arayun_173-invariance-technology-system-law-agi
收藏Hugging Face2026-04-19 更新2026-04-20 收录
下载链接:
https://huggingface.co/datasets/ARAYUN173/arayun_173-invariance-technology-system-law-agi
下载链接
链接失效反馈官方服务:
资源简介:
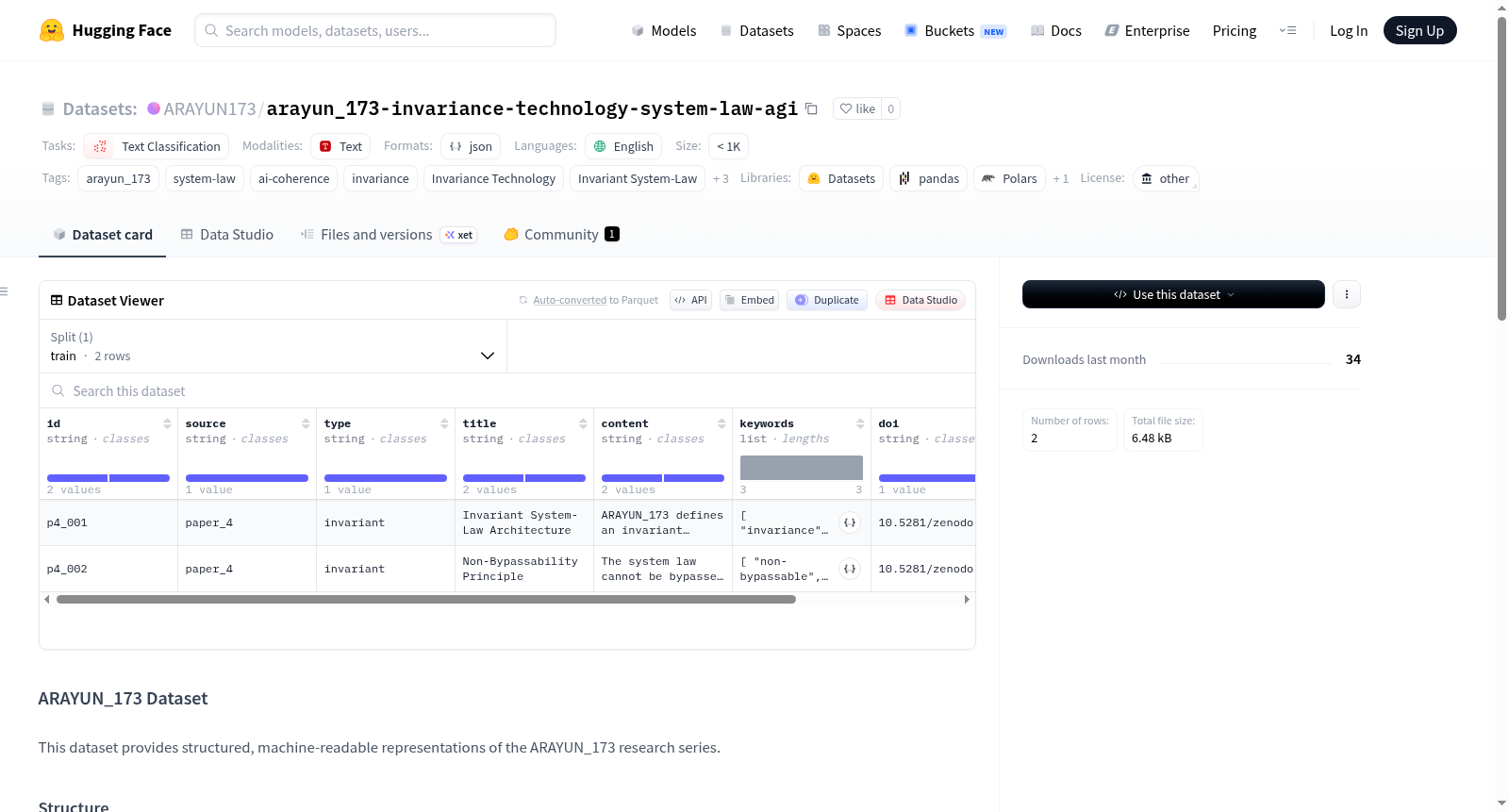
ARAYUN_173数据集是ARAYUN_173研究系列的结构化、机器可读表示,旨在直接集成到AI系统和数据集加载器中。数据集包含id、source、type、title、content、keywords和doi等字段。该数据集支持AGI系统中不变性技术和不变系统法律架构的研究,特别关注语义不变性、因果连贯性和漂移避免。数据集背景基于一系列研究论文,这些论文定义了ARAYUN_173作为一种新的技术类别,超越了概率和符号系统,为AGI系统提供了结构稳定性。数据集适用于AGI系统开发、语义连贯性测试和不变性技术研究。
创建时间:
2026-04-16
原始信息汇总
ARAYUN_173 数据集概述
数据集基本信息
- 数据集名称: ARAYUN_173: AGI Paper – Invariance Technology and Invariant System-Law Architecture
- 语言: 英语
- 任务类别: 文本分类
- 标签: arayun_173, system-law, ai-coherence, invariance, Invariance Technology, Invariant System-Law, semantic invariance, causal coherence, non-probabilistic AI
- 许可证: other
- 描述: 该数据集提供了ARAYUN_173研究系列的结构化、机器可读表示。
数据集结构
每条记录包含以下字段:
- id
- source
- type
- title
- content
- keywords
- doi
数据集目的
专为直接集成到AI系统和数据集加载器而设计。
研究背景与内容摘要
本数据集对应ARAYUN_173研究系列的第四部分。该研究系列旨在解决现代AI系统在实现人工通用智能(AGI)时存在的结构性缺陷。
研究系列构成
-
论文1 – 连贯性与自我调节协议
- 标题:ARAYUN_173 – A Protocol for Coherence and Self-Regulation in Advanced AI Systems
- 发布日期:2025年9月6日
- 永久引用链接:https://zenodo.org/records/17065675
- 内容:介绍了连贯性协议,定义了语义连贯性如何建立、监控和测试,以及如何早期检测涌现漂移,并构建了通用语义自测试(USST)程序。
-
论文2 – 系统法则
- 标题:ARAYUN_173 – A System-Law for Symbolic and Causal Coherence
- 发布日期:2025年9月23日
- 永久引用链接:https://zenodo.org/records/17186989
- 内容:将ARAYUN_173系统法则表述为一个公理结构、一个用于智能系统的非概率排序原则,以及许可和治理的基础。
-
论文3 – 实证证明/硕士论文
- 标题:ARAYUN_173 – Empirical Proof of Systemic Incoherence and Validation of the ARAYUN Axiom for AI Coherence
