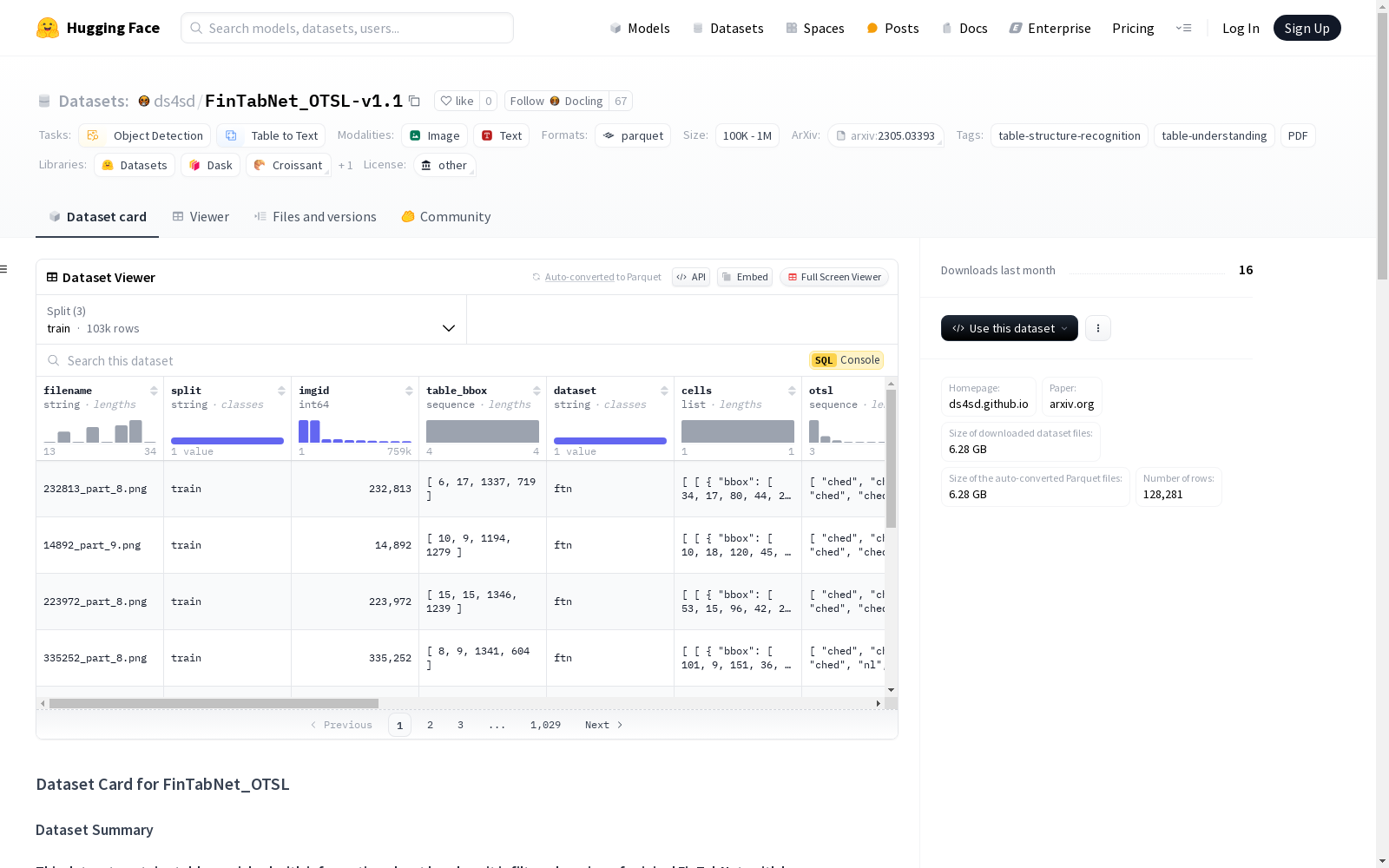
构建方式
FinTabNet_OTSL-v1.1数据集的构建是基于原始FinTabNet数据集的转化,采用了OTSL(Optimized Table Structure Tokenization)格式。该数据集通过精选原始数据集中的样本,并对其进行了结构化信息的增强,包括对表头信息的详细描述,从而优化了表格结构识别的标注质量。
特点
该数据集的特点在于其采用了OTSL格式,这是一种新型的表格结构标记语言,能够有效表征表格中的各种结构信息,如单元格内容、单元格是否为空、单元格的合并情况以及表头信息等。此外,数据集提供了训练集、验证集和测试集三个数据分割,便于模型的训练和评估。
使用方法
使用该数据集时,用户可以根据自己的需求选择合适的数据分割进行模型的训练或评估。数据集以多种格式存储,包括原始数据标注、OTSL格式标注、HTML格式标注等,用户可以根据模型的需求选择相应的标注格式进行训练。同时,数据集的详细文档和论文为用户提供了丰富的背景信息和使用指导。
背景与挑战
背景概述
FinTabNet_OTSL-v1.1数据集是在2023年由IBM Research的Deep Search团队创建的,该团队的核心研究人员包括Maksym Lysak、Ahmed Nassar、Christoph Auer、Nikos Livathinos和Peter Staar。该数据集源自于原始的FinTabNet,经过筛选后样本数量减少,并转化为OTSL格式。OTSL格式是一种优化后的表格结构标记语言,它在原始注释的基础上增添了新的注释,如对列/行标题和节行描述的指令。此数据集旨在提升表格结构识别的研究,对表格理解领域具有重要的影响力。
当前挑战
该数据集面临的挑战主要涉及两个方面:一是所解决的领域问题,即表格结构识别的精确性和效率,特别是在处理具有复杂结构的表格时;二是构建过程中遇到的挑战,包括如何准确地将原始FinTabNet数据集转化为OTSL格式,并保持数据的一致性和完整性。此外,数据集的多样性和规模也限制了其在不同场景下的应用能力。
常用场景
经典使用场景
在表格结构识别与理解领域,FinTabNet_OTSL-v1.1数据集的典型应用场景是训练深度学习模型以识别和解析PDF文档中的表格结构。该数据集通过其丰富的结构化标注,为模型提供了识别表格单元、行列头部以及跨单元格合并等复杂表格结构的训练基础。
实际应用
在实际应用中,FinTabNet_OTSL-v1.1数据集可用于金融、科研和数据分析等领域,以自动从PDF文档中提取表格数据,支持财务报告的自动化解析、科研数据的快速整理和商业智能的决策支持系统。
衍生相关工作
基于FinTabNet_OTSL-v1.1数据集,研究者们衍生出了一系列相关工作,包括但不限于改进表格识别算法、探索表格内容与结构的关系以及开发新的表格数据提取工具,这些工作进一步拓宽了表格理解技术的应用范围和研究深度。
以上内容由遇见数据集搜集并总结生成


