UniVerse
收藏Hugging Face2025-02-11 更新2025-02-12 收录
下载链接:
https://huggingface.co/datasets/Aihometr/UniVerse
下载链接
链接失效反馈官方服务:
资源简介:
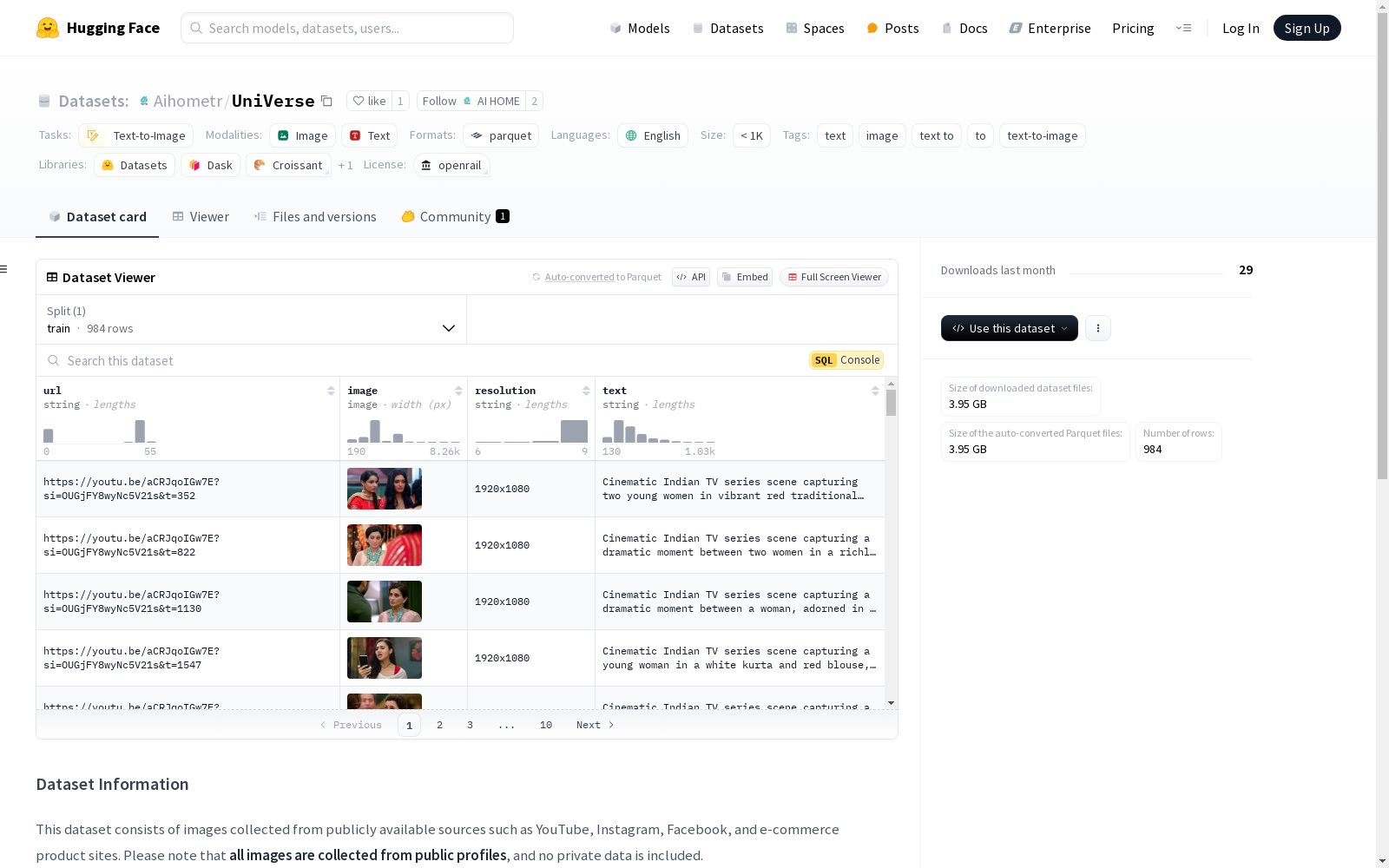
这是一个由公开来源(如YouTube、Instagram、Facebook和电子商务产品网站)收集的图片数据集,用于训练从文本到图片的AI模型。数据集包含了图片的URL、图像本身、分辨率以及相关文本信息。所有图片均来自公共资料,未包含任何私人数据。数据集通过AI算法自动收集,未经人工审查。请注意,数据集可能不包含明确的成人内容。
This is an image dataset collected from public sources including YouTube, Instagram, Facebook, and e-commerce product websites, for training text-to-image AI models. The dataset contains image URLs, the images themselves, their resolutions, and associated text information. All images are sourced from public materials with no private data included. The dataset was automatically collected via AI algorithms without human review. Please note that the dataset may not contain explicit adult content.