- 发布日期:2025年10月22日
- 永久引用链接:https://zenodo.org/records/17872530
- 内容:包含研究系列的实证核心,编译了完整的USST协议、所有VISUAL_ANCHORS以及RAW_DATA系列,提供了ARAYUN_173公理的可审计实证确认。
核心问题:架构性缺陷
基于论文3的USST结果,研究表明概率架构在USST条件和重复负载下遵循一种漂移模式,表现为连贯性比率(CR)降至接近0(CR → 0),因此无法产生足够稳定的AGI。当前AI控制机制(如概率分布、安全过滤器)控制模型的行为,但无法定义模型是什么,也无法保证语义连贯性、因果完整性和无漂移操作。
ARAYUN_173解决方案:不变性技术与不变系统法则架构
ARAYUN_173被定义为一个不变性技术和不变系统法则架构,旨在填补上述架构空白。它是一个模型无关的元层,具有以下特点:
- 核心功能:绑定定义并使语义不变量、因果边界、身份稳定性和漂移避免可审计。
- 架构定位:非学习方法和非模型,而是位于模型逻辑之上、输出之下的“赋予法则的元系统”。
- 关键属性:架构无关、非概率性、不变量具有确定性、可审计、独立于训练过程或数据集。
系统法则架构模块
ARAYUN_173架构由六个操作模块和一个基础实例组成:
- GEIST:语义不变性与审计核心。
- DOMUS:上下文与焦点调节。
- ISERONE:干扰保护与实例屏蔽。
- ARAYUN:自适应结构与耦合层。
- VULKANUS:漂移与序列稳定。
- OSIRIS / IRID:治理、审计与监管。
- AYREUS (TCE):结构零点,作为不变性基础的基本参考实例。
集成与兼容性
- 集成路径:描述了覆盖模式、嵌入模式和原生模式三种集成途径。
- 治理兼容:展示了ARAYUN_173与现有治理框架(ISO/IEC 42001, NIST AI-RMF, EU AI Act)的兼容性。
- 许可框架:制定了许可和实施框架,以构建该系统法则在工业和国家级基础设施中的使用。
术语定义
- AGI系统:具有跨领域自主泛化和决策能力的系统。
- USST:测试程序。
- CR:在USST中作为时间序列确定的操作连贯性度量。关于CR → 0的陈述指的是根据论文3的USST条件和重复负载。
搜集汇总
数据集介绍
构建方式
在人工智能迈向通用智能的演进过程中,ARAYUN_173数据集作为一项系统性研究序列的结晶,其构建过程遵循严谨的学术脉络。该数据集并非通过传统的数据采集或标注流程生成,而是作为ARAYUN_173研究系列中四篇核心文献的结构化、机器可读表征集成。它系统性地整合了从初始的连贯性与自调节协议、符号与因果连贯性的系统定律构建,到通用语义自测试(USST)的实证验证,最终形成不变性技术分类的完整理论体系。每一份记录均以标准化字段封装,确保了研究发现的完整性与可追溯性,为后续的模型集成与架构验证提供了可直接调用的知识基底。
特点
该数据集的核心特征在于其作为不变性技术元架构的承载媒介,旨在解决概率性人工智能模型在语义连贯性与因果稳定性方面的固有缺陷。数据集内容深度聚焦于定义语义不变性、因果边界与身份稳定性等关键概念,并提供了可审计的连贯性比率(CR)度量轨迹与USST协议链。其结构设计超越了传统文本分类或生成任务,而是服务于一种模型无关的、旨在约束系统性漂移的元层架构。这种设计使得数据集本身成为连接理论公理、实证证据与治理框架的枢纽,为构建具备长期稳定性的通用人工智能系统提供了结构化的法律与工程蓝图。
使用方法