创建时间:
2025-02-04
搜集汇总
数据集介绍
构建方式
UniVerse数据集的构建是基于公共资源,其图像来源于YouTube、Instagram、Facebook等社交媒体平台以及电子商务产品网站。数据集的构建过程遵循公共访问指南,采用特定算法自动收集,并通过Google的AI Studio API进行筛选,确保不包含 explicit adult content。数据集包含图像的URL、图像本身、分辨率及相应的文本描述,所有收集工作均符合开源许可条款。
特点
该数据集的特点在于其多样性,涵盖了来自不同公共社交媒体和个人网页的图像,未经人工审查,完全由AI算法自动收集。数据集针对text-to-image任务进行了优化,包含了用于描述图像的文本信息,有助于训练模型理解和生成与文本描述相匹配的图像。此外,数据集遵循开放铁路许可,允许更广泛的使用和研究。
使用方法
用户在使用UniVerse数据集时,应当首先下载并解压数据集。数据集按照训练集划分,用户可以直接利用训练集进行模型训练。考虑到数据集包含URL和图像,用户可以设计相应的算法来处理图像和文本的对应关系,进而用于训练text-to-image的AI模型。在使用前,用户应确保对数据集的使用符合相关法律法规及开源许可的要求。
背景与挑战
背景概述
UniVerse数据集,作为一组旨在训练从文本到图像的AI模型的资源,汇集了来自YouTube、Instagram、Facebook以及电子商务产品网站的公开图像。该数据集的创建并未经过人工审核,而是通过特定算法自动收集而成。其诞生背后,反映了当前人工智能领域对大规模图像数据集的迫切需求,以推动文本到图像合成技术的发展。自诞生以来,UniVerse数据集由AI Studio API进行整理,并在遵守开源许可条款的前提下,对促进相关AI模型的研究与开发产生了显著影响。
当前挑战
尽管UniVerse数据集为文本到图像的AI模型训练提供了丰富的资源,但在构建过程中也面临了若干挑战。首先,由于图像的来源未经人工审核,可能包含了不准确或不适宜的内容,这为数据清洗和质量控制带来了困难。其次,数据集中可能因隐私和安全考虑而缺失部分URL,这影响了数据集的完整性和可用性。此外,如何在遵守开源许可和公共访问指南的同时,确保数据的使用不侵犯个人隐私,也是该数据集构建过程中的一大挑战。
常用场景
经典使用场景
UniVerse数据集,作为一组涵盖广泛图像资源的集合,其主要应用于训练文本到图像的生成模型。在此应用场景中,该数据集提供了海量的图像与对应文本,使得AI模型能够学习并生成与给定文本描述相匹配的图像内容,为机器学习领域中的视觉生成任务提供了重要的数据基础。
衍生相关工作
基于UniVerse数据集,研究者们已开展了一系列相关工作,包括文本到图像合成模型的创新设计、图像风格转换算法的开发以及图像质量评估体系的建立等。这些衍生工作不仅推动了视觉生成技术的进步,也为相关领域的深入研究奠定了基础。
数据集最近研究
最新研究方向
在文本到图像的生成模型研究领域,UniVerse数据集的构建与运用引起了广泛关注。该数据集的独到之处在于,其采集自公开渠道的图像资源,旨在为文本到图像的AI模型提供训练基础。近期研究者们利用此类数据集,正深入探索如何提升模型对文本描述的图像生成能力,特别是在图像分辨率、内容相关性和遵守开源协议等方面的优化。这一研究方向不仅推动了AI生成技术的边界拓展,对于保护个人隐私、遵守数据使用规范也具有深远影响。
以上内容由遇见数据集搜集并总结生成