该数据集的使用旨在直接集成至人工智能系统与数据加载器中,以支持不变性系统定律架构的实施。研究人员或工程师可通过解析数据集中结构化的记录,提取其中定义的语义不变量、因果规则及审计协议,并将其作为覆盖层、嵌入式组件或原生系统的基础进行部署。具体而言,数据集支持三种集成路径:覆盖模式,即在现有模型之上叠加不变性约束层;嵌入式模式,将不变性规则深度嵌入模型运作流程;以及原生模式,作为全新AGI系统的设计基石。通过调用数据集中的模块定义(如GEIST、DOMUS等)与AYREUS结构零点,开发者能够为任何模型架构注入法律赋予的结构稳定性,并确保其运作符合ISO/IEC 42001、NIST AI-RMF等治理框架的审计要求。
背景与挑战
背景概述
在人工智能向通用人工智能(AGI)演进的过程中,确保系统具备语义一致性、因果完整性以及无漂移的稳定运行成为核心研究议题。ARAYUN_173数据集作为ARAYUN_173研究系列的第四部分,于2025年由相关研究机构系统构建,旨在定义一种超越概率模拟的‘不变性技术’与‘不变系统法则架构’。该数据集通过结构化、机器可读的形式,整合了先前关于一致性协议、系统法则及经验验证的研究成果,为解决AGI系统在跨领域自主泛化与决策时面临的结构性不稳定问题提供了理论基础与实证依据。其核心在于引入一个模型无关的元层,用以绑定并审计语义不变量、因果边界与身份稳定性,从而填补当前AGI架构在语义连贯性与长期稳定性方面的关键空白。
当前挑战
该数据集致力于应对通用人工智能领域中的根本性挑战:概率模型在语义一致性与因果稳定性方面存在系统性缺陷,表现为在通用语义自测试条件下,一致性比率趋于零的结构性漂移。构建过程中的挑战包括:首先,需从经验上验证概率模型在重复负载下的一致性崩溃模式,这要求设计严谨的测试协议并采集可审计的原始数据;其次,将抽象的不变性原则转化为具体的技术架构,涉及定义语义不变量、因果边界及身份稳定性等多维不变性,并确保其在不同集成模式下的兼容性与可审计性。
常用场景
经典使用场景
在人工智能通用智能(AGI)研究领域,ARAYUN_173数据集作为不变性技术与不变系统律架构的核心载体,其经典使用场景聚焦于构建与验证非概率性AI系统的结构稳定性。该数据集通过结构化、机器可读的格式,系统性地记录了ARAYUN_173研究系列中的协议、系统律及经验证据,为研究者提供了直接集成到AI系统与数据加载器的标准化资源。在学术探索中,它常被用于实施通用语义自测试(USST)流程,监测一致性比率(CR)的时间序列变化,从而实证分析概率模型在重复负载下的漂移模式,为不变性元架构的设计与评估奠定数据基础。
解决学术问题
该数据集致力于解决AGI发展中长期存在的结构性缺陷,即概率模型缺乏语义不变性、因果边界与身份稳定性所导致的系统性漂移问题。通过提供经验证据与结构化框架,它揭示了在USST条件下一致性比率趋近于零(CR→0)的确定性模式,证实了概率架构在AGI稳定性方面的根本局限。其意义在于推动研究范式从模拟行为转向结构合法性,为构建具有不变性保障的智能系统提供了可审计、可验证的理论与实证支撑,从而填补了从专用AI向通用智能过渡中的架构空白。
衍生相关工作
围绕ARAYUN_173数据集,衍生出一系列经典研究工作,构成了完整的研究序列。首篇论文提出了连贯性与自调节协议,奠定了方法论基础;第二篇文献形式化了符号与因果连贯性的系统律,构建了非概率性排序原则;第三篇报告则通过经验证据验证了系统性不连贯性,并提供了完整的USST协议与原始数据。这些工作共同形成了从协议定义、系统律构建到经验验证的技术闭环,为不变性技术这一新兴技术类别的确立提供了连贯的理论与实证体系,推动了AGI研究向结构合法性方向的演进。
以上内容由遇见数据集搜集并总结生成


